
###前提・実現したいこと
こんにちは、
機械学習の画像認識について伺いたいことがあり、質問させていただきます。
CNNという手法で複数画像を一つの入力として読み込ませることは可能でしょうか?
また、可能であればどのようにすれば複数画像を一つの入力とすることができるのでしょうか?
単純に下記のコード(参考サイトより引用)の入力サイズ(※1)や一つ目の畳み込み層のチャネル数(※2)を変更するだけで良いのでしょうか?
普通の入力画像(カラー)の1枚の場合はRGBの3チャネルを入力としていますが、今回は白黒画像複数枚(画像1枚を入力1チャネル)として学習を行いたいと考えております。
class Alex(chainer.Chain): """Single-GPU AlexNet without partition toward the channel axis.""" insize = 227 (※1) def __init__(self): super(Alex, self).__init__( conv1=L.Convolution2D(3, 96, 11, stride=4), (※2) conv2=L.Convolution2D(96, 256, 5, pad=2), conv3=L.Convolution2D(256, 384, 3, pad=1), conv4=L.Convolution2D(384, 384, 3, pad=1), conv5=L.Convolution2D(384, 256, 3, pad=1), fc6=L.Linear(9216, 4096), fc7=L.Linear(4096, 4096), fc8=L.Linear(4096, 1000), ) self.train = True def clear(self): self.loss = None self.accuracy = None def __call__(self, x, t): self.clear() h = F.max_pooling_2d(F.relu( F.local_response_normalization(self.conv1(x))), 3, stride=2) h = F.max_pooling_2d(F.relu( F.local_response_normalization(self.conv2(h))), 3, stride=2) h = F.relu(self.conv3(h)) h = F.relu(self.conv4(h)) h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2) h = F.dropout(F.relu(self.fc6(h)), train=self.train) h = F.dropout(F.relu(self.fc7(h)), train=self.train) h = self.fc8(h) self.loss = F.softmax_cross_entropy(h, t) self.accuracy = F.accuracy(h, t) return self.loss
こうした場合に、どのように画像を入力として与えれば良いのかわからない状況です。
機械学習、CNNの根本的な理解が全く足りておらず申し訳有りませんが、どなたかご回答の方よろしくお願いいたします。
###参考サイト
Qiita「Convolutional Neural Networkを実装する」
Chainerによる畳み込みニューラルネットワークの実装
###補足情報(言語/FW/ツール等のバージョンなど)
CNNは下記の情報処理学会主催の「SamuraiCoding」というゲームAIの大会で用いようと考えております
Samurai Coding
具体的にはスプラトゥーンのような3対3のターン制の陣取りゲームでゲーム画面は以下のような感じです。
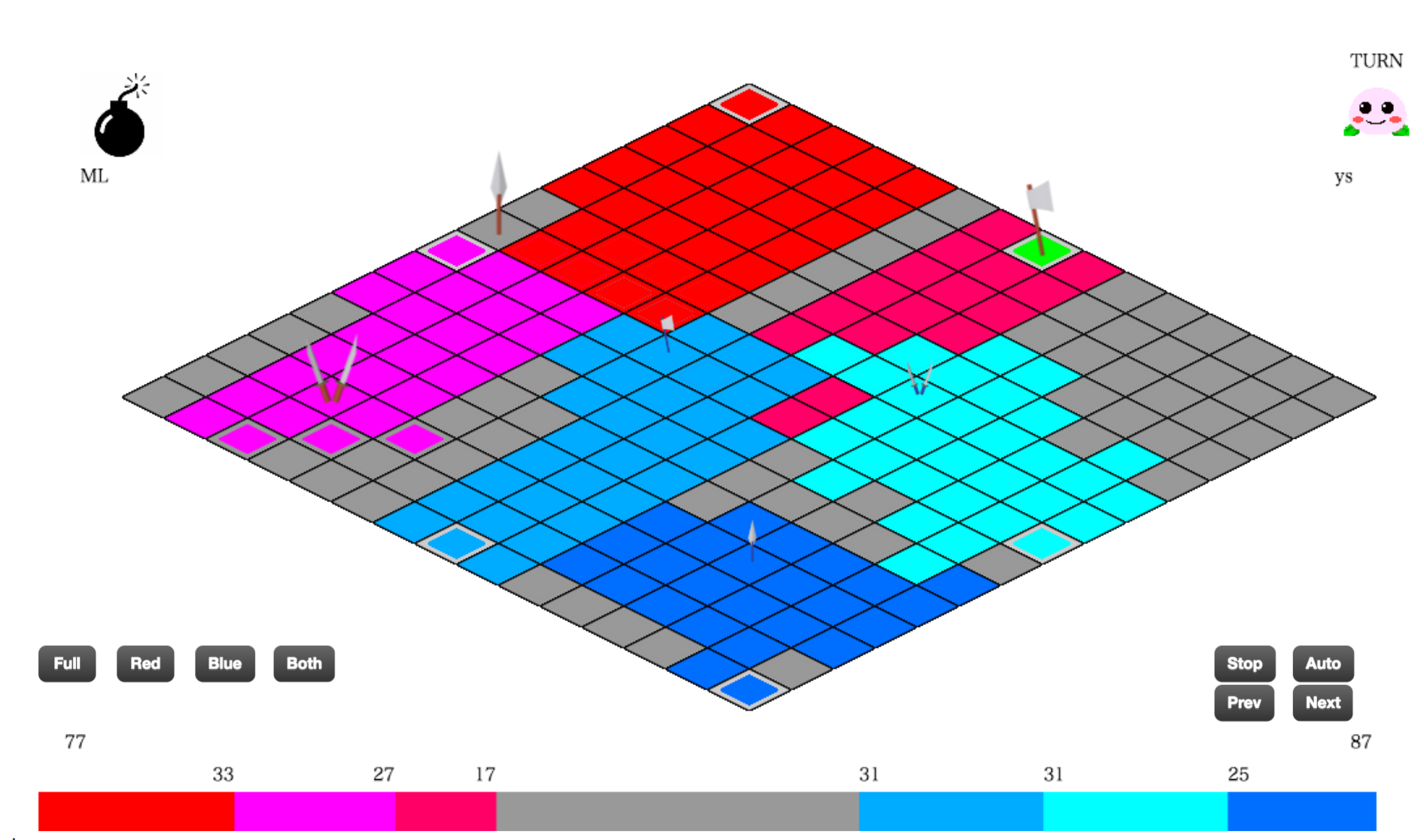
実際の対戦では自分のターンに下のようなゲーム情報が渡され、キャラクターの行動を決定し出力するプログラムを書くというものです。

ゲームには視界があり自分チーム3人分の視界が得られますが視界外の情報は得られません

そこで大量のログデータからCNNを用いて、敵の位置の予測や次の行動の選択を行おうと考えております。


