
回答有難うございます。
物体認識の場合はモデルの構成が違ったり、tiitoiさんのおっしゃられているように入力層に近い部分も用いているので、一般的なCNNで可能かと言われるとできないなんてありえないとは言えなくはないですか?
CNNの出力層付近において位置情報がほとんど残っていると言えるのでしょうか?
CNNにおいて、同じ物体を位置の違い(左右等)で分類することは理論上可能なのでしょうか?
私の見解としては不可能だと考えております。
これはどの程度の位置を分類するかにもよるとは思いますが、位置に依存しないCNNにおいて位置による分類ができるとは思えません。
しかし、実際に簡単なモデルで試してみた結果、収束し、分類できてしまいました。
もっと複雑なケースで試してみようとは思っています。
理論上、位置による分類は可能なのでしょうか?

Label : 左

Label : 右
モデル : VGG16
手法 : fine-tuning
画像処理 : ノイズ付与
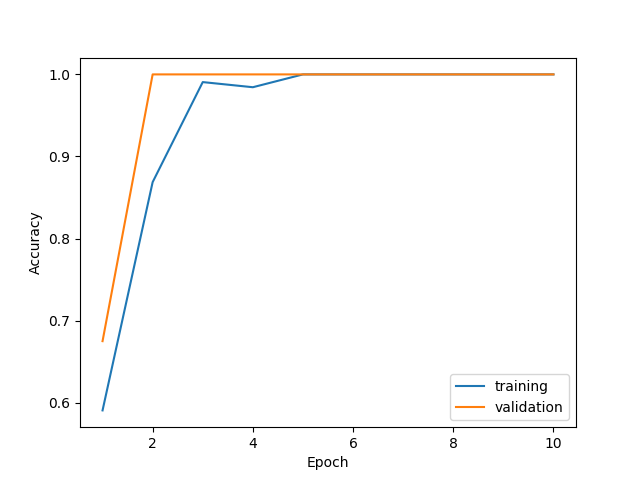
追記
学習済みモデルを使ってVGG16の最後のPooling層後の特徴マップを可視化してみました。






・特徴マップには様々な特徴があり、位置情報を掴めていないように見えるが、どの特徴を使えば
分類出来るかを学習することで位置の特徴として捉えている。
・7×7から1×1に畳み込んでないのを考えると位置情報はある程度残っていること。
・しかし、224×224の画像を7×7の32まで圧縮しているため位置情報は1/7程度だと推測されること。
が分かりました。
回答していただいたみなさん有り難うございました!
回答4件
あなたの回答
tips
プレビュー



2019/01/18 08:42
2019/01/18 08:50
2019/01/18 08:54