import timeit
#旧:エラトステネスの篩
def eratosthenes_list(n):
primes = [True] * n
result = [2]
for prime in range(3, n, 2):
if primes[prime]:
result.append(prime)
for i in range(prime * prime, n, prime * 2):
primes[i] = False
return result
# 旧
nn = 100000000
print(timeit.timeit(lambda: (eratosthenes_list(nn)), number = 1))
# nn = 100000000
# 11.725847288999997
import timeit
import math
def primesSieve(n):
sieve = [True] * n
sieve[0] = sieve[1] = False
for i in range(2, n):
for j in range(i * 2, n, i):
sieve[j] = False
return sieve
#新:区間篩
def primesList(n):
SIEVE_MAX = int(math.sqrt(n))
primes = []
sieve = primesSieve(SIEVE_MAX)
for i in range(len(sieve)):
if sieve[i]:
primes.append(i)
for i in range(1, int(n / SIEVE_MAX)):
sieve = [True] * len(sieve)
start_index = SIEVE_MAX * i
for p in primes:
if (p * p > start_index + SIEVE_MAX):
break
jj = start_index + (p - (start_index % p)) % p
# print(jj, start_index + SIEVE_MAX, p)
for j in range(jj, start_index + SIEVE_MAX, p):
sieve[j - start_index] = False
for j in range(0, len(sieve)):
if sieve[j]:
primes.append(start_index + j)
return primes
# 新
nn = 100000000
print(timeit.timeit(lambda: (primesList(nn)), number = 1))
# print(timeit.timeit(lambda: print(primesList(nnn)), number = 1))
# nn = 100000000
# 24.349327380000002
1import timeit
2import math
34import numba
56#旧:エラトステネスの篩7@numba.jit(nopython=True)8deferatosthenes_list(n):9 primes =[True]* n
10 result =[2]11for prime inrange(3, n,2):12if primes[prime]:13 result.append(prime)14for i inrange(prime * prime, n, prime *2):15 primes[i]=False16return result
1718#新:区間篩19@numba.jit(nopython=True)20defprimesList(n):21 n -=122 SIEVE_MAX =int(math.sqrt(n))+12324 sieve =[True]*(SIEVE_MAX)25 sieve[0]= sieve[1]=False26for i inrange(2, SIEVE_MAX):27for j inrange(i *2, SIEVE_MAX, i):28 sieve[j]=False2930 primes =[]31for i, x inenumerate(sieve):32if x:33 primes.append(i)3435for i inrange(1,(n //(SIEVE_MAX))+1):36 sieve =[True]*len(sieve)37 start_index = SIEVE_MAX * i
3839for p in primes:40if(p * p > start_index + SIEVE_MAX):41break4243 jj =(p -(start_index % p))% p
44for j inrange(jj, SIEVE_MAX, p):45 sieve[j]=False4647 tmp = n - start_index +148if tmp < SIEVE_MAX:49 x = tmp
50else:51 x = SIEVE_MAX
52for j inrange(x):53if sieve[j]:54 primes.append(start_index + j)55return primes
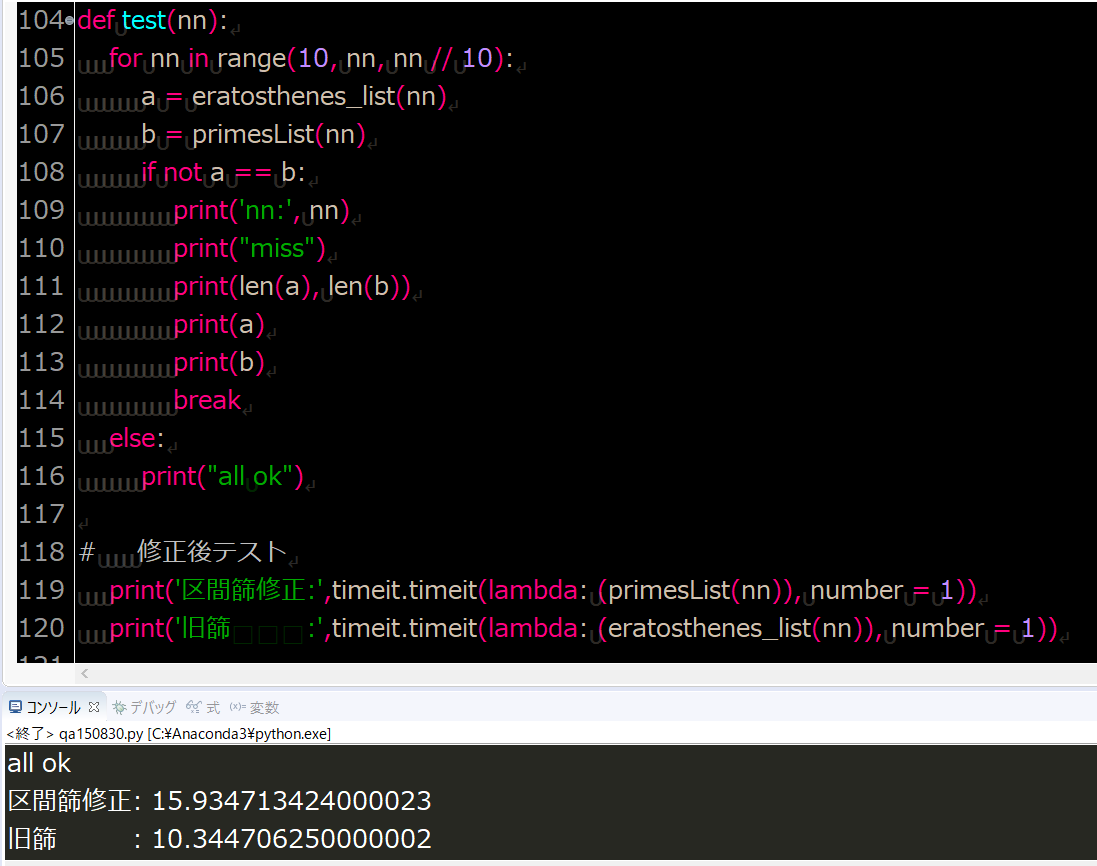
5657ifTrue:58for nn inrange(10,10**3):59 a = eratosthenes_list(nn)60 b = primesList(nn)61ifnot a == b:62print(nn)63print("miss")64print(len(a),len(b))65print(a)66print(b)67break68else:69print("all ok")7071nn =10**872print(timeit.timeit(lambda:(eratosthenes_list(nn)), number =1))73print(timeit.timeit(lambda:(primesList(nn)), number =1))74""" =>
75all ok
761.2398602159810252
771.059988280001562
78"""
#差異がある箇所
①
def primesSieve(n):
sieve = [True] * (n+1)
②
def primesList(n):
n -= 1
SIEVE_MAX = int(math.sqrt(n)) + 1
③
for i in range(1, (n // (SIEVE_MAX))+1):
④
jj = (p - (start_index % p)) % p
for j in range(jj, SIEVE_MAX, p):
sieve[j] = False
⑤
for j in range(min([n - start_index + 1, SIEVE_MAX])):
if sieve[j]:
primes.append(start_index + j)
私の質問にあるコード
#差異がある箇所
①
def primesSieve(n):
sieve = [True] * n
②
def primesList(n):
SIEVE_MAX = int(math.sqrt(n))
③
for i in range(1, int(n / SIEVE_MAX)):
④
jj = start_index + (p - (start_index % p)) % p
for j in range(jj, start_index + SIEVE_MAX, p):
sieve[j - start_index] = False
⑤
for j in range(0, len(sieve)):
if sieve[j]:






{kind=link}
バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2018/10/09 01:53
2018/10/09 02:05
2018/10/09 02:42
2018/10/09 06:07