
メタな質問で恐縮です。
今回の質問のような、特殊な形式のファイルの内容を操作することに関する質問をたくさんされていますが、どのような目的でそのような処理をされているのでしょうか?
仕事でこのようなデータを扱っていて必要だから、とか、pythonの学習が目的、とか、加えてnumpyとかpandasが使えるようになりたい、など。
実現したいこと
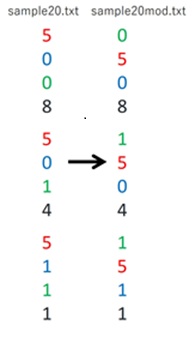
下図のように数字を並び替えて、sample20.txtからsample20mod.txtを作りたいと考えています。
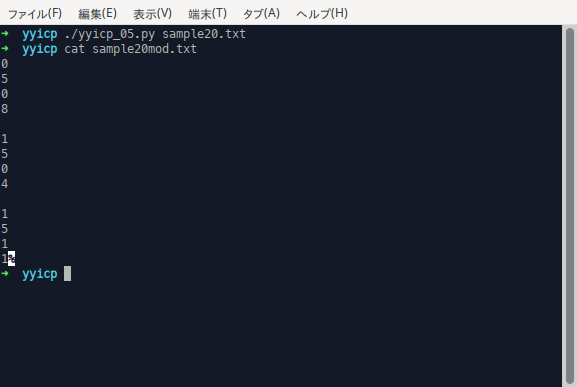
実行すると、以下の画面が表示されます。blkoldの値は正しいですが、blknewの値は正しくありません。どのように直したら良いでしょうか。
blkold [[5] [0] [0] [8]] blknew [[0] [0] [0] [8]] blkold [[5] [0] [1] [4]] blknew [[0] [1] [0] [4]] blkold [[5] [1] [1] [1]] blknew [[1] [1] [1] [1]]
該当のソースコード
data_filesの中身は今は1つですが、たくさんある状態を想定しています。
python
1import numpy as np 2import pandas as pd 3 4data_files = ['sample20.txt'] 5 6for f in data_files: 7 newname = os.path.splitext(f)[0] + 'mod.txt' 8 g = open(newname,'w') 9 10 for blk in pd.read_csv(f, header=None, chunksize=4): 11 blk = blk.to_numpy() 12 print('blkold') 13 print(blk) 14 blk[0], blk[1], blk[2] = blk[1], blk[2], blk[0] 15 print('') 16 print('blknew') 17 print(blk) 18 print('') 19 20 for i in range(0,4,1): 21 g.write(str(blk[i])+'\n') 22 if i == 3: 23 g.write('\n')
試したこと
14行目が間違っているだろうと思っていますが、どのように直したら良いか分かりませんでした。
回答4件
あなたの回答
tips
プレビュー


