
Q.1 課題を整理させてください
> 以前に、似たような解析を行った際はインプットのパラメータ1つに対して、アウトプットのパラメータも1つだった
y=f(input1)
> input1-3に任意の値が与えられたときにLUTを参照し、最もらしいoutputを計算する
y=f(input1,input2,input3)
ということですか?
Q.2 LUTで近傍値を探らないとまずい感じですか?LUTを模倣する回帰式があれば片付く話に見えるためです。
---
「California Housing」と検索するとたぶん幸せになれます。
実現したいこと
LUTを用いて複数のパラメータからアウトプットを計算したいです
前提
Pythonを用いてデータ解析を行っています。その中で構築したいプログラムがあり、うまくいかず困っています。
input1 input2 input3 output
0.175992 0.289561 0.424524 0.01
0.163683 0.296413 0.407614 0.2
0.152489 0.303623 0.393387 0.4
0.143289 0.308857 0.38057 0.6
0.13626 0.312844 0.367287 0.8
0.130837 0.316597 0.357121 1
0.125503 0.319049 0.347518 1.2
0.120385 0.32324 0.33906 1.4
0.116954 0.324452 0.330172 1.6
0.114296 0.32506 0.3231 1.8
0.110625 0.327111 0.316316 2
0.107602 0.329085 0.310861 2.2
0.104512 0.330155 0.304826 2.4
0.101533 0.330934 0.299364 2.6
0.099053 0.333527 0.294442 2.8
0.097248 0.334364 0.287901 3
上記は私が使用しているLUTの一部を抽出したものです。
4つのパラメータで構成されており、左からinput1、 input2 、input3、outputです。
やりたいこととしてはinput1-3に任意の値が与えられたときにLUTを参照し、最もらしいoutputを計算するというものです。
ある数理モデルを何百パターンも動かした結果をまとめたものでして、そのインプットのパラメータをinput、モデルから出力される値をoutputとしています。
モデルを毎回動かすととても時間がかかってしまうので、事前にモデルを動かしたで結果をまとめたものを処理を簡略化する用途でLUTと呼ばせてもらっています。
input1 output
0.175992 0.01
0.163683 0.2
0.152489 0.4
0.143289 0.6
0.13626 0.8
0.130837 1
0.125503 1.2
0.120385 1.4
0.116954 1.6
0.114296 1.8
0.110625 2
0.107602 2.2
0.104512 2.4
0.101533 2.6
0.099053 2.8
0.097248 3
以前に、似たような解析を行った際はインプットのパラメータ1つに対して、アウトプットのパラメータも1つだったので、任意の値が与えられたときにインプットの最も近い値2つを調べ、そこに対応するアウトプットで補間を行い値を計算していました。
しかし、今回のようにインプットのパラメータが増えた際にどのように計算すれば良いのか分からず、困っています。
始めはそれぞれにインプットに対してアウトプットを補間して3つ計算して、それの平均をとることを考えたのですが、少し違う気がしています。
何かこのようなときに用いるアルゴリズムのようなものがあれば教えて頂きたいです。
以下、調べながら書いてみたコードです。(うまくいっていませんが、、)
該当のソースコード
Python
1def calculate_output(input1, input2, input3, lut): 2 # 入力値がLUTの範囲外の場合、最も近い値を使用する 3 if input1 < lut[0][0]: 4 input1 = lut[0][0] 5 elif input1 > lut[-1][0]: 6 input1 = lut[-1][0] 7 8 if input2 < lut[0][1]: 9 input2 = lut[0][1] 10 elif input2 > lut[-1][1]: 11 input2 = lut[-1][1] 12 13 if input3 < lut[0][2]: 14 input3 = lut[0][2] 15 elif input3 > lut[-1][2]: 16 input3 = lut[-1][2] 17 18 # LUT内で入力値に最も近い4つの点を見つける 19 idx = 0 20 for i in range(len(lut)): 21 if lut[i][0] >= input1 and lut[i][1] >= input2 and lut[i][2] >= input3: 22 idx = i 23 break 24 25 # 線形補間してoutputを計算する 26 x0, y0, z0, output0 = lut[idx] 27 x1, y1, z1, output1 = lut[idx + 1] 28 29 output = output0 + (input1 - x0) * (output1 - output0) / (x1 - x0) 30 output += (input2 - y0) * (output1 - output0) / (y1 - y0) 31 output += (input3 - z0) * (output1 - output0) / (z1 - z0) 32 33 return output 34 35# テスト用の入力値 36input1 = 0.163 37input2 = 0.297 38input3 = 0.402 39 40# ルックアップテーブルの定義 41lut = [ 42 [0.175992, 0.289561, 0.424524, 0.01], 43 [0.163683, 0.296413, 0.407614, 0.2], 44 [0.152489, 0.303623, 0.393387, 0.4], 45 [0.143289, 0.308857, 0.38057, 0.6], 46 [0.13626, 0.312844, 0.367287, 0.8], 47 [0.130837, 0.316597, 0.357121, 1], 48 [0.125503, 0.319049, 0.347518, 1.2], 49 [0.120385, 0.32324, 0.33906, 1.4], 50 [0.116954, 0.324452, 0.330172, 1.6], 51 [0.114296, 0.32506, 0.3231, 1.8], 52 [0.110625, 0.327111, 0.316316, 2], 53 [0.107602, 0.329085, 0.310861, 2.2], 54 [0.104512, 0.330155, 0.304826, 2.4], 55 [0.101533, 0.330934, 0.299364, 2.6], 56 [0.099053, 0.333527, 0.294442, 2.8], 57 [0.097248, 0.334364, 0.287901, 3], 58 59] 60 61# 出力の計算 62result_output = calculate_output(input1, input2, input3, lut) 63print("計算結果:", result_output)
試したこと
上記のコードだと、1つのインプットに対して他のインプットも影響を受けており、うまくいっていません。
説明に何か伝わりづらい点があればおっしゃって頂きたいです。
補足情報(FW/ツールのバージョンなど)
Jupyter labを使用しています。
以下7/10追記です、処理の時間などから多次元の補間をやることにしました。
いろいろ調べながらやっていますが、うまくいっていません。
以下のようなことをしています。
output = np.array([0.01, 0.2, 0.4, 0.6, 0.8, 1., 1.2, 1.4, 1.6, 1.8, 2.,
2.2, 2.4, 2.6, 2.8, 3., 3.2, 3.4, 3.6, 3.8, 4., 4.2,
4.4, 4.6, 4.8, 5., 5.2, 5.4, 5.6, 5.8, 6.])
input1= np.array([0.176463, 0.152728, 0.138598, 0.128642, 0.123007, 0.117635,
0.112536, 0.110502, 0.108924, 0.106747, 0.105962, 0.10582,
0.104823, 0.10449, 0.103251, 0.103633, 0.102974, 0.103084,
0.103043, 0.102879, 0.102681, 0.102527, 0.102997, 0.102664,
0.102451, 0.102072, 0.102249, 0.101777, 0.102069, 0.101809,
0.101998])
input2 = np.array([0.272927, 0.277758, 0.281626, 0.283859, 0.28659, 0.2867,
0.287287, 0.289614, 0.289179, 0.289283, 0.291206, 0.289775,
0.290282, 0.288257, 0.291728, 0.289183, 0.29019, 0.290279,
0.28848, 0.288594, 0.288264, 0.287192, 0.29105, 0.290441,
0.289335, 0.290651, 0.29004, 0.28723, 0.290567, 0.288062,
0.2894])
input3 = np.array([0.386387, 0.363491, 0.341545, 0.323909, 0.311452, 0.302448,
0.292989, 0.285284, 0.280991, 0.276571, 0.27309, 0.269776,
0.269617, 0.26874, 0.266365, 0.265985, 0.263457, 0.262764,
0.261464, 0.260748, 0.260258, 0.258956, 0.257731, 0.259482,
0.258395, 0.25853, 0.257665, 0.257651, 0.257651, 0.257812,
0.257578])
上記の読み込む数値は一例として載せています。
#インプットとして使う値を指定
input1_test = 0.117
input2_test = 0.286
input3_test = 0.303
①LinearNDInterpolator(コメントで教えていただきました)
from scipy.interpolate import LinearNDInterpolator
#3次元データ点を作成
points = np.array([input1,input2,input3]).T
#LinearNDInterpolatorを使用して3次元補間関数を作成
interp_func = LinearNDInterpolator(points, output)
#インプット値に対応するLAIを補間により推定
output_test = interp_func(input1_test, input2_test, input3_test)
print("LAI:", output_test)
実行結果ですが、nanという結果が出ました。補間の関数の範囲外などでこのようになることもあるみたいですが、3つのインプットはinput1-3の範囲内になっています。input2がきれいな増加や減少関数になっていないことがいけないのでしょうか。
②from scipy.interpolate import griddata,interpn,RegularGridInterpolator
似たような方法として見つけたのでやってみました。
#3次元データ点を作成
points = (input1,input2,input3)
#インプットとして使う値を指定
input1_test = 0.117
input2_test = 0.286
input3_test = 0.303
interpolator = RegularGridInterpolator(points, output, method='linear')
#インプット値に対応するLAIを多次元補間により推定
input_values = np.array([[input1_test, input2_test, input3_test]])
output_test = interpolator(input_values)
print("LAI:", output_test)
実行結果ですが、ValueError: There are 3 point arrays, but values has 1 dimensions
というエラーがでました。やりたい目的上、次元を減らすことはできない??とよくわからないでいます。
どちらの方法でも何かアドバイスをいただければ嬉しいです。
コメントありがとうございます。
Q.1 課題を整理させてください
> 以前に、似たような解析を行った際はインプットのパラメータ1つに対して、アウトプットのパラメータも1つだった
y=f(input1)
> input1-3に任意の値が与えられたときにLUTを参照し、最もらしいoutputを計算する
y=f(input1,input2,input3)
ということですか?
そうです!その認識で大丈夫です!
Q.2 LUTで近傍値を探らないとまずい感じですか?LUTを模倣する回帰式があれば片付く話に見えるためです。
絶対にそうというわけでく、LUTを用いて最もらしい値が求められれば大丈夫と思っています。
---
「California Housing」と検索するとたぶん幸せになれます。
ありがとうございます!調べさせていただきます。もしまた不明点などありましたら、質問させていただけたら幸いです。
具体的にinputとoutputはどのような意味合いの値でしょうか?
検索するかぎりほぼ映像分野でしか用いられない「LUT」という単語から
入力のRGB(なりHSV)値から色温度のようなものを求めたいのかと推測しています。
また、その解析において正解(教師)データは持っていますか?
もしなければ「最もらしい」と客観的に判断できないと思われるので。
can110さん コメントありがとうございます。
実はある数理モデルを何百パターンも動かした結果をまとめたものでして、そのインプットのパラメータをinput、モデルから出力される値をoutputとしています。
モデルを毎回動かすととても時間がかかってしまうので、事前にモデルを動かしたで結果をまとめたものを処理を簡略化する用途でLUTと呼ばせてもらっています。
3次元の補間でいいのならscipyのLinearNDInterpolatorが使えるのではないでしょうか。
https://docs.scipy.org/doc/scipy/reference/generated/scipy.interpolate.LinearNDInterpolator.html
> 実はある数理モデルを何百パターンも動かした結果をまとめたものでして、そのインプットのパラメータをinput、モデルから出力される値をoutputとしています。
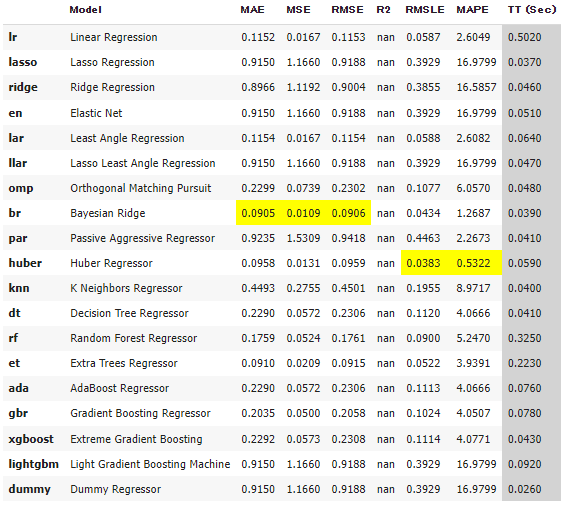
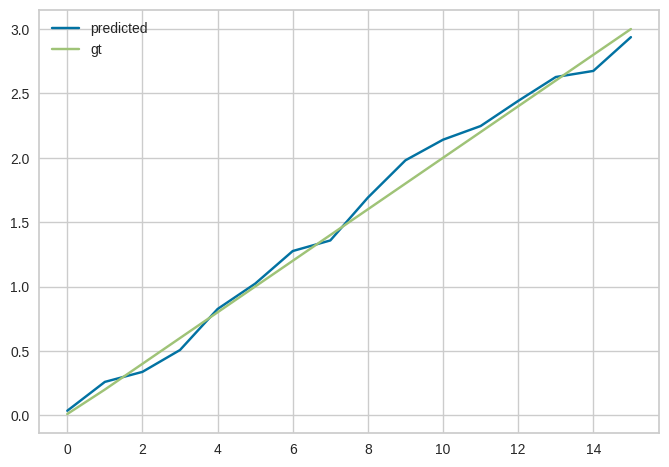
詳しいことを確認しないで書いてしまいますが、「何百パターンの生の数理モデル」をまとめずにそのままPyCaretに突っ込んだ方が精度が高そうです。
個々の数理モデルが一般的にいう「データ数n」に相当するはずで、今の状態だと「n=16」ですが、これが「n=数百」に上がるため(平均化によって潰れてしまったデータを救えるなどして)フィット性能が高くなる可能性があります。
> ある数理モデルを何百パターンも動かした結果をまとめたものでして、そのインプットのパラメータをinput、モデルから出力される値をoutputとしています。
モデルを毎回動かすととても時間がかかってしまうので、事前にモデルを動かしたで結果をまとめたものを処理を簡略化する用途でLUT
は、質問に追記した方がいいと思います
> モデルを毎回動かすととても時間がかかってしまうので、事前にモデルを動かしたで結果をまとめたものを処理を簡略化
サロゲートモデル
でググったら参考になるかも(ならないかも)
jbpb0さん
ありがとうございます。サロゲートモデル調べてみます、質問にも追記させていただきました。
bsdfanさん
ありがとうございます。3次元の補間なんてできるのですね!!
リンクのサイト見させていただきます。
bsdfanさんが紹介したscipyのLinearNDInterpolatorはたしか線形補間なので、input1〜3にLUTのどれかの行と全く同じ値を指定した場合に、outputもLUTのその行と全く同じ値になると思います
線形補間以外も含めて、補間とか内挿(とか補外とか外挿)と呼ばれるものは、たいていそうです
http://www.yamamo10.jp/yamamoto/comp/Python/library/SciPy/interpolate/index.php
一方、fourteenlengthさんが紹介したもののような機械学習系の回帰とか近似と呼ばれるものは、input1〜3にLUTのどれかの行と全く同じ値を指定した場合に、outputはたいていLUTのその行と全く同じ値にはなりません
かなり近い値になるかもしれないけど、まあまあ違う値になるかもしれません
データの傾向と、選んだ機械学習の手法(と設定)の組み合わせによります
(私が紹介したサロゲートモデルも、たいていはこちらです)
> input1-3に任意の値が与えられたときにLUTを参照し、最もらしいoutputを計算
の際に、たまたまLUTのどれかの行の組み合わせにかなり近いinput1〜3の値を与えた場合に、outputもLUTのその行の値にかなり近い値を「必ず」計算してほしいのなら、補間の方が向いてると思います
LUTの各行の値の組み合わせにどれくらい忠実に計算してほしいか(多少の違いは許容できるか)で、手法を選ぶといいと思います
https://tajimarobotics.com/trajectory-interpolation-and-approximation/
jbpb0さん
どうもありがとうございます。手法の選び方もいろいろ考えてみます。
コメントいただいた皆様
補間の方法を試してみていますが、少々うまくいっておりません。
編集して追記しましたので、アドバイスいただけましたら幸いです。
LinearNDInterpolator は内挿しかできないです。たぶんデータがある点の四面体で囲める内側だけです。
二次元で言うなら、(0, 0), (1, 1), (3, 4) にデータがあるときの、(2, 2) は最大と最小の範囲的には入っていますが、三角形の外側になるのでダメみたいなイメージです。
RegularGridInterpolator は、元データが格子点にそろっている場合に使えます。(今回のケースにはあてはまりません)
外挿もできるものとなると scipy.interpolate.RBFInterpolator ですが、この手の計算で外挿でちゃんとした値が得られるのかと言われると、怪しいように感じます。
bsdfan様
ありがとうございます。二次元での説明私でも理解できました、ありがとうございます。
次元の数が増えると、1:1のような単純な考えではいけないのですね。
RBFInterpolatorもまた新しいやり方を教えてくださり、ありがとうございます。
結果として、値を出力することができました。ただ、結果の精度が怪しいとのことなんですね、、
いろいろなパターンで結果を出力してみて、ダメそうであればまた他の方法をやってみたいと思います。
> 結果として、値を出力することができました。ただ、結果の精度が怪しいとのことなんですね
外挿は怪しいので、できるだけやらない方がいいです
外挿にならず補間になるように、後で計算すると思われる範囲が全て網羅されるように、予め数理モデルで計算しておくことですね
> モデルを毎回動かすととても時間がかかってしまう
とのことですが、補間の元データを計算するのは一回だけなので、少々時間がかかっても、必要な範囲が全て網羅されるようにしましょう
jbpb0様
アドバイスありがとうございます。いくつか値を出してみたのですが、たまに値が極端に大きくなることがあるので、たしかに怪しいかもしれません、、
内挿の方が精度は高いみたいですね、ありがとうございます。
この質問は回帰というよりも分類に近そうな文をどこかで見た気がしたのですが、思いだせず見つけられず…。そこでふと思ったのですが、回帰(浮動小数点で言い当てたい)ではなく分類(どのカテゴリか当てたい)だとしたらPyCaretのClassificationでも対応できますね。見当違いだったらごめんなさい。
fourteenlength様
ありがとうございます。無知で申し訳ないのですが、カテゴリといいますとおおよその値のようなイメージなのでしょうか。
分類問題ていうとlist = [1.1,2.1,3.2,3.9,4.8,6.0,7.2]みたいなグループがあって、回帰だと「バチっと数値を当てに行きます」が、分類だと「●番目のグループ(値)に近いです」を当てに行きます。回帰の方は可能な限り同じ線(直線也曲線なり)の上に答えを探しに行きますが、分類だと(無理やりこじつけてでも)グループに当てはめに行きます。
用途次第ですが、先のPyCaretはどちらも対応できます。
fourteenlength様
ありがとうございます!どちらにも対応できるPyCaretは便利ですね、、
回答1件
あなたの回答
tips
プレビュー


