
Top2Vec の issues を見ると同じ問題の報告が上がっています。
ValueError: need at least one array to concatenate · Issue #216 · ddangelov/Top2Vec
https://github.com/ddangelov/Top2Vec/issues/216
結論としては、
> You need more documents, that will solve the problem.
だそうです。
前提
現在小説のテキストデータと著者名をカラムとした以下のようなデータフレームにtolist関数を用いて、テキストデータのみを抽出したものを機械学習モデルに与えました。

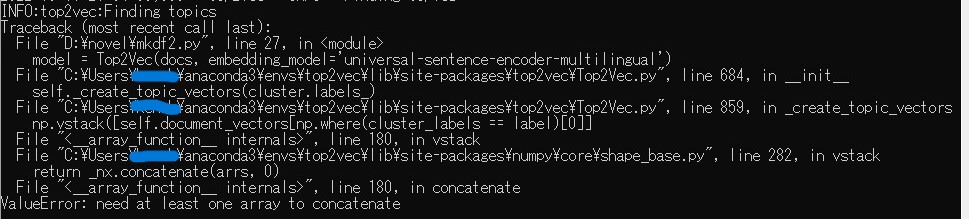
しかし配列が必要とエラーが出てしまい、検索しても同じような例が見つからず困っています。
何が悪いのか知恵をお借りしたいです。
実現したいこと
学習の実装
発生している問題・エラーメッセージ
消しているのはユーザー名の部分です。
該当のソースコード
Python
1import glob 2import pandas as pd 3 4names, texts = [], [] 5for path in glob.glob(r'.\select\*\*.txt'): 6 name = path.split('\\')[-2] # 作者 7 names.append(name) 8 texts.append(path) # ファイル名をセット 9 10df = pd.DataFrame({'names':names, 'text':texts}) 11 12def file_read(path): 13 with open(path, "r") as f: 14 ret = f.read() 15 return ret 16 17df["text"] = df["text"].apply(file_read) 18 19print(df) 20 21 22 23docs = df.text.tolist() 24 25from top2vec import Top2Vec 26 27model = Top2Vec(docs, embedding_model='universal-sentence-encoder-multilingual')
試したこと
まだ試してはいないのですが、とりあえず文章を形態素解析で分かち書きに直したものを与えればもしかしたらと思い試行中です。
補足情報(FW/ツールのバージョンなど)
anacondaでPython3.9を使用しています。
回答1件
あなたの回答
tips
プレビュー


