
質問の説明と書き方の違いだけで、同じように感じるのですが。
「テーブルの拡張」はあるのでしょうか? 拡張でなく、再作成ではないでしょうか?
元々のデータをそのまま、キーにすると、テーブルサイズが大きくなるので、ハッシュテーブルで、テーブルサイズを小さくし、検索を容易にするのでは無かったですか? そのためには、テーブルサイズの検討が重要と聞きます。
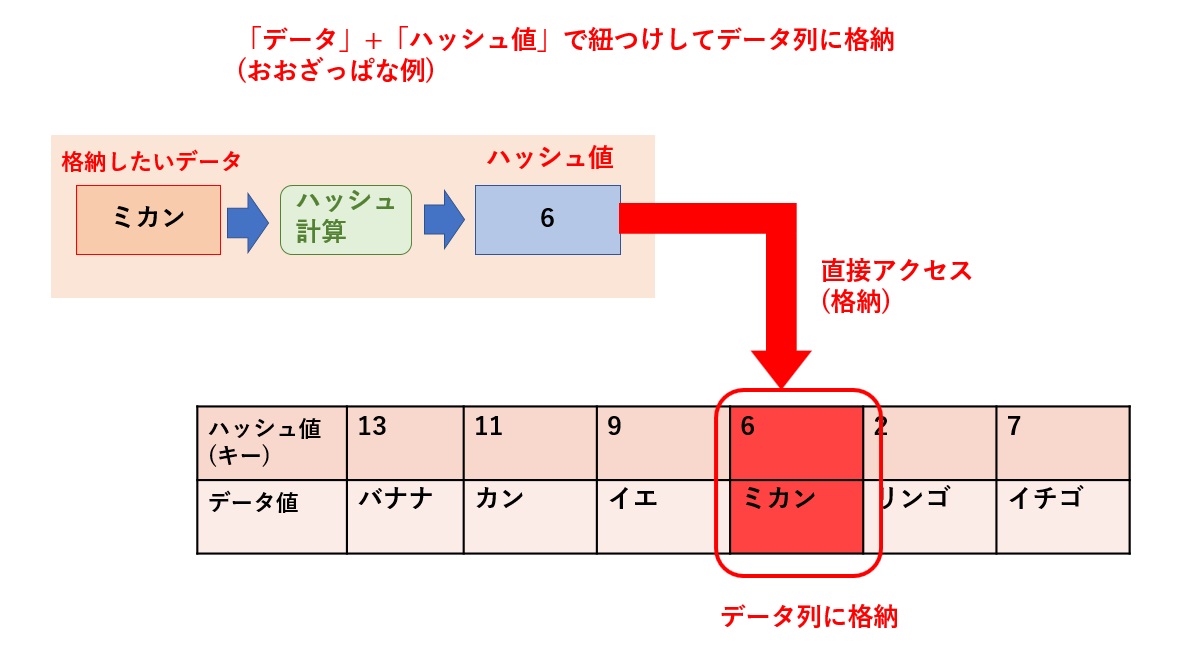
データの探索アルゴリズムの一つに**「ハッシュ法」**という手法がありますが、
このハッシュ(探索)法とは
私自身の解釈として、(おおまかでありますが、)
-
探索したいデータをハッシュ関数で計算する
-
ハッシュ値(キー値。アドレスみたなもの?)を出力する。
-
出力したハッシュ値を元に、データ列にあるハッシュ表から直接該当するハッシュ値(キー値)にアクセス(探索)する。
このような感じであると私自身思いますが、つまり、「ハッシュ探索法」は
「出力したハッシュ値を元にデータ列にあるハッシュ表から直接アクセスしてデータを探索する」
ということなんでしょうか?(大雑把ですが・・・)
何か所々解釈が間違っていると思いますが、その解釈でいいのでしょうか?
よろしくお願いします。
(ちなみに掲載されている図はあくまで例であることを御了承いただけばと思います。)

気になる質問をクリップする
クリップした質問は、後からいつでもMYページで確認できます。
またクリップした質問に回答があった際、通知やメールを受け取ることができます。
回答4件
0
他の回答者も書いていますが「ハッシュ関数」の衝突を補足します。
ハッシュ関数の出力は衝突する
『世界標準MIT教科書 Python言語によるプログラミングイントロダクション第2版』近代科学社より引用。
『ハッシュ関数は大きな集合から小さな集合への写像である。ハッシュ関数を用いることで、大きな集合の属するキーを小さな集合に属する整数へと変換できる。ハッシュ関数の出力の集合は入力の集合に比べて小さいため、ハッシュ関数は、多対1写像 (many-to-one mapping) を生成する。2つの入力が同一の出力へ写像される場合を衝突 (collision) という。衝突がなるべく起きないようにするには、各出力が均等に発生するような一様分布 (uniform distribution) を作り出すハッシュ関数を考案しなければならない。』
- ハッシュ関数は、多対1写像 (many-to-one mapping)
ミカンとリンゴを入力とすると、同じ値が出力されることがある。 - 2つの入力が同一の出力へ写像される場合を衝突 (collision) という。
一つの指定席に二人(以上)の人が座りたいということが起る。衝突をできるだけ回避するために出力を一様分布にしたい。
ハッシュテーブルの実装
衝突を考えると、配列に格納するために工夫が必要になります。
- 同じハッシュ値のエントリを隣に置く
本来隣は別のハッシュ値の指定席なので、どんどんずれる。空席に出会うまで衝突かどうか線形探索する必要がある。 - 指定席自体を配列や連結リストにして衝突を格納できる構造にする。
質問の図のような単純な配列ではなく、配列の配列や、結合リストの配列にする。
入力のビットの数を数えて偶数なら0奇数なら1というハッシュ関数をつくると出力値は2つ。大量の衝突が起きる。衝突の中からめざす値(リンゴかミカンか、...)を発見するのにリストをさらに線形探索する。このようにハッシュ関数が悪いと非効率。
ハッシュ関数の実装
上の本にはハッシュ関数の実装について書かれていません。以下の本を読んでください。
『世界標準MIT教科書 アルゴリズムインロダクション第3版 第1巻』近代科学社
衝突の起きるハッシュ関数だけでなく、衝突の起きない「完全ハッシュ法」も紹介されています。
ハッシュ関数の応用
パスワード、電子署名など様々な分野で使われています。wikipediaを読んでみましょう。
【追記(2019-04-28)】
キーと値
ハッシュ値(配列の添字)が「キー」と思われているようですが間違いです。キーは「リンゴ」「ミカン」になります。英語の辞書に例えると、英単語が「キー」単語の説明が「値」に相当します。質問の例は「キー」と「値」が同じ辞書です。ハッシュテーブルを「辞書」「連想配列」「ハッシュ」と呼ぶことがあります。
ハッシュテーブルのエントリ
通常は(キー、値)のペアになります。理由は、衝突リストに格納されたエントリを識別するのにキーの同値判定が必要だから。
投稿2019/04/27 10:05
編集2019/04/28 00:30総合スコア1114
0
大体あっていると思いますよ。
ただし、現実にはデータと数値を完全に1対1に対応付けるのが不可能なので、同じハッシュの結果になったものはリストなどの形で同じ場所に収められる、などの形態がとられているくらいでしょうか。単に全部をリストにするとすべてのデータを探さなければいけないのに対し、同じデータである可能性のある一部のデータだけ探せば済みます。
投稿2019/04/21 02:14
総合スコア20675
0
抽象的な記述なので、なんとも言いがたいですが、おそらく間違っています。
データを格納するテーブルサイズをNとすると、データ中のキーとなる値(質問の例だと果物名)のハッシュ値を求め、その値に何らかの演算を行って0~N-1の添え字を求めます。
テーブルのその添え字の場所に、データを格納します。実際は、データへのポインタを格納すると思いますが。
当然、異なるキー値に対して、添え字の重複が発生します。重複した場合(=求めた添え字の場所に既にデータが格納済みである場合)は、その近くの添え字の場所にデータを格納したり、添え字の場所から、線形リストで、同じ添え字になったデータをつなげたりします。
参照の場合は、求めた添え字の場所のキー値が等しければそれ。異なれば近くを探すか、リストをたどります。
データが増えてテーブルサイズがNで足りなくなった場合は、テーブルの拡張が必要です。そのあたりを実装したことないですが、おそらく、ハッシュ値から添え字を求め直して、データ(のポインタ)を移動させるんじゃないでしょうか。移動しないで済む方法もありそうな気もしますが。
投稿2019/04/20 17:42
総合スコア86645
![]()
2019/04/27 10:46
>「テーブルの拡張」はあるのでしょうか? 拡張でなく、再作成ではないでしょうか?
Javaの例ですが、初期化時にサイズを指定できます。サイズ不変ならそのまま使えばよろしい。登録数が閾値(0.75?)を超えると、サイズ2倍のテーブルを作成しハッシュ値を再計算して格納します。衝突の可能性は1/2になります。いったん拡張すると縮小できないので非効率になることも。オブジェトが短命なら気にしなくてもよいでしょう。
2019/04/27 11:55
> サイズ2倍のテーブルを作成しハッシュ値を再計算して格納
拡張とは言うものの、再作成ですね。
あ、ハッシュ値の作成もなるべく均一になるようすべきなので、そこも腕の見せ所でしたね。(難しいですが)
> 質問の説明と書き方の違いだけで、同じように感じるのですが。
質問文では、テーブルの絵が間違っていますね。
絵が無くて文章だけなら、合っているか間違っているか「微妙」というところです。
> 「テーブルの拡張」はあるのでしょうか? 拡張でなく、再作成ではないでしょうか?
再作成は、拡張の一手段です。回答にに書いたとおりで、おそらく再作成だが、もしかすると再作成でない拡張もあるかも知れないので、そういう記述にしました。
> 元々のデータをそのまま、キーにすると、テーブルサイズが大きくなるので、ハッシュテーブルで、テーブルサイズを小さくし、検索を容易にするのでは無かったですか?
この表現も微妙ですね。キーにするというかテーブルの添え字にするので、元々のデータが整数値でないと添え字に出来ません。
正しく書き直すと、
「元々のキーでは、テーブルの添え字に出来ないか出来ても膨大なサイズのテーブルになるので、ハッシュ計算により実用的な範囲の整数に直してテーブルの添え字にする」
でしょう。
0
実装とかはotnさんの回答されいてるようなことだと思いますが…
キーが付与されていない大きめのデータを効率よく探索したい
てのが要点なんじゃないかなあ。
例示されたような小さいものだとハッシュ値がかぶりまくりで
うまく運用するのは難しいと思います。
投稿2019/04/20 23:30
総合スコア7468
あなたの回答
tips
太字
斜体
打ち消し線
見出し
引用テキストの挿入
コードの挿入
リンクの挿入
リストの挿入
番号リストの挿入
表の挿入
水平線の挿入
プレビュー
質問の解決につながる回答をしましょう。 サンプルコードなど、より具体的な説明があると質問者の理解の助けになります。 また、読む側のことを考えた、分かりやすい文章を心がけましょう。


