
前提・実現したいこと
kerasのlstmを用いて,将来の交通量予測を行うモデルを構築しているのですが,
作成したモデルが意図した予測を行っているかがわかりません。
モデルでは,30分先の交通量を予測するようにしているのですが,
問題点として,
(1)明らかに精度が高い(本当に意図した時間先を予測しているのか?)
(2)予測したい時間を変えたとき明らかに不自然な予測結果が得られる
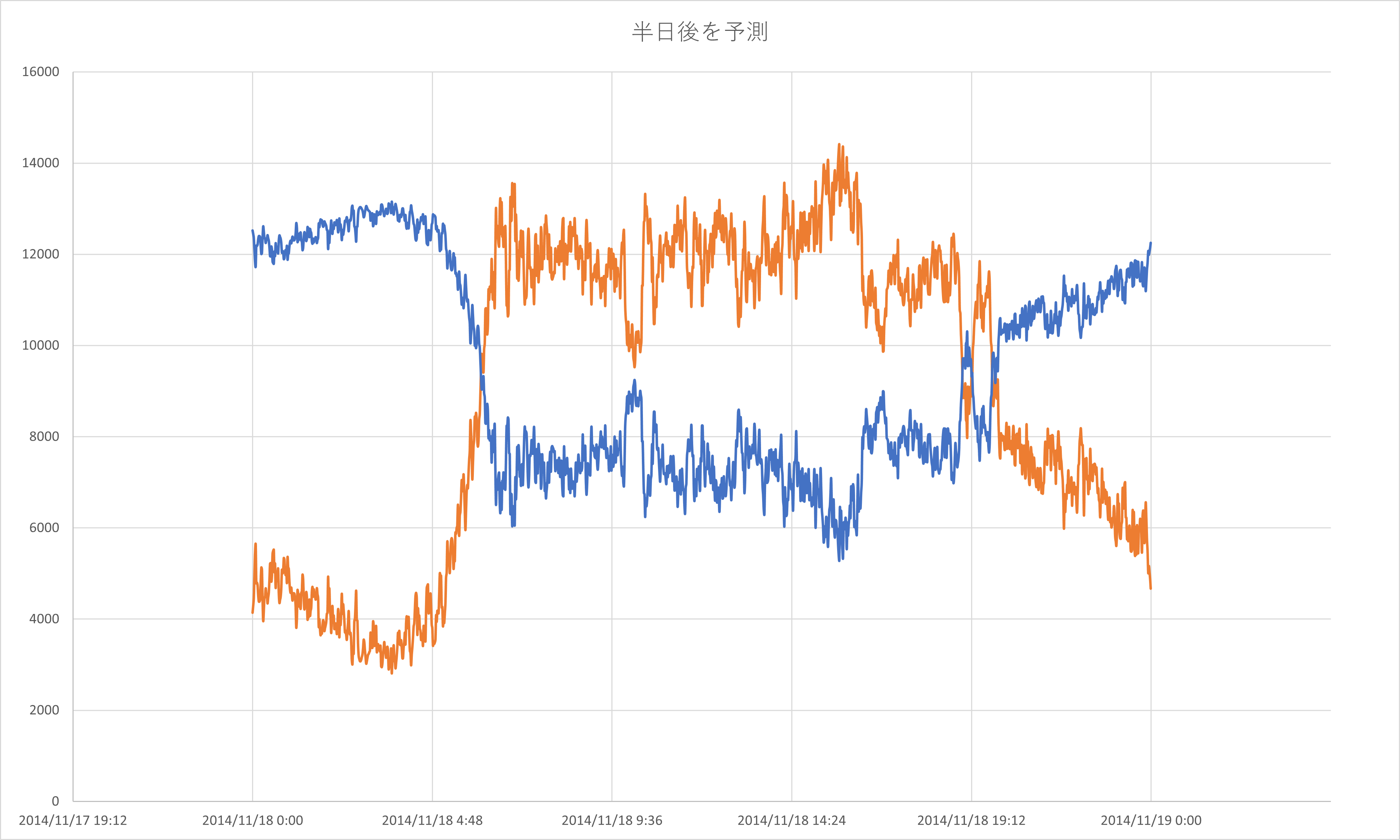
特に12時間先のデータを用いて予測した際は予測結果(下記図2枚目)が不自然になり,
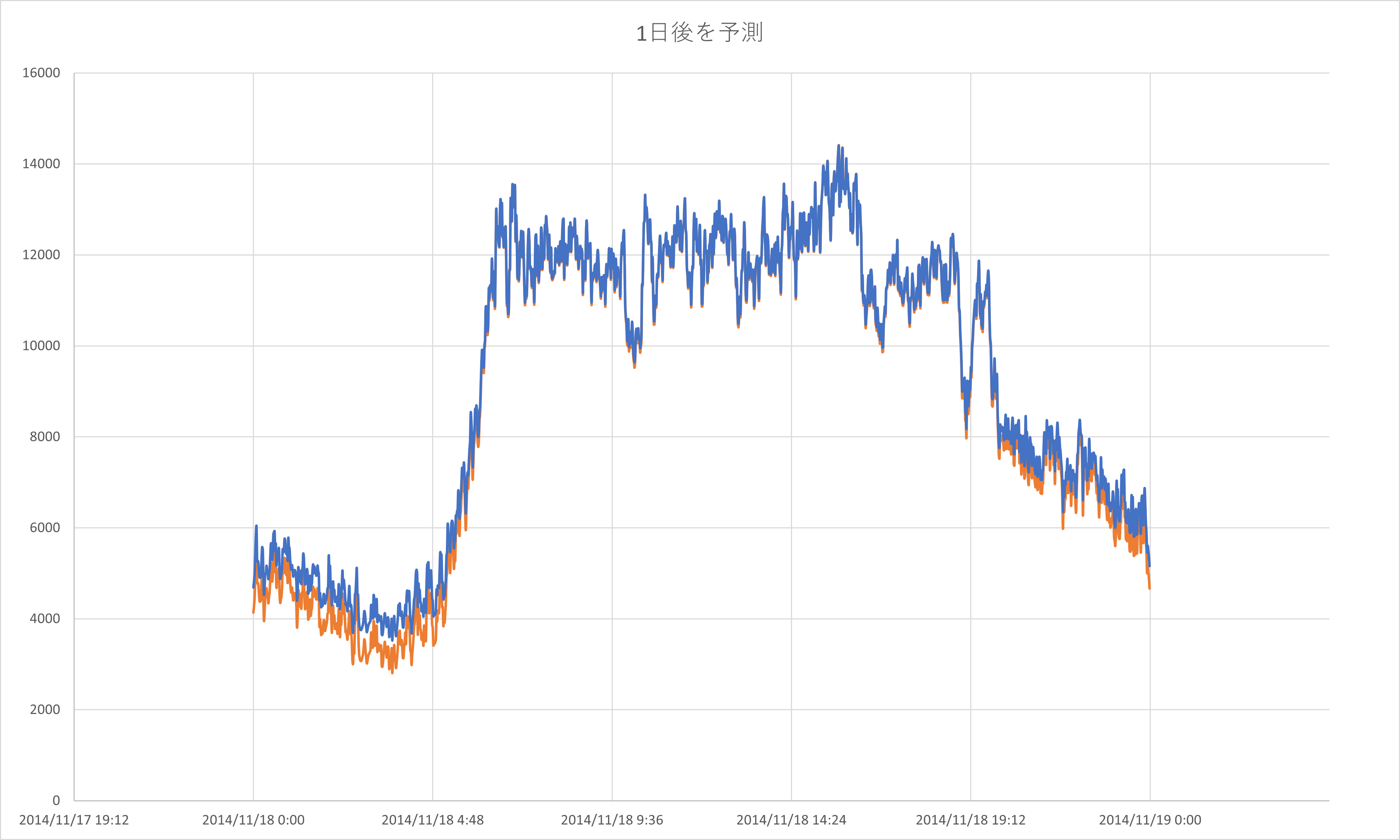
1日先のデータでの予測結果は(下記図3枚目)逆に精度が高すぎるといった結果になりました。
私の作成したプログラムが正しく意図した将来を予測できているのか判断がつきません。
追記
下記図に関して,
青線が予測値
オレンジ線が観測値
になります。
また,ソースコードにおける「pred_time」が予測したい時間先になっており,
pred_time=30で,正解データが30分先の値であることを意味しています。
この意味として,ある1時点のデータを学習データ,その時点から30分後の時点のデータを正解データとして
損失関数を小さくするような学習をしてほしいと考えています。
再追記
使用している交通量のデータは,
100日間1分間隔(144000行)で記録された時系列のデータになります。
該当のソースコード
Python
1#1変数のみを入力 2 3import os 4import numpy as np 5import pandas as pd 6import matplotlib.pyplot as plt 7 8import_file = 'C:/Users/temp/Desktop/week_day1.csv' #データファイルの読み込み 9 10#事前の決定 11test_rate = 0.2 #データの分割割合 12pred_time = 720 #何分先を予測するかの決定(データ:1分間隔/1時間先を予測:pred_time = 60) 13time = 1440 14 15#データのインポート 16df = pd.read_csv(import_file) 17 18#必要なデータの抽出 19date = df.iloc[:,0].values #データの1列目を抽出 20Pt = df.iloc[:, 3:4].values #データの4列目を抽出 21 22 23#データの分割 24from sklearn.model_selection import train_test_split 25date_1, date_2 = train_test_split(date, test_size=test_rate, shuffle=False) 26train, test = train_test_split(Pt,test_size=test_rate,shuffle=False) 27 28 29#教師ありデータに変換 30x_train = train[:-pred_time] #データの下からpred_time分を削って学習データに 31t_train = train[pred_time:] #データの上からpred_time分を削って正解データに 32x_test = test[:-pred_time] #データの下からpred_time分を削ってテストデータに 33t_test = test[pred_time:] #データの上からpred_time分を削って正解データに 34 35 36 37#2次元配列へ変換 38x_train = x_train.reshape(-1, 1) 39t_train = t_train.reshape(-1, 1) 40x_test = x_test .reshape(-1, 1) 41t_test = t_test .reshape(-1, 1) 42 43 44#0-1への正規化の定義 45from sklearn.preprocessing import MinMaxScaler 46 47def scale(x_train, x_test , t_train, t_test ): 48 49 # change type 50 x_train = x_train.astype(np.float32) 51 x_test = x_test .astype(np.float32) 52 t_train = t_train.astype(np.float32) 53 t_test = t_test .astype(np.float32) 54 55 # scale inputs 56 sclr = MinMaxScaler() 57 x_train = sclr.fit_transform(x_train) 58 x_test = sclr.transform(x_test ) 59 t_train = sclr.transform(t_train) 60 t_test = sclr.transform(t_test ) 61 62 return x_train, x_test , t_train, t_test , sclr 63 64#正規化 65x_train, x_test , t_train, t_test , sclr = scale(x_train, x_test , t_train, t_test ) 66 67#成形(change shape) 68x_train = np.reshape(x_train.astype("float32"), (x_train.shape[0],1,x_train.shape[1] )) 69x_test = np.reshape(x_test .astype("float32"), (x_test .shape[0],1,x_test .shape[1] )) 70 71 72#各種インポート 73import keras 74from keras.models import Sequential, Model 75from keras.layers import Input, Dense, Activation, LSTM 76from keras.callbacks import EarlyStopping 77import math 78from sklearn.metrics import mean_squared_error, mean_absolute_error 79 80 81#モデルの定義 82Inputs = Input(shape = (x_train.shape[1], x_train.shape[2]), dtype='float32') 83lstm = LSTM(128)(Inputs) 84Outputs = Dense(1, activation='linear')(lstm) 85 86model = Model(inputs=[Inputs], outputs=[Outputs]) 87model.compile(loss='mean_squared_error', optimizer='adam', metrics=['mean_squared_error']) 88 89es = EarlyStopping(monitor='val_loss', 90 patience=5, 91 verbose=1) 92 93#モデルの学習 94history = model.fit(x_train, t_train, epochs=10, batch_size=256, verbose=1, shuffle=False, validation_split = 0.1, callbacks=[es]) 95 96 97#予測 98pred = model.predict(x_test ) #予測値 99obs = t_test #観測値 100 101 102#正規化を戻す 103obs_unscale=sclr.inverse_transform(obs) 104pred_unscale=sclr.inverse_transform(pred) 105 106 107#モデルの評価指標 108RMSE = math.sqrt(mean_squared_error(pred_unscale,obs_unscale)) 109ape = mean_absolute_error(pred_unscale, obs_unscale) 110MAPE =ape * 100/len(obs_unscale) 111print("RMSE=",RMSE) 112print("MAPE=",MAPE) 113 114 115#配列 → DataFrame 116dfd = pd.DataFrame(date_2) #日付 117dfp = pd.DataFrame(pred_unscale) #予測値 118dfo = pd.DataFrame(obs_unscale) #観測値 119 120 121#最初の1日を削除 122dfd = dfd[int(time):] 123dfp = dfp[int(time):] 124dfo = dfo[int(time - pred_time):] 125 126 127#predとobsのDataFrameを一つにまとめる 128df = pd.concat([dfd, dfp, dfo], axis=1) #axis=1で横方向に連結 129 130 131#DataFrameの行名の変更 132df.columns = ['date_time', 'Pt_pred', 'Pt_obs'] 133 134 135#csvに書き出し 136df.to_csv('C:/Users/temp/Desktop/5_30_output.csv')

試したこと
ハイパーパラメータの調整,スケーリングの調整,予測先の変更等を試してみましたが,うまくいきません。
コード自体が見当はずれなのでしょうか?
回答1件
あなたの回答
tips
プレビュー



2020/10/22 00:59
2020/10/22 10:10
2020/10/23 02:25 編集
2020/10/24 04:43 編集
2020/10/24 05:10
2020/10/24 05:30
2020/10/24 05:41
2020/10/24 05:48
2020/10/24 09:24
2020/10/24 11:51
2020/10/24 12:38