
ご回答ありがとうございます。
実行したところ
[[5]
[0]
[0]
[8]]
[[ 5]
[29]
[58]
[ 4]]
[[ 5]
[30]
[58]
[ 1]]
[[6]
[0]
[0]
[5]]
[[ 6]
[29]
[57]
[ 8]]
となり、最初のブロック以外は、正しく引き算されていませんでした。
実現したいこと
こちらの関連質問です。
こちらに書かれているサンプルデータは、以下の図に示す通り、私が手動でbeforeからafterに操作して作られたものでした。

各塊は、
x座標
y座標
z座標
値
の順番に並んでいます。
「手動」の内容は、
y座標=y座標ー(一番最初の塊のy座標)
z座標=z座標ー(一番最初の塊のz座標)
です。(少しでも分かりやすくなることを期待して、図の数字の色を変えています)
「該当のソースコード」の14行目の29、15行目の57を取り出すにはどのようにすれば良いでしょうか。sample_before20.txtでは14行目の29、15行目の57ですが、sample_before30.txtでは14行目を28、15行目を57にしたいです。
該当のソースコード
python
1import numpy as np 2import pandas as pd 3 4data_files = ['sample_before20.txt', 'sample_before30.txt'] 5 6for f in data_files: 7 # 4行ごとに読み込み(空行はスキップされる) 8 for blk in pd.read_csv(f, header=None, chunksize=4): 9 blk = blk.to_numpy() 10 11 blk[1] = blk[1] - 29 12 blk[2] = blk[2] - 57 13 14 print(blk) 15 16 bwe = os.path.splitext(os.path.basename(f))[0] 17 print(bwe)#sample_before20 18 filename_after = bwe + '_after.txt' 19 print(filename_after)#sample_before20_after.txt、sample_after20.txtにしたい
試したこと
最初の塊の2行目、3行目の値を保存する方法がよく分かりませんでした。
あと、sample_after20.txtとsample_after30.txtを保存する方法もよく分かりませんでした。
melianが👍を押しています
気になる質問をクリップする
クリップした質問は、後からいつでもMYページで確認できます。
またクリップした質問に回答があった際、通知やメールを受け取ることができます。
回答5件
0
既に解決済みなので御参考です。
各行に1データが記述されているテキストファイルから全データをリストに取り込むには,str.splitlines() メソッドを用いる方法も考えられます(記述例を下記に示します)。なお,空行は空文字列になるのでそれをスキップするために if s を用いています。
また,リスト(lst)をスライス(lst[i:i + 4])を用いて分割し,テキストファイル内の各塊が1段階目の各要素で,その各要素(リスト)の中身が「x座標,y座標, z座標, 値」である2次元リスト(blks)を作成しています。
Python
1import glob 2 3for fname_before in glob.glob('sample_before*.txt'): 4 with open(fname_before, 'r') as f: 5 lst = [int(s) for s in f.read().splitlines() if s] 6 blks = [lst[i:i + 4] for i in range(0, len(lst), 4)] 7 8 y0, z0 = blks[0][1:3] 9 blks = [[x, y - y0, z - z0, v] for x, y, z, v in blks] 10 11 fname_after = fname_before.replace('_before', '_after') 12 s = '\n'.join(''.join(str(i) + '\n' for i in r) for r in blks) 13 with open(fname_after, 'w') as f: 14 f.write(s)
投稿2025/08/07 07:08
総合スコア543
0
質問のコードを生かすならこんな感じかな
そのブロックが最初のブロックかどうか判定して最初のブロックの値を保存する方法。
いろいろやりかたあると思いますけど、フラグを使う方法。 0での初期化は不要だけど、気持ちで。
python
1for f in data_files: 2 # 1ブロック目かどうか 3 first_block = True 4 x0 = 0 5 y0 = 0 6 # 4行ごとに読み込み(空行はスキップされる) 7 for blk in pd.read_csv(f, header=None, chunksize=4): 8 blk = blk.to_numpy() 9 if first_block: 10 x0 = blk[1] 11 y0 = blk[2] 12 first_block = False 13 14 blk[1] = blk[1] - x0 15 blk[2] = blk[2] - y0 16 17 print(blk) 18
投稿2025/08/01 04:37
総合スコア14669
![]()
元のコードがどううごくのか見ていないのでわかりませんが、x0, y0にどんな値が入っているか確認してみると問題がわかるかもしれません。
2025/08/01 05:45 編集
x0 = blk[1] や y0 = blk[2] が shallow copy であるためです。そのため、blk[1] = blk[1] - x0 が実行されると x0 は 0 になります。(y0も同様) 以下の様に変更すれば値のコピーになります。
x0 = blk[1,0]
y0 = blk[2,0]
17行目を
print(x0)
print(y0)
にして、実行すると以下のようになります。
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
melian様のコメントに従って、
import copy
x0 = copy.deepcopy(blk[1])
y0 = copy.deepcopy(blk[2])
とやると、正しい結果になりました。
melian様、どうもありがとうございました。
元のソースコードを見ると、期待しているblkの値は
[[5]
[0]
[0]
[8]]
のような2次元配列にでなく、 [5, 0, 0, 8] のような1次元の配列になるのが本筋ではないかと思うのですが、どうでしょう。
2025/08/02 04:41
> [5, 0, 0, 8] のような1次元の配列になるのが本筋ではないか
1次元配列の場合、np.savetxt(output, blk[3], fmt='%.3f') でエラーになります。(ValueError: Expected 1D or 2D array, got 0D array instead) つまり、blk は 2D 配列の方が都合がよいわけです。もちろん、np.savetxt(output, blk[3:3], fmt='%.3f') とすれば 1D 配列になります。
コメントありがとうございます。
操作ベースでできたものに合わせて処理するというやりかたならそれで構わないし、使っている人がそれを理解していてadhocでやるならいいですが、質問のようなデータを2次元配列で表現するのには違和感あります。
僕の説明が足りていないというのはその通りです。
0
![]() ベストアンサー
ベストアンサー
基点となる一番最初の塊のy, z座標(y0, z0)を記録しておき、各ブロックの y, z座標との差分を計算してファイル(sample_after*.txt)に保存します。
python
1import numpy as np 2import pandas as pd 3 4data_files = ['sample_before20.txt', 'sample_before30.txt'] 5for f in data_files: 6 # 4行ごとに読み込み(空行はスキップされる) 7 blks = [blk.to_numpy() for blk in pd.read_csv(f, header=None, chunksize=4)] 8 y0, z0 = blks[0][1:3,0] # 一番最初の塊のy, z座標 9 after_file = f.replace('before', 'after') 10 # ファイル(*_after*.txt)に保存 11 with open(after_file, 'w') as output: 12 for i, blk in enumerate(blks): 13 # 2番目以降のブロックでは空行を入れる 14 if i > 0: print('', file=output) 15 blk[1] -= y0 16 blk[2] -= z0 17 # 座標は整数、値はfloat型で保存 18 np.savetxt(output, blk[:3], fmt='%d') 19 np.savetxt(output, blk[3], fmt='%.3f')
追記
上記のコードでは各ブロックで相対値を計算していましたが、以下のコードではファイルからデータを読み込んでnumpy配列(3D array)にして全ブロックのy,z座標を相対値に変換しています。
※ numpy.loadtxt() や numpy.savetxt() の API ドキュメントを確認してコードを書き換えました
python
1import numpy as np 2from glob import glob 3 4data_files = glob('*_before*.txt') 5for f in data_files: 6 # 4行ごとに分割(空行はスキップされる) 7 blks = np.loadtxt(f).reshape((-1, 4)) 8 # y, z座標を相対値に変換 / blks[0,1:3] は一番最初の塊のy, z座標 9 blks[:,1:3] -= blks[0,1:3] 10 after_file = f.replace('before', 'after') 11 # ファイル(*_after*.txt)に保存 12 np.savetxt(after_file, blks, fmt='%d\n%d\n%d\n%.3f\n') 13 ## 上記の場合、出力ファイルの最終行に空行が挿入されてしまいますので、それを避けたい 14 ## 場合は以下の様に変更してください 15 # with open(after_file, 'w') as output: 16 # for i, blk in enumerate(blks): 17 # # 2番目以降のブロックでは空行を入れる 18 # if i > 0: print('', file=output) 19 # # 座標は整数、値はfloat型で保存 20 # np.savetxt(output, [blk], fmt='%d\n%d\n%d\n%.3f')
投稿2025/08/01 03:26
編集2025/08/04 07:35総合スコア21564
![]()
できました。
どうもありがとうございました。
ファイルが増えたとき用に、4行目を
data_files = ['*.txt']
のように書けたら嬉しいのですが、このような表記法がありましたら、お教えください。
実際にやってみると、以下のようなエラーが出ます。
OSError: [Errno 22] Invalid argument: '*.txt'
glob() を使ってみてはどうでしょうか。なお、'*.txt' ですと、sample_after*.txt にもマッチしてしまいますので 'sample_before*.txt' や '*_before*.txt' などとする方がよいかと思います。
from glob import glob
data_files = glob('sample_before*.txt')
できました。
どうもありがとうございました。
追記のコードもありがとうございました。
2025/08/02 04:47
python 分からないモノがふと思っただけで質問自体とも関係無くてすみません、
> with open(after_file, 'a') as output:
> # 最初に出力ファイルの内容を空にする
> output.seek(0, 0)
> output.truncate()
はなぜ 'w' モードを用いられないのでしょうか。
> jimbe さん
コメントありがとうございます、確かにその通りです。当初、各ブロックを保存する度にファイルをオープン/クローズしていた際のコードをそのままにしていました。
>jimbe様、melian様
コードの修正、ありがとうございました。
>melian様
こちらのコードに対しても、修正ありがとうございました。
0
(承前)
貴方の大変良いトコロで、他のnumpy/pandas使用のPython初心者と一線を画してるのはデータ形式の重要性を良く理解している辺りだ。
データ形式の重要性を知らなく(ヒドい教育を受けてるから)、コッチが何だか分からんのに「教えてください」な人が多くて辟易する事が多いんだけど、貴方はデータ形式の重要性を良く知っている。
極端に言うと、データ形式はプログラム自体より重要なんだ。
"Show me your flowchart and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won’t usually need your flowchart; it’ll be obvious."
(「フローチャートを見せてテーブルを隠されても、私は何をしているのか分からない。だがテーブル(=データ構造)を見せてくれれば、たいていフローチャートなど不要だ。何をすべきか分かるからだ。」)
Fred Brooks

この、実際に想定しているデータ形式を提示するのは素晴らしい。恐らく、習ってない筈なのに貴方は「データ形式の重要性」を理解している。天才かもしんない。もっとも、その天才に対して「何を杜撰な教育してんじゃボケェ!」って貴方が習ったトコに怒りが再燃するが(笑)。
さて、ここで貴方はデータ形式の重要性を理解している。ただ、ここで考えてみて欲しい。果たしてこのデータ形式のファイルを読み込む前提で、pandasとかnumpyなんかのライブラリを使う必要性があるのか?と。
例えば、貴方の「定義した」データ形式だとデータは1列に並べられていて、データの区分は空白で改行だ。
これは例えばExcelとやり取り出来るようなcsvみたいなデータフォーマットではない、んだ。
最終的な題意は「ファイルを読み込んで」「ファイルを書き出す」んだけど、実は扱ってるのは単なるベタなプレインテキストファイルなんだよな。
もちろん、複雑なデータ形式だと構文解析なんかをやらなきゃなんなくなり、手間なんで、pandasみたいな「既存のデータフォーマットを気楽に扱える」ライブラリは有用だろう。
ただし、それはどのみち、「最初にデータ形式を設計して」、複雑なデータになりそうな場合に頼る、って事なんだよ。
データ形式を作成する前に、始めにpandas/numpyアリ、って想定はおかしいんだ。
繰り返す。ここは発想が逆で、データ形式の設計が複雑になった場合にpandasを始めて考慮する、ってのが正しい道筋なんだ。
もう一つの問題は、「データ形式の設計がプログラミングに於いて一番大事だ」と言う事は、プログラムとは一種のフィルタを意味する。件の本でも
- すべてのプログラムをフィルタにする
ってのが提言として成されている。
一方、「フィルタである」と言う事はデータ型またデータ形式の変換が頻繁に行われる、と言う事を意味する。
意味するんだけど、Numpyとかpandasの場合、その「形式」がややこしかったり、あるいは「Python外」の場合が多いんだ。特にNumpyの場合、実体はC言語で書かれた「別のプログラム」でPython内のデータと相互変換するのが面倒くさかったりする。また、pandasでファイルを開くと「余計な情報が付随したり」する。原則、pandasが想定しているのはExcelみたいな形式のデータフォーマットだから、だ。
反面、ファイルを開いた後、「必ずそのファイルを閉じなければならない」んで、時々それを忘れるんだが(良くやる・笑)、その辺、pandasのread_csvは自動で面倒を見てくれるんでラクだったりはする。
pandasのread_csvでsample_before20.txtを読み込むと次のようになる。
Python
1>>> pd.read_csv('sample_before20.txt', header=None, chunksize=4) 2<pandas.io.parsers.readers.TextFileReader object at 0x73d12eb96ab0>
見た通りイテラブルが返ってくる事が分かる。
つまりリスト内包表記でこのイテラブルも操る事が出来る。
Python
1>>> [blk for blk in pd.read_csv('sample_before20.txt', header=None, chunksize=4)] 2[ 0 30 5 41 29 52 57 63 8, 0 74 5 85 29 96 58 107 4, 0 118 5 129 30 1310 58 1411 1] 15
見た通り、データフレームを得る。
ここで貴方はNumpyのndarrayに変換しようとしたが、上でも見た通り、本質的にはこの計算はリスト対象だ。と言うかその方がスッキリしている。
従ってvalues.tolist()で一旦素直にリストへと変換した方がいい。
Python
1>>> [blk.values.tolist() for blk in pd.read_csv('sample_before20.txt', header=None, chunksize=4)] 2[[[5], [29], [57], [8]], [[5], [29], [58], [4]], [[5], [30], [58], [1]]] 3
しかしここで一つ問題が出てくる。データフォーマット上、データは縦に並べられていた。
そのため、二次元リストを想定してたんだけど、各要素もリストになってて、三次元リストとして処理されちゃうんだな。
ここで、例えば[[5], [29], [57], [8]]と言うリストを[5, 29, 57, 8]へと直したい。
この作業をflatten(平坦化)と呼ぶ。入れ子になってる状態を平坦化するんだ。
Pythonで一番簡単なflattenのやり方は、なんとsumを使う事だ。
Python
1>>> sum([[5], [29], [57], [8]], []) 2[5, 29, 57, 8] 3
オプショナル引数に[]を指定すると入れ子のリストを平坦化する。
すなわち、
Python
1>>> [sum(blk.values.tolist(), []) for blk in pd.read_csv('sample_before20.txt', header=None, chunksize=4)] 2[[5, 29, 57, 8], [5, 29, 58, 4], [5, 30, 58, 1]] 3
となる。
ここまで来れば、読み込み -> 計算処理は書ける事、となる。
Python
1>>> foo([sum(blk.values.tolist(), []) for blk in pd.read_csv('sample_before20.txt', header=None, chunksize=4)]) 2[[5, 0, 0, 8], [5, 0, 1, 4], [5, 1, 1, 1]] 3
次はファイル出力だ。
先にも書いたけど、少なくともお題のようなデータ形式での出力だと、Numpyもpandasも経由する必要はないんだ。
必要なのは単に文字列なんだよ。
上にも書いたけど、「扱いが面倒くさくなるようなデータ変換」ならやらん方がマシ、なんだ。
例えば[5, 0, 0, 8]に対して各要素を「文字列化」する。
Python
1>>> map(str, [5, 0, 0, 8]) 2<map object at 0x73d10871b610> 3
mapを使って文字列化(str)したんでイテラブルが返ってくる。
これにjoinを用いて間に改行文字(\n)を挟む。
Python
1>>> '\n'.join(map(str, [5, 0, 0, 8])) 2'5\n0\n0\n8' 3
従って、次のようにすれば「(解答である)文字列のリスト」が得られる。
Python
1>>> ['\n'.join(map(str, i)) for i in foo([sum(blk.values.tolist(), []) for blk in pd.read_csv('sample_before20.txt', header=None, chunksize=4)])] 2['5\n0\n0\n8', '5\n0\n1\n4', '5\n1\n1\n1'] 3
「文字列のリスト」が得られたんで、再びjoinを用いて、今度は各要素の間に\n\nを挟んで全部文字列として結合する。
Python
1>>> '\n\n'.join(['\n'.join(map(str, i)) for i in foo([sum(blk.values.tolist(), []) for blk in pd.read_csv('sample_before20.txt', header=None, chunksize=4)])]) 2'5\n0\n0\n8\n\n5\n0\n1\n4\n\n5\n1\n1\n1' 3
これでファイルへと書き出す文字列データが生成出来た。あとはこれをプログラムのソースコードへコピペして修正すればいいんだ。
またもや、昨今のPython周りの教育環境への苦言だが。
最近だと、とにかくVisual Studio Codeを導入させようとする輩が多い。端的に言うとそれは間違ってるんだ。
VS Codeだとデフォルト設定ではPythonインタプリタ(リスナ)が走らない。従って「表示する為だけに」print塗れのコードを書かせるハメになるし、そもそも「あるアイディアが正常に動くかどうか」テスト出来ない。
ぶっちゃけ、VS Codeを無責任に薦める人は、インタプリタを使ったインタラクティブな開発ってのに慣れてないんだ。
上にも書いたけど、コードを直接インタプリタに入力して、「思った通りの結果が出た」場合に、それを書いてるソースコードへとコピペして修正する。それが伝統的なインタプリタでの開発方法で、素のVisual Studio Codeだとそれが出来ないんだよ。
ハッキリ言って、Python備え付けのIDLEの方がマシだ。
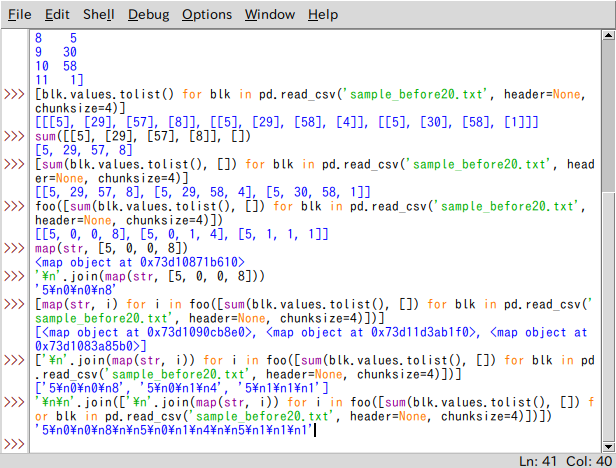
上の画面写真はIDLEのリスナだけど、これらは全部入力したわけじゃない。
IDLEには履歴機能(ヒストリ、等とも呼ぶ)があり、入力情報をAlt + P(Altキーを押しながらPキーを押す)で遡れるんだ。
そして遡った入力情報を「修正して」新しい入力とする。
こういう事がVisual Studio Codeでは素のままじゃ出来ないんだ。
あるいはエクステンションを導入すれば似たような事は出来るだろう。しかしまたそれを教えないんだ。
結果、Pythonニュービーは入れる必要のないVS Codeを導入して、設定が上手く行かずにQ&Aサイトに泣きつくハメになるんだ。
ホント、Pythonを使ったプログラミング入門系の輩はロクな事をしない。
残りは、出力用ファイルに上で作った文字列を書き出すだけ、だ。
結果、こんなプログラムになるだろう。
Python
1#!/usr/bin/env python3 2 3import sys 4import pandas as pd 5 6def foo(lst, i = 0, j = 1, k = 2): 7 ''' 8二次元リストの内側のリストはx座標、y座標、z座標、値で構成されている。 9各要素(リスト)に対してy座標 - i番目のy座標、z座標 - i 番目のz座標の計算を施す。 10''' 11 alpha, beta = lst[i][j], lst[i][k] 12 # 要素(リスト)をアンパックしながら計算を施す 13 return [[x, y - alpha, z - beta, v] for x, y, z, v in lst] 14 15if __name__ == '__main__': 16 # 端末上で 17 # プログラム名 ファイル名 18 # で使う。例えばプログラムファイル名がfooの場合、コマンドは 19 # foo sample_before20.txt 20 # となる。ただし、ファイル名は「必ず」文字列'before'を含むこと 21 filename = sys.argv[1] 22 filename_after = 'after'.join(filename.split('before')) 23 data = "\n\n".join(["\n".join(map(str, i)) for i in \ 24 foo([sum(blk.values.tolist(), []) for blk in \ 25 pd.read_csv(filename, \ 26 header=None, chunksize=4)])]) 27 with open(filename_after, 'w') as f: 28 f.write(data) 29
ファイル名用の変数を2つ用意する。1つ目はコマンドライン引数として受け取る前提とした。ここでは、そのファイル名は必ずbeforeを含むものとする。
2つ目は1つ目のファイル名に含まれるbeforeをafterですげ替える。本当だったら、性器正規表現を使えばカッコいいんだろうけど、面倒だからやらんかった(笑)。
変数dataにはインタプリタ上でテストした式がコピペされて束縛されている。
Python
1 data = "\n\n".join(["\n".join(map(str, i)) for i in \ 2 foo([sum(blk.values.tolist(), []) for blk in \ 3 pd.read_csv(filename, \ 4 header=None, chunksize=4)])]) 5
「こんなに長くてエエの?」って思う人もいるだろうけど、個人的には全く気にならんのでそのままにしてる。
まぁ、この辺はスタイルの問題であって、本質的な問題じゃないんで、気になる人はコピペした後にでも適宜新しく変数を作って代入していくプロセスにしてもエエんちゃうの。
いずれにせよ、これで「読み込み」 -> 計算 -> 「文字列化」と言う過程で全処理が終わったんで、あとは書き込み用ファイルに書き込むだけ、となる。
なお、ここでもこのプログラムはUNIXスタイルに則ってる。それは
- 過度の対話的インターフェースを避ける
だ。Windowsじゃ信じられないけど、「処理が終了しました」と言うメッセージは出さない(笑)。単に端末上でコマンドプロンプトが復活するだけ、となっている。
以上、かな。
駆け足だけど、「Pythonに於けるプログラミングのやり方」の大まかな説明は出来たと思う。
あとは、まぁ、頑張って。
投稿2025/08/04 05:00
編集2025/08/04 16:35総合スコア217
![]()
2025/08/04 07:59 編集
> 必要なのは単に文字列なんだよ。
正にその通りで、本質問の様な処理の場合は GNU awk の方が向いているかと思います。
bash$ for f in *before*.txt; do awk -vRS='\n\n' -vOFS='\n' 'NR==1{y0=$2;z0=$3}{$2-=y0;$3-=z0;if(NR>1)printf"\n"}1' "$f" > "${f/before/after}"; done
2025/08/04 06:36 編集
平坦化の処理ですが、
> [sum(blk.values.tolist(), []) for blk in pd.read_csv('sample_before20.txt', header=None, chunksize=4)]
Pandas には pandas.Series.to_list() というメソッドがありますので、以下の様にしても同じ結果が得られます。
[blk[0].to_list() for blk in pd.read_csv('sample_before20.txt', header=None, chunksize=4)]
> GNU awk の方が向いている
そうですね。その方がUNIX上だと早いかも。
コードも短いし。
> 平坦化の処理
ああ、なるほど。
Series.to_list()の方がいいですね。短く済みますね。
Thanxです。
>cametan様
Pythonでのプログラミングのやり方の説明、ありがとうございました。
2つ目と合わせて、大作だと思います。
私は最近pythonを始めたばかりですが、頑張ります。
頑張ってください。
多分貴方はセンスがあるんで、教えられた事柄をそのまま鵜呑みにするんじゃなく、「ホントはもっとラクなやり方があるんじゃないの?」とか、常に「疑いを持って」学んだ方が上達すると思います。
0
ちと愚痴るな。
これは貴方(投稿者: yyicp氏)に付いて怒ってるわけじゃない、ってのを最初に言っておこう。
日本でPythonが流行りだしたのは、ザックリ言うと2015年以降なんだ。それ以前だと日本じゃ極端に知名度が低く、例えば「今からプログラミングを初めたいんでけど何の言語がいいですか?」と言う良くある定形質問に「Pythonがいいですよ」って答えても無視される傾向があった(僕もそう言ってた)。
大体、「プログラミングを今から初めたい」人は前提知識もなく、出来れば「ちょっとは聞いたことがある」プログラミング言語で始めたい、と。しかし、前提知識が無いクセに、「聞いたことがないような言語」はやっぱ拒否する傾向にあるんだ(そして言わんこっちゃない、C/C++とかJavaから始めて玉砕する)。
それくらいPythonは日本じゃマイナーだったんだ。
そもそも、当時はまだPython2.xがブイブイ言ってた頃で、外部ライブラリもPython2.xの方が多かったんだけど、一方、文字列処理に爆弾を抱えてたんだよ。要は「日本語を表示したい」プログラムだとPython2.xは「意味不明のバグ」に見舞われる事が多かったんだ。
そんなんで、当時の日本ではPythonは人気がなかった。人気が出たのは、文字列処理の根本に、本格的にUTF-8を採用したPython3.xのライブラリが揃いだしてから、なんだ。
めでたしめでたし・・・・・・たぁならんかったんだよ。
2015年以降、貴方が採用したPandasとかNumpyとか、あるいは最近だとscikit-learnみたいなPythonの外部ライブラリ(つまり標準添付のライブラリじゃない)を使った質問が急増した。
「別に外部ライブラリを使う事自体は悪い事じゃないんじゃない?」
と問われればそれはその通り、なんだ。
しかし問題は、本来だったらPythonのエキスパートが使うような外部ライブラリを使ってる割には妙に稚拙なコードが投稿されるようになったって事なんだ。
言っちゃえば、トーシロが背伸びしたようなコードの投稿が急増したんだ。
貴方の書いたコードもこれに当たる。
繰り返すが誤解しないで欲しい。怒ってる、とか侮蔑してる意図はない、んだ。
いや、怒ってるとか侮蔑してるとすれば、それは貴方に対してじゃない、Pythonを使ってプログラミングを教えてる、ってのたまってる層に激怒してんだ。
つまり、貴方は被害者、であって加害者は別にいる。
昨今のPythonを使ったプログラミング教育、ってのはホント悪質なんだ。結果、僕なんかは既に「プログラミングを今から学ぶヤツはPythonを避けろ」って言うようになっちゃった。趣旨替えだな。かつてと180度意見が変わっちまった。
確かにPython+外部ライブラリを使えば「かつては難しかった」プログラミングを比較的ラクに行える。
一方、観測範囲だと
- Pythonを使えばxxが簡単に出来ます!と宣伝する。(☓☓の中身は「データサイエンス」だったり「機械学習」だったりする)
- しかし、Pythonそのものの全体像は教えない
- それどころが、「Pythonでどうやってプログラムを組むのか」は教えない
- もっと言っちゃうと、一般論としての「プログラムの書き方」さえ教えない
- 結果「特定の外部ライブラリの使い方」だけ教える
こんなもん「プログラミング教育でも何でもねぇだろ」とか思うんだが、Python界隈ではこれがフツーになってんだ。
そもそも「プログラムの書き方を知らんのに」pandasとかnumpyの使い方だけ習熟する、ってのはおかしいだろ。そんなこたぁ不可能なんだけど、どこの専門学校か大学か、はたまたWebサイト(例えばPaizaとか?)か知らんが、「プログラミングの仕方が良く分かってない」けど、pandasとかnumpyとかscikit-learn等を「使おうとする」人間を量産してんだ。
そしてもう一つ問題がある。
そもそも、pandasとかnumpyとか、scikit-learnの「使い方が分からなかった」としよう。
これは「Pythonの質問になるのか?」って言うと、厳密な意味では違うんだ。仮に貴方がこのテの質問を、例えばPython公式に投げたとしても答えが得られるかどうか分からん性質の問題なんだよ。
言い換えると、外部ライブラリは外部ライブラリ提供元に質問すべきなんだ。
その方が確実だ。
- pandas(公式): stackoverflow
- Numpy(公式): メーリングリスト
- scikit-learn(公式): メーリングリスト
ところが、こういう頭の中が軽はずみな教育機関ってまずは「質問先」を教えない、んだ。「外部ライブラリを使えば簡単に☓☓出来る」って事だけ強調して、「じゃあトラブルが起きたら?」に対する対応策を提示しない。
例えばこの他にも安易なGoogle Colabの推奨だとか、だよな。これでトラブってどれだけGoogle Colab以外に質問が投下された事か(笑)。「Google Colabからローカル環境にアクセスしようとする」とか(笑)。最初に「それは不可能だと教えろよ」とか思うんだけど、とにかく現在のPython教育周りは「簡単」だけ強調してて、初心者をクッソ面倒くさい状況に陥らせて害毒を振りまいてるんだ。
ちなみに、上の「質問先」参照してみれば「英語だ!」って思うだろ?外部ライブラリに対する質問だと英語での投稿を覚悟しなきゃいけないんだよ。それも教わってないだろ(笑)?
だからプログラミング初心者に「簡単だ!」って宣伝してるけど、蓋を開けてみると「余計に面倒くさくなる」事が山ほどあるんだ、今の「Pythonに於ける教育」だと。
繰り返す、貴方はこのテの「自称教育機関」の被害者だ。
まずプログラミングのコツ、ってのはとにかく関数を書くってのが第一歩だ。貴方の書いてコードを見てみると関数を全く定義していない。これじゃ往年のFortranとかBASICのプログラムだ。
まるで1950年代のプログラムだ。
貴方のせいではない(教わっていないから)が、こういう「関数を定義しない」プログラムをバッチ式プログラムと呼んで、上にも書いたpandasとかnumpyの「ザックリとした使い方」しか教わって来なかった人は貴方に限らずバッチ式プログラムを書く事が多いんだ(反面、プログラミングのエキスパートはこういうバッチ式のプログラムは基本書かない)。
関数を書く、って事は問題を小分けするって観点を持つ事なんだ。「小さくて解けそうな部分的な解」を組み合わせて行ってよりデカい問題を解決する、って方向性を得る。
まぁ、実際は、「それは理論的な話であってそうそう上手く行かない」歴史の積み重ねではあるんだけどね。これは「プロのプログラマさえそうそう"分ける"事は得意じゃない」って歴史に裏打ちされている。最初は関数で小分けすれば綺麗になるんじゃないの?って1960年代半ばに「構造化プログラミング」ってプログラミング言語実装の方法が提示されたんだけど、実際起きたのは「ジャンクな関数だらけの」プログラムの量産であり、「こりゃマズい」ってぇんで今度は「区分けの基準をデータ型にしよう」ってやったんだけど、それも上手く行かなかった(笑)。後者は「言語の問題じゃねぇだろ」ってぇんで「デザインパターン」と言う考え方を人々に紹介して、何とかなってるわけだ。
しかし「データを基準としたプログラム構造の分割」・・・こういうのをオブジェクト指向って言うんだけど、それはちとムズいんで、最初は「関数での分割」に慣れるべきだ。
余談だけど、是非ともこの本を読んでみて欲しい。Windows上でのプログラミングとは合わない部分もあるが、「プログラミングをする際」の重要な指針に付いて書かれている。かつ、この本はプログラミングの本ではない。
ここで取り上げられているプログラム、大雑把に言うと関数の事、だけど書き方は
- スモール・イズ・ビューティフル
- 一つのプログラム(関数)には一つのことをうまくやらせる
ってのが原則だ。まず問題を小分けしていって「一番小さい、何てことのないプログラム(関数)から書き始める」ってのが方針だ。
あと、別の本になるけど、「一つの関数は12行以内に抑えよ」ってのもある。12行って何?に対してはスクリーンエディタ(及びIDE)で、画面スクロールせずに一気に表示出来るだろう上限だ。
とにかく小さい「部品」を作っていってそれを「組み合わせる」ように書け、って事だ。
この観点から言うと、次のような一見バカっぽいプログラムでさえ有用だ、って事だ。
Python
1def add1(x): 2 return x + 1 3 4def sub1(x): 5 return x - 1 6 7def isNull(x): 8 return x == [] 9 10def isNone(x): 11 return x == None 12 13def isZero(x): 14 return x == 0 15
殆ど何もしていない、に等しい関数だけど、スモール・イズ・ビューティフルと一つのプログラム(関数)には一つのことをうまくやらせるには適合している。
そしてこの段階から徐々に「自作ユーティリティ」(自分専用のライブラリ)は育ってくんだ。
もちろん、ここではもっと便利なPythonの組み込みユーティリティを使っていく作戦を取るが、いずれにせよ、こういう「何てことのない簡単な関数を書く」と言うのは別段恥ずかしい事でも何でもない。ガンガン「小さい関数」を書いていこう。
なお、ここで気をつけて欲しい事は
- 関数を書く際には入出力を混ぜるな
- とにかく計算結果を
returnしろ
の二点だ。
さて、「小さい関数から書いていく」と言う方針を確かめた後で、もう一回貴方の質問文を見てみる。
各塊は、
x座標
y座標
z座標
値
の順番に並んでいます。
「手動」の内容は、
y座標=y座標ー(一番最初の塊のy座標)
z座標=z座標ー(一番最初の塊のz座標)
です。
貴方のいいところは、実は問題をキチンと把握してる辺りだ。
これが「全く方針を立てられない」人だと次も本文に混ぜてるだろう。
sample_after20.txtとsample_after30.txtを保存する方法もよく分かりませんでした。
実は後者は入出力の問題であって、この辺は「あとでどーにでもなる」範疇なんだ。
C言語なんかだと出力しまくらないと何を計算してるのかサッパリ分からん(見えない)ので要出力にせざるを得ない構造的欠陥があるんだけど、Pythonは入出力を計算ロジックから切り離しやすい構造になっている。
さて、その計算ロジックへと入っていくけど、実はこの辺で気づかなきゃならない事は、汎用的に考えるとこの部分、pandasもnumpyも関係ないんだ。
問題の本質は、二次元リスト[[5, 29, 57, 8], [5, 29, 58, 4], [5, 30, 58, 1]]に対して[[5, 0, 0, 8], [5, 0, 1, 4], [5, 1, 1, 1]]と言う二次元リストを生成せよ、って事なんだ。
Python
1[[5, 29, 57, 8], [5, 29, 58, 4], [5, 30, 58, 1]] 2-> 計算操作 -> 3[[5, 0, 0, 8], [5, 0, 1, 4], [5, 1, 1, 1]]
つまり、何らかの数値αとβがあった場合、各要素(リスト)にこういう計算操作を施せばいい、って事だ。
Python
1[[5, 29 - α, 57 - β, 8], [5, 29 - α, 58 - β, 4], [5, 30 - α, 58 - β, 1]]
ここでαとβは実は何でも良いってのがポイントだ。問題的にはαは与えられた二次元リストの第0要素(リスト)の第1要素、βは与えられた二次元リストの第0要素(リスト)の第2要素だけどその辺の束縛はどうでもなるだろう。
このような、リストの各要素に同じ計算を施す場合、一番簡単なテはリスト内包表記を使う事だ。
Python
1#!/usr/bin/env python3 2 3from functools import reduce 4 5def foo(lst, i = 0, j = 1, k = 2): 6 ''' 7二次元リストの内側のリストはx座標、y座標、z座標、値で構成されている。 8各要素(リスト)に対してy座標 - i番目のy座標、z座標 - i 番目のz座標の計算を施す。 9''' 10 alpha, beta = lst[i][j], lst[i][k] 11 # 要素(リスト)をアンパック(要素へと分解)しながら計算を施す 12 return [[x, y - alpha, z - beta, v] for x, y, z, v in lst] 13 14if __name__ == '__main__': 15 lst = [[5, 29, 57, 8], [5, 29, 58, 4], [5, 30, 58, 1]] 16 print(foo(lst)) 17 lst = [[6, 28, 57, 5], [6, 29, 57, 8]] 18 print(foo(lst)) 19
デフォルト引数でi = 0、j = 1、k = 2としてるが、その後
Python
1alpha, beta = lst[i][j], lst[i][k]
でalphaとbetaに実際の値を束縛する。
あとはリスト内包表記を使って各要素(リスト)の第1要素と第2要素に対して同じ計算を施せばいい。
Python
1## 実行結果 2[[5, 0, 0, 8], [5, 0, 1, 4], [5, 1, 1, 1]] 3[[6, 0, 0, 5], [6, 1, 0, 8]]
これで問題の90%くらいは解けた事となる。リスト内包表記を使えば、たった二行程度で目的の計算ロジックが書ける事に注目しよう。原則、長いコードより短いコードの方が処理を把握しやすい(異論がある人もいるけど)。
あとは入出力を考えればいいだけ、だ。
投稿2025/08/04 05:00
編集2025/08/04 16:46総合スコア217
あなたの回答
tips
太字
斜体
打ち消し線
見出し
引用テキストの挿入
コードの挿入
リンクの挿入
リストの挿入
番号リストの挿入
表の挿入
水平線の挿入
プレビュー
質問の解決につながる回答をしましょう。 サンプルコードなど、より具体的な説明があると質問者の理解の助けになります。 また、読む側のことを考えた、分かりやすい文章を心がけましょう。



2025/08/07 08:14