




参考までにお聞きしたいのですが、このモデルは画像認識ですか?それとも時系列の学習でしょうか。
もし、画像認識の場合、なぜLSTMを使っているのか興味があります。
MinistをLSTMで学習させたいのですが
特徴量の入力について疑問があります。
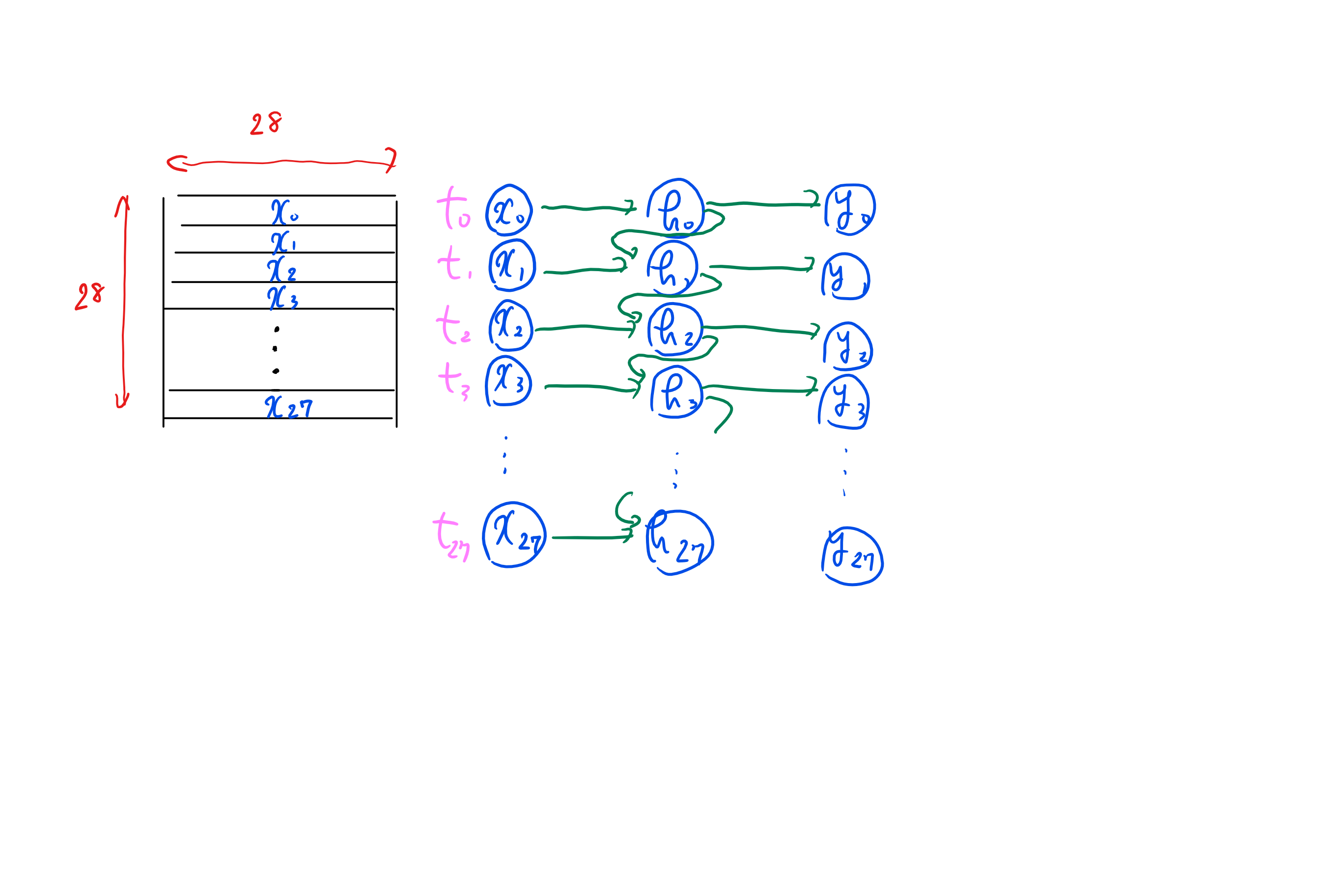
28*28のサイズで28の一行目(模式図のt1)から二行目(t2)というデータを読み込ませたいのですが
ディープニュートラルネットワークの設計としては中間層h0がh1に入るという認識でいいでしょうか?
時系列データとして扱っているのでt1からt2に行くh27とh28が(t2からt3も)つながっていないという認識なのですが・・・
あってますでしょうか?
模式図↓
具体的なコード
python
1from keras.utils import np_utils # keras.utilsからnp_utilsをインポート 2from keras.datasets import mnist # MNISTデータセットをインポート 3 4# MNISTデータセットの読み込み 5(x_trains, y_trains), (x_tests, y_tests) = mnist.load_data() 6 7# 訓練データ 8x_trains = x_trains.astype('float32') # float32型に変換 9x_trains /= 255 # 0から1.0の範囲に変換 10# 正解ラベルをワンホット表現に変換 11correct = 10 # 正解ラベルの数 12y_trains = np_utils.to_categorical(y_trains, correct) 13 14# テストデータ 15x_tests = x_tests.astype('float32') # float32型に変換 16x_tests /= 255 # 0から1.0の範囲に変換 17# 正解ラベルをワンホット表現に変換 18y_tests = np_utils.to_categorical(y_tests, correct) 19 20print(x_trains.shape) # 訓練データの形状を出力 21print(x_tests.shape) # テストデータの形状を出力 22 23# RNNの構築 24from keras.models import Sequential 25from keras.layers import InputLayer, Dense 26from keras.layers.recurrent import LSTM 27from keras import optimizers,regularizers 28 29# Sequentialオブジェクトを生成 30model = Sequential() 31 32## 入力層 33# 入力データの形状は(28, 28) 34model.add( 35 InputLayer(input_shape=(28,28)) 36 ) 37 38## 中間層 39# LSTMブロック(ユニット数=128) 40weight_decay = 1e-4 # ハイパーパラメーター 41model.add(LSTM(units=128, dropout=0.25, return_sequences=True)) 42model.add(LSTM(units=128, dropout=0.25, return_sequences=True)) 43model.add(LSTM(units=128, dropout=0.25, return_sequences=False, 44 kernel_regularizer=regularizers.l2(weight_decay)) # 正則化 45) 46 47## 出力層 48model.add( 49 Dense(units=10, # 出力層のニューロン数は10 50 activation='softmax') # 活性化はシグモイド関数 51 ) 52 53# Squentialオブジェクをコンパイル 54model.compile( 55 loss='categorical_crossentropy', # 誤差関数はクロスエントロピー 56 optimizer=optimizers.Adam(), # Adamオプティマイザー 57 metrics=['accuracy'] # 学習評価として正解率を指定 58 ) 59 60model.summary() # RNNのサマリ(概要)を出力 61 62# 学習を開始 63history = model.fit(x_trains, y_trains, # 訓練データ、正解ラベル 64 batch_size=100, # ミニバッチのサイズ 65 epochs=10, # 学習回数 66 verbose=1, # 学習の進捗状況を出力する 67 validation_data=( # テストデータの指定 68 x_tests, y_tests) 69 ) 70 71# 損失と正解率をグラフにする 72 73import matplotlib.pyplot as plt 74 75# プロット図のサイズを設定 76plt.figure(figsize=(15, 6)) 77# プロット図を縮小して図の間のスペースを空ける 78plt.subplots_adjust(wspace=0.2) 79 80# 1×2のグリッドの左(1,2,1)の領域にプロット 81plt.subplot(1, 2, 1) 82# 訓練データの損失(誤り率)をプロット 83plt.plot(history.history['loss'], 84 label='training', 85 color='black') 86# テストデータの損失(誤り率)をプロット 87plt.plot(history.history['val_loss'], 88 label='test', 89 color='red') 90plt.ylim(0, 1) # y軸の範囲 91plt.legend() # 凡例を表示 92plt.grid() # グリッド表示 93plt.xlabel('epoch') # x軸ラベル 94plt.ylabel('loss') # y軸ラベル 95 96# 1×2のグリッドの右(1,2,21)の領域にプロット 97plt.subplot(1, 2, 2) 98# 訓練データの正解率をプロット 99plt.plot(history.history['acc'], 100 label='training', 101 color='black') 102# テストデータの正解率をプロット 103plt.plot(history.history['val_acc'], 104 label='test', 105 color='red') 106plt.ylim(0.5, 1) # y軸の範囲 107plt.legend() # 凡例を表示 108plt.grid() # グリッド表示 109plt.xlabel('epoch') # x軸ラベル 110plt.ylabel('acc') # y軸ラベル 111plt.show()
画像認識です。
ディープラーニングの理論と実装という本を参考にLSTMを理解しようとしたのですが
コードを追ってたところ肝心の入力周りのところがkerasの内部処理になっておりイメージがつかめなかったため質問させていただきました。
畳み込みニューラルネットワークを使わずに、敢えて再帰型ニューラルネットワークで学習に挑戦しているということは、論文などを発表されるためでしょうか。
そういうわけではないですね
再帰型ニューラルネットワークは、入力(時刻 t) に対して、出力(時刻 t+1) を予測するというものなのですが、このプログラムは、入力に画像データ、教師データにそのラベルを設定してfit させようとしています。(CNNを理解された上でLSTMモデルを独自に研究されているのであれば、申し訳ありませんが私の理解を超えています)
今回の目的としては厳密なモデル選択をしているのではなくMnistでとりあえずLSTMを適用しようという方針です。その際にピクセル単位で相互に関連性を持ったと仮定しており、その前提のモデルがあっているかどうかということを質問しているという流れです。厳密性にこだわっていないので有識者の人から見ると怒られるかもしれませんがそれはそれこれはこれでお願いします。
回答2件
あなたの回答
tips
プレビュー


