



hayataka2049さん、ご回答いただきありがとうございます!
なるほど、シンプルな事例を挙げていただき
確かに浅い深さでもうまく判別できていますね!
下のmaro_amoebaさんとnoukenさんとのやり取りの中書いた、
決定木は
「分割の判断の際に特徴量の組み合わせは考慮されていない」
ように見えることについてなのですが、
これが考慮されていないから、あえて掛け合わせることに意味が出てくる場合がある
と考えてもよろしいのでしょうか?
機械学習の木系モデルを使う際の話なのですが、
特徴量の積は有効なのかあまり意味がないのか
お聞きしたくて投稿しました。
例えば特徴量がA,B,Cと3つあるとして、
これらは全てカテゴリ変数ではないものとします。
そして、モデルは木系のモデルを使うとします。
その際、
A×B=D
A×C=E
B×C=F
という風にA,B,Cの特徴量を掛け合わせた
新しい特徴量D,E,Fを作って追加して学習させることは
有効なのか、あまり意味がないことなのか
どちらなのでしょうか?
自分はまだあまり詳しくわかっていなくて
間違っているかもしれませんが、
例えば木系のモデルとしてランダムフォレストを使う場合
根っこからたどって
1つ目のノードで特徴量Aが選ばれ、2つ目のノードで特徴量Bが選ばれたとすると
イメージ的にAかつBのように判断されているのではないかと思い
それは新たにA×B=Dという特徴量を追加しなくても
ちゃんと考慮されてるんじゃないかなと
なんとなく思っていますが・・・。
試しに特徴量同士の積を新たな特徴量として
実際にやってみたらいいのですが、
今やっている問題は特徴量の数が5000ぐらいあるので
そもそも意味があるものなのか
一般論としてお聞きしたいなと思いました。
ご回答のほど宜しくお願い致します。
気になる質問をクリップする
クリップした質問は、後からいつでもMYページで確認できます。
またクリップした質問に回答があった際、通知やメールを受け取ることができます。
バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
回答4件
0
シンプルに、決定木モデルは分岐点の候補が多ければ多いほど機械側は嬉しいです。
使える特徴量かどうかは機械側が判断します。
仮に決定木モデルはゴミを投げても、特徴量の重要度を下げ使わない判断をしてくれますのでその点は安心です。
そのため特徴量を掛け合わせたり、足したりといったこともテクニックとしてありますし、多少有効に働くことが多いです。
もちろんGolden Feature(問題空間をよく表す最適な特徴)を与えるのが理想です。
投稿2018/12/23 09:29
総合スコア33
0
データ依存ですが、効くときは効きます。
たとえば底辺と高さがわかっている長方形の面積がしきい値を超えるかどうか、というタスクを考えます。
python
1import numpy as np 2from sklearn.tree import DecisionTreeClassifier as DTC, export_graphviz 3 4xy = np.random.rand(300, 2)*10 5label = (xy[:,0] * xy[:,1] > 20).astype(int) 6 7dtc = DTC() 8dtc.fit(xy, label) 9export_graphviz(dtc, "tree1.dot") 10 11xy2 = np.hstack([xy, (xy[:,0]*xy[:,1]).reshape(-1, 1)]) 12dtc = DTC() 13dtc.fit(xy2, label) 14export_graphviz(dtc, "tree2.dot") 15 16""" 17$ dot -Tpng tree1.dot -o tree1.png 18$ dot -Tpng tree2.dot -o tree2.png 19"""
tree1.png

tree2.png
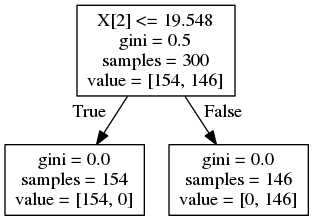
実データでここまで顕著なのはないと思いますが、少しでもこういう傾向を持っていれば効きます。掛け合わせ変数がより効果的な説明変数であれば木を浅くでき、汎化性能に影響することでしょう。
投稿2018/12/24 14:38
総合スコア30939
バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
![]()
0
ちょっと気になったのでbreast_cancerのデータセットで実際にやってみました。
python
1import numpy as np 2import pandas as pd 3import matplotlib.pyplot as plt 4import seaborn as sns 5%matplotlib inline 6 7from sklearn.tree import DecisionTreeClassifier 8from sklearn.datasets import load_breast_cancer 9from sklearn.model_selection import train_test_split 10from sklearn.metrics import accuracy_score 11 12# モデルの木構造の視覚化に必要なパッケージ 13from sklearn import tree 14import pydotplus as pdp 15 16breast_cancer = load_breast_cancer() 17df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names) 18 19df['target'] = breast_cancer.target 20#一応シャッフル 21df = df.sample(frac=1, random_state=1) 22target = df['target'] 23df.drop('target', axis=1, inplace=True) 24 25x_train, x_val, y_train, y_val = train_test_split(df, target, test_size=0.25, random_state=1) 26x_train.shape, x_val.shape, y_train.shape, y_val.shape 27 28model = DecisionTreeClassifier(random_state=1) 29model.fit(x_train, y_train) 30y_pred = model.predict(x_val) 31print('acc: {}'.format(accuracy_score(y_val, y_pred))) 32 33importance_df = pd.DataFrame() 34importance_df['feature'] = breast_cancer.feature_names 35importance_df['importance'] = model.feature_importances_ 36importance_df = importance_df.sort_values(by='importance', ascending=False).head(10) 37sns.barplot(x='importance', y='feature', data=importance_df) 38 39#file_name = "./tree_visualization.png" 40#dot_data = tree.export_graphviz(model, out_file=None, filled=True, rounded=True, feature_names=df.columns, 41 #class_names=breast_cancer.target_names, special_characters=True) 42#graph = pdp.graph_from_dot_data(dot_data) 43#graph.write_png(file_name)
acc: 0.9370629370629371
python
1np.mean(cross_val_score(DecisionTreeClassifier(random_state=1), df, target, cv=5))
0.93674490188534043
python
1import numpy as np 2import pandas as pd 3import matplotlib.pyplot as plt 4import seaborn as sns 5%matplotlib inline 6 7from sklearn.tree import DecisionTreeClassifier 8from sklearn.datasets import load_breast_cancer 9from sklearn.model_selection import train_test_split 10from sklearn.metrics import accuracy_score 11 12# モデルの木構造の視覚化に必要なパッケージ 13from sklearn import tree 14import pydotplus as pdp 15import itertools 16 17breast_cancer = load_breast_cancer() 18df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names) 19 20df['target'] = breast_cancer.target 21#一応シャッフル 22df = df.sample(frac=1, random_state=1) 23target = df['target'] 24df.drop('target', axis=1, inplace=True) 25 26#特徴量の掛け合わせ 27for f1, f2 in itertools.combinations(df.columns, 2): 28 df[f1+'*'+f2] = df[f1] * df[f2] 29 30x_train, x_val, y_train, y_val = train_test_split(df, target, test_size=0.25, random_state=1) 31x_train.shape, x_val.shape, y_train.shape, y_val.shape 32 33model = DecisionTreeClassifier(random_state=1) 34model.fit(x_train, y_train) 35y_pred = model.predict(x_val) 36print('acc: {}'.format(accuracy_score(y_val, y_pred))) 37 38importance_df = pd.DataFrame() 39importance_df['feature'] = df.columns 40importance_df['importance'] = model.feature_importances_ 41importance_df = importance_df.sort_values(by='importance', ascending=False).head(10) 42sns.barplot(x='importance', y='feature', data=importance_df) 43 44#file_name = "./tree_visualization.png" 45#dot_data = tree.export_graphviz(model, out_file=None, filled=True, rounded=True, feature_names=df.columns, 46 #class_names=breast_cancer.target_names, special_characters=True) 47#graph = pdp.graph_from_dot_data(dot_data) 48#graph.write_png(file_name)
acc: 0.965034965034965
python
1np.mean(cross_val_score(DecisionTreeClassifier(random_state=1), df, target, cv=5))
0.95087341285109661
決定木の可視化にはgraphvizのinstallが必要ですが、それを見ると掛け合わせ特徴を用いた方が少ない枝分かれでより高い正解率を達成しています。もちろんデータにもよりますが、試してみる価値はあると思います。
投稿2018/12/23 01:57
総合スコア369
バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
![]()
おおおおおおおお!
DecisionTreeで見ると確かに違いが出ていますね~。
書いていただいたコードをRandomForestClassifierに変えると
同じになりましたが、
木1個単位では少ない枝分かれでより早く精度を上げている
感じになるのですね。
ご丁寧にコードまで書いてくださってありがとうございます^^
すいませんランダムフォレストで試してなかったんですが、確かにデフォルトパラメータのままだとクロスバリデーションスコアの差がほとんどなくなりますね。ただ、n_estimators=500にして、クロスバリデーションすると、1.2%ほど掛け合わせ特徴量を使った方が正解率が高くなりますね。
自分も勉強になりました!
おお、ランダムフォレストでも差が出ましたか!
試していただいてありがとうございます^^
ちなみにnoukenさんはランダムフォレストの計算式のような
数学的な部分も理解を進めながら使用されていますか?
僕は数学的な部分はさっぱりなもので・・・^^;
機械学習の勉強始めた頃は難しいところは飛ばしてとりあえず使えたらいいか、っていう感じでしたが、勉強を進めるにつれやはり理論もある程度わかっていた方がいいと気づいたので、最近は理解しようと努力はしています。でもなかなか難しいですよね。。。
そうですよね・・・内部的にどんな動作をしているか
ある程度分かっておいたほうがいいですよね・・・。
僕は株価の分析に機械学習を使っているのですが、
手法のどこを特徴量にすればいいかに頭を使っていて
なかなか理論的なことが進められていないので
勉強していこうと思います。。。
難しい部分も多いですよね^^;
0
randomforestにそのまま突っ込むよりも、明示的に掛け合わせた方がモデルにとって学習しやすいといったケースもあると思います。自分の経験上、やってみないとわかりませんが、効くこともあるといった感じでう。5000を全て掛けあわせるのは厳しいものがあると思うので、特徴量重要度上位の者同士であったり、ドメイン知識から考えて有効ではないかと考えられる組み合わせなどを試してみるのはどうでしょうか?
投稿2018/12/22 13:50
総合スコア369
バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
![]()
noukenさん、ご回答いただきありがとうございます!
なるほど、重要度が高いもの同士を掛け合わせるなどで
効率化してみるといいのではないかということなんですね。
モデルにとって学習しやすいというのは、
特に特徴的だった値同士が掛け合わせることによって
さらに強力に色濃く特徴として出てくるので
それをモデルが見分けやすくなる
というイメージでしょうか?
そのようなイメージで良いと思います。僕もそれほど専門的なことはわからないですが、モデルに「察して」もらうよりもこちらが「’示して」あげた方が分類しやすくなることもあるのかなぁというイメージです。
なるほど、なるほど。
察してもらうより、しっかりと示してあげたほうがいい
というのは分かりやすい表現ですね^^
あなたの回答
tips
太字
斜体
打ち消し線
見出し
引用テキストの挿入
コードの挿入
リンクの挿入
リストの挿入
番号リストの挿入
表の挿入
水平線の挿入
プレビュー
質問の解決につながる回答をしましょう。 サンプルコードなど、より具体的な説明があると質問者の理解の助けになります。 また、読む側のことを考えた、分かりやすい文章を心がけましょう。



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2018/12/23 13:19 編集
2018/12/23 14:32 編集
2018/12/23 15:22
2018/12/24 01:24 編集
2018/12/24 03:28
2018/12/24 05:46
2018/12/24 05:55
2018/12/24 06:04 編集