
回答編集履歴
3
answer
CHANGED
|
@@ -8,9 +8,11 @@
|
|
|
8
8
|
|
|
9
9
|
こんなのいちいち使い分けてられねーよ、という場合には、[PyCaret](https://github.com/pycaret/pycaret)を検討ください。データを流し込むだけで後は自動的にポン付けできるレベルの回帰結果とモデルを吐き出してくれます。おススメです。
|
|
10
10
|
|
|
11
|
+
以下、Train/Testの仕分け等**やっていません**が、PyCaretの例
|
|
11
12
|
---
|
|
12
13
|
|
|
14
|
+
|
|
13
|
-
|
|
15
|
+
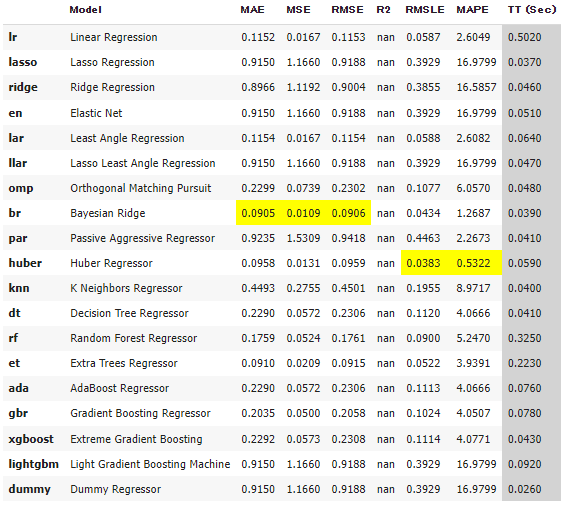
私なら、ですがHuber regressorを選びます。
|
|
14
16
|
---
|
|
15
17
|
|
|
16
18
|
|
2
ちゃんとでーたをあつかっていないがこうかいはしていない
answer
CHANGED
|
@@ -8,14 +8,16 @@
|
|
|
8
8
|
|
|
9
9
|
こんなのいちいち使い分けてられねーよ、という場合には、[PyCaret](https://github.com/pycaret/pycaret)を検討ください。データを流し込むだけで後は自動的にポン付けできるレベルの回帰結果とモデルを吐き出してくれます。おススメです。
|
|
10
10
|
|
|
11
|
-
PyCaretの例:私なら、ですがHuber regressorを選びます。
|
|
12
11
|
---
|
|
13
12
|
|
|
13
|
+
Train/Testの仕分け等**やっていません**が、PyCaretの例:私なら、ですがHuber regressorを選びます。
|
|
14
|
+
---
|
|
15
|
+
|
|
14
16
|

|
|
15
|
-
|
|
17
|
+
|
|
16
18
|
```Python3
|
|
17
19
|
import pycaret
|
|
18
|
-
from pycaret.regression import setup, compare_models
|
|
20
|
+
from pycaret.regression import setup, compare_models,predict_model
|
|
19
21
|
import pandas as pd
|
|
20
22
|
|
|
21
23
|
lut = [
|
|
@@ -41,4 +43,10 @@
|
|
|
41
43
|
setup(data = df_lut, target = "target")
|
|
42
44
|
|
|
43
45
|
best_model = compare_models()
|
|
46
|
+
|
|
47
|
+
pred =best_model.predict(df_lut[["param0","param1","param2"]])
|
|
48
|
+
gt = df_lut["target"].to_numpy()
|
|
49
|
+
|
|
50
|
+
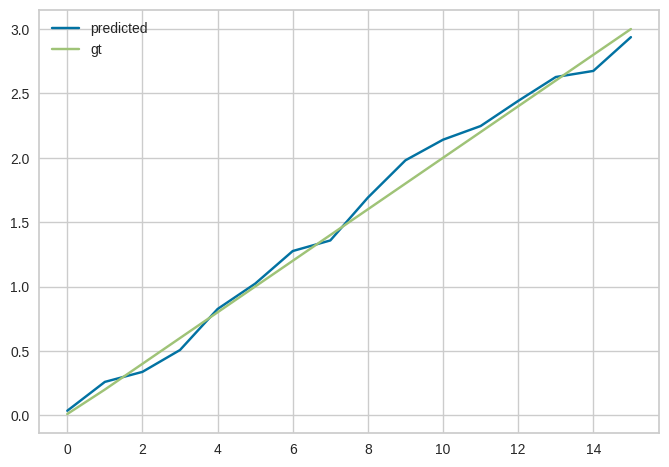
df_check = pd.DataFrame([pred,gt]).T.set_axis(["predicted","gt"],axis=1)
|
|
51
|
+
df_check.plot()
|
|
44
52
|
```
|
1
ぷろっとしたよん
answer
CHANGED
|
@@ -6,4 +6,39 @@
|
|
|
6
6
|
|
|
7
7
|
非線形でないと思ったほどLUTに一致しない、というのであれば、SVRみたいな非線形な方法が良さそうです。LGBMみたいなのもありかもしれませんが、データが疎だとガジガジな回帰になるのでお勧めできません。
|
|
8
8
|
|
|
9
|
-
こんなのいちいち使い分けてられねーよ、という場合には、[PyCaret](https://github.com/pycaret/pycaret)を検討ください。データを流し込むだけで後は自動的にポン付けできるレベルの回帰結果とモデルを吐き出してくれます。おススメです。
|
|
9
|
+
こんなのいちいち使い分けてられねーよ、という場合には、[PyCaret](https://github.com/pycaret/pycaret)を検討ください。データを流し込むだけで後は自動的にポン付けできるレベルの回帰結果とモデルを吐き出してくれます。おススメです。
|
|
10
|
+
|
|
11
|
+
PyCaretの例:私なら、ですがHuber regressorを選びます。
|
|
12
|
+
---
|
|
13
|
+
|
|
14
|
+

|
|
15
|
+
|
|
16
|
+
```Python3
|
|
17
|
+
import pycaret
|
|
18
|
+
from pycaret.regression import setup, compare_models
|
|
19
|
+
import pandas as pd
|
|
20
|
+
|
|
21
|
+
lut = [
|
|
22
|
+
[0.175992, 0.289561, 0.424524, 0.01],
|
|
23
|
+
[0.163683, 0.296413, 0.407614, 0.2],
|
|
24
|
+
[0.152489, 0.303623, 0.393387, 0.4],
|
|
25
|
+
[0.143289, 0.308857, 0.38057, 0.6],
|
|
26
|
+
[0.13626, 0.312844, 0.367287, 0.8],
|
|
27
|
+
[0.130837, 0.316597, 0.357121, 1],
|
|
28
|
+
[0.125503, 0.319049, 0.347518, 1.2],
|
|
29
|
+
[0.120385, 0.32324, 0.33906, 1.4],
|
|
30
|
+
[0.116954, 0.324452, 0.330172, 1.6],
|
|
31
|
+
[0.114296, 0.32506, 0.3231, 1.8],
|
|
32
|
+
[0.110625, 0.327111, 0.316316, 2],
|
|
33
|
+
[0.107602, 0.329085, 0.310861, 2.2],
|
|
34
|
+
[0.104512, 0.330155, 0.304826, 2.4],
|
|
35
|
+
[0.101533, 0.330934, 0.299364, 2.6],
|
|
36
|
+
[0.099053, 0.333527, 0.294442, 2.8],
|
|
37
|
+
[0.097248, 0.334364, 0.287901, 3],]
|
|
38
|
+
|
|
39
|
+
df_lut = pd.DataFrame(lut,columns=["param0","param1","param2","target"])
|
|
40
|
+
|
|
41
|
+
setup(data = df_lut, target = "target")
|
|
42
|
+
|
|
43
|
+
best_model = compare_models()
|
|
44
|
+
```
|