
学習率が高すぎるのでは? learning rateを小さくして、再トライしてみてはどうでしょう。
前提・実現したいこと
現在、以下のコードを参考にしてデータセットを置き換えて学習を行っています。
trainingはうまく進んでいるように見えますが、validationはうまくいっていません。元コードとの変更点はデータセットの変更を通すために少し変更した程度です。
いろいろ調べましたが、似たような例は見つからず困っている次第です。
よろしくお願いします。
使用しているデータセットは2048*4096,training:10400枚,validation:373枚です。(training dataは水増ししています。)
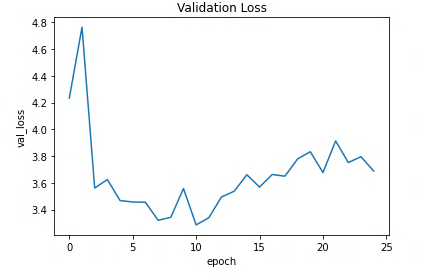
追記:とりあえず学習を進めてみているので何かあったら報告します。
・ReduceLP0nPlateauを追加して学習した結果、Epoch3以降val lossが上昇
・学習率を下げて学習した結果、地道にlossが下がるもののlossが4ほどで停滞する

以下の画像はデータを水増しする前の結果です。
水増し方法(わかりずらかったら申し訳ありません。)

数値では、過学習してるっぽく見えます
その確認のために、今回の学習が終わったら、次は
> training dataは水増ししています。
を止めてみたら、いかがでしょうか
もしそれで、trainingとvalidationの数値が近づくなら、水増ししたものがvalidation dataとかけ離れたものになっていて、それを頑張って学習した結果過学習してしまって、validation dataでは精度出ない、的なことになってるのかも
> validation loss が上昇している原因を知りたい。
> trainingはうまく進んでいるように見えますが、validationはうまくいっていません。
一般的には過学習の傾向を示していると思いますが、
> いろいろ調べましたが、似たような例は見つからず困っている次第です。
ということは何か特別な処理をされているのでしょうか?
coffeebarさん
ご回答ありがとうございます。
書くのを忘れていましたが、lrを0.001から0.0001にして行っています。どちらにせよ学習はうまくいっていないので、もうひと段階下げることを検討してみます。
ありがとうございます。
jbpb0さん
ご回答ありがとうございます。
水増しする前は1000枚くらいでval accが20%位までは上がっていたので、ご回答通りのことが起こっているかもしれません。
貴重なご意見ありがとうございます。
meg_さん
ご回答ありがとうございます。
やはり過学習と考えるのが一般的のようですね。ほぼ初めての機械学習なので過学習について詳しく調べようと思います。
特別な処理をしているわけではないですが、調べたところtrainingも上がっていなかったり、学習の途中からvalidation lossが上昇している例が多かったので、自身に起こっていることはそれとは違うものであると考えておりました。
貴重なご意見ありがとうございます。
> training:10400枚
> 水増しする前は1000枚くらい
trainingデータの9割くらいが水増しデータですよね
もし水増しがうまくいってない(validationデータと全然違うものが多数生成されてる)のなら、validationデータでは最初から精度出ないことは有り得ます
ただ、trainingデータの1割くらいはvalidationデータと似てるはずだから、もう少しなんとかなりそうという気もします (気がするだけ)
とりあえず、HRCo4さんも回答に書いてるように、水増しデータがどんなのか(適切な水増しになってるのか)を確認したらいいと思います
jbpb0さん
ご回答ありがとうございます。
水増しデータを見てみましたが、特に問題はなさそうに見えます。
水増し方法はランダムに画像の左側を切り取り、右側にくっつけるという方法です。
なんだか水増し方法自体があまり良くない気もしてきました。
> 水増し方法はランダムに画像の左側を切り取り、右側にくっつけるという方法
以下の二点が気になります
A. 元々の画像の右端か左端に見切れてる人が写ってる場合、水増しで両端がくっついて、結果半分だけの人みたいなのができてしまう
B. 元々の画像の、水増しで切ったところに人が写ってると、水増し後画像ではその人は両端に見切れて配置される
上記の内のB.は、画像の見切れてる人もセグメンテーションしたいのなら、問題無いように思います
水増し前の元々の画像にも、もしかしたら見切れてる人のセグメンテーション教師データが含まれてるかもしれないし
一方A.は、現実には有り得ない画像を生成してることになりますよね
そういうのがtrainingデータの水増し分9割のどれくらいを占めてるのかは分かりませんが、結構多いなら、そのような現実に有り得ない画像を頑張って学習して、結果過学習してしまうと、validationデータにはそんなの無いので精度出ないかも
jbpb0さん
ご回答ありがとうございます。
画像に関してですが、現在パノラマ画像をデータセットとして使っており、0度から360度までが移っている画像です。
例えば左端が0度で右端が360度であるとしたら切り取った左端と右端をくっつけても、もともとつながっている位置関係にあるため見切れるというようなことは起こっていません。
念のため水増しデータをいくつか見てみましたが、どこで切り取ったかわからないくらい違和感はありませんでした。
なるほど、360°つながってる(円筒を内側から見てるような)画像を、どこか一ヶ所で切って展開した画像になっていて、元々は同じ画像から切る場所がいろいろ違う画像を作ってるのですか
それなら、画像としては問題無いでしょうね
ただ、それだと実質同じ(切るところだけ違う)画像が10枚くらいあることになるような気がしますので、水増ししてもあまりバリエーションは増えてないような
jbpb0さん
ご回答ありがとうございます。
たしかにバリエーションは増えませんね。
バリエーションを増やすには画像の都合上、回転や拡大はvalidationのデータと離れてしまいそうなのでHRCo4さんがおっしゃられている明度や彩度の変換をやってみようと考えています。
回答1件
あなたの回答
tips
プレビュー


