
質問編集履歴
2
コード追記 、文の追記
title
CHANGED
|
File without changes
|
body
CHANGED
|
@@ -10,10 +10,10 @@
|
|
|
10
10
|
### 発生している問題・エラーメッセージ
|
|
11
11
|
|
|
12
12
|
|
|
13
|
-
|
|
13
|
+
追記していただいたy[i].argmax()でエラーなく動くようになりました。
|
|
14
|
-
|
|
14
|
+
しかし、画像にあるよう学習の進行度を表すゲージが表示されておらず1エポックも終わらない状態になってしまいました。
|
|
15
15
|
|
|
16
|
-

|
|
17
17
|
|
|
18
18
|
### 該当のソースコード
|
|
19
19
|
|
|
@@ -81,8 +81,10 @@
|
|
|
81
81
|
y_test=np.vstack([y_test,np.full((b_test_data.shape[0],1),[1])])
|
|
82
82
|
y_test=np.vstack([y_test,np.full((c_test_data.shape[0],1),[2])])
|
|
83
83
|
|
|
84
|
+
from tensorflow.keras.utils import to_categorical
|
|
85
|
+
y_train = to_categorical(y_train,3)
|
|
86
|
+
y_test = to_categorical(y_test,3)
|
|
84
87
|
|
|
85
|
-
|
|
86
88
|
## 変換処理
|
|
87
89
|
x_datagen_base = ImageDataGenerator(
|
|
88
90
|
rescale = 1 / 255,
|
|
@@ -108,7 +110,7 @@
|
|
|
108
110
|
def myflow(gen: ImageDataGenerator):
|
|
109
111
|
for x, y in gen:
|
|
110
112
|
for i, _x in enumerate(x):
|
|
111
|
-
if y[i] != 0:
|
|
113
|
+
if y[i].argmax() != 0:
|
|
112
114
|
x[i] = x_datagen_base.apply_transform(
|
|
113
115
|
_x,
|
|
114
116
|
x_datagen_partial.get_random_transform(_x.shape)
|
|
@@ -116,10 +118,8 @@
|
|
|
116
118
|
yield x, y
|
|
117
119
|
|
|
118
120
|
|
|
119
|
-
from tensorflow.keras.utils import to_categorical
|
|
120
|
-
y_train = to_categorical(y_train,3)
|
|
121
|
-
y_test = to_categorical(y_test,3)
|
|
122
121
|
|
|
122
|
+
|
|
123
123
|
from tensorflow.python.keras.models import Sequential
|
|
124
124
|
model = Sequential()
|
|
125
125
|
|
|
@@ -240,7 +240,7 @@
|
|
|
240
240
|
loss = history_model.history['loss'] #訓練データの誤差
|
|
241
241
|
val_loss = history_model.history['val_loss'] #テストデータ誤差
|
|
242
242
|
accuracy = history_model.history['accuracy'] #訓練データの誤差
|
|
243
|
-
val_accuracy = history_model.history['val_accuracy'] #テストデータ誤差
|
|
243
|
+
val_accuracy = history_model.history['val_accuracy'] #テストデータ誤差
|
|
244
244
|
```
|
|
245
245
|
|
|
246
246
|
### 試したこと
|
|
@@ -254,4 +254,4 @@
|
|
|
254
254
|
TensorFlow 2.3
|
|
255
255
|
Spyder 5.3.3を利用
|
|
256
256
|
|
|
257
|
-
トレーニングデータはもっとあるのですが、省
|
|
257
|
+
トレーニングデータはもっとあるのですが、省略させていただきました。
|
1
コードの追加、画像の追加、文の追加
title
CHANGED
|
File without changes
|
body
CHANGED
|
@@ -1,58 +1,257 @@
|
|
|
1
1
|
### 前提
|
|
2
2
|
|
|
3
3
|
|
|
4
|
-
|
|
4
|
+
|
|
5
|
-
|
|
5
|
+
三項目の分類をしようとしており、三項目の内一つだけ正規化し他の二項目はいろいろな変換処理をできるようにしたいです。
|
|
6
6
|
### 実現したいこと
|
|
7
|
-
|
|
7
|
+
|
|
8
|
-
または
|
|
9
8
|
・ImageDatageneratorの変換を行う項目と行わない項目を作る
|
|
10
9
|
|
|
11
10
|
### 発生している問題・エラーメッセージ
|
|
12
11
|
|
|
13
|
-
```
|
|
14
12
|
|
|
15
|
-
|
|
13
|
+
One-Hot Encodingの前にmyflowを書いていたのでエラーが出ていたのですが、後に書くことでエラーはなくなりました。
|
|
16
|
-
|
|
14
|
+
でも、画像にあるよう学習の進行度を表すゲージが表示されておらず学習が進まないため1エポックも終わらない状態になってしまいました。
|
|
17
15
|
|
|
16
|
+

|
|
17
|
+
|
|
18
18
|
### 該当のソースコード
|
|
19
19
|
|
|
20
20
|
```python
|
|
21
|
+
import numpy as np
|
|
22
|
+
from PIL import Image
|
|
23
|
+
import tensorflow as tf
|
|
24
|
+
import time
|
|
25
|
+
import matplotlib.pyplot as plt
|
|
26
|
+
# import os
|
|
27
|
+
# os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
|
|
28
|
+
from tensorflow.keras.models import Model
|
|
29
|
+
from tensorflow.keras.preprocessing import image
|
|
30
|
+
from tensorflow.keras.preprocessing.image import ImageDataGenerator
|
|
31
|
+
from tensorflow.keras.optimizers import Adam
|
|
32
|
+
from tensorflow.keras.callbacks import EarlyStopping, LearningRateScheduler,ReduceLROnPlateau, ModelCheckpoint
|
|
33
|
+
|
|
34
|
+
Image.MAX_IMAGE_PIXELS = None
|
|
35
|
+
|
|
36
|
+
#-------切り取り定義-------
|
|
37
|
+
def kiritori(img):
|
|
38
|
+
img_array=np.array(img,dtype='int16') #(50行,83列,3次元)の3次元配列
|
|
39
|
+
a=np.split(img_array,img.height/50)
|
|
40
|
+
img_data=np.split(a[0],img.width/50,axis=1)#stackする土台づくり
|
|
41
|
+
for i in range(len(a)-1):
|
|
42
|
+
img_data=np.vstack([img_data,np.split(a[i+1],img.width/50,axis=1)])
|
|
43
|
+
|
|
44
|
+
return img_data
|
|
45
|
+
|
|
46
|
+
#-------切り取り処理(トレーニングデータ)-------
|
|
47
|
+
x_train=kiritori(Image.open('3Gatu_Data/DJI_0708.JPG'))#(#(1200,100,100,3)
|
|
48
|
+
|
|
49
|
+
train_label=np.loadtxt(fname='label/3Gatu_708_50.csv',delimiter=',',dtype='int16')#(30, 40)
|
|
50
|
+
train_label=np.reshape(train_label,(train_label.size)) #(1200)
|
|
51
|
+
|
|
52
|
+
a_train_data = x_train[np.where(train_label==0)]
|
|
53
|
+
b_train_data =x_train[np.where(train_label==1)]
|
|
54
|
+
c_train_data =x_train[np.where(train_label==2)]
|
|
55
|
+
|
|
56
|
+
|
|
57
|
+
#-------データをまとめる-------
|
|
58
|
+
x_train=a_train_data
|
|
59
|
+
x_train=np.vstack([x_train,b_train_data])
|
|
60
|
+
x_train=np.vstack([x_train,c_train_data])
|
|
61
|
+
|
|
62
|
+
#-------テストデータ処理-------
|
|
63
|
+
val_test=kiritori(Image.open('3Gatu_Data/mai_0330_2022.JPG'))
|
|
64
|
+
|
|
65
|
+
test_label=np.loadtxt(fname='label/3Gatu_mai_50.csv',delimiter=',',dtype='int16')#(30,40)
|
|
66
|
+
test_label=np.reshape(test_label,(test_label.size)) #(1200)
|
|
67
|
+
|
|
68
|
+
a_test_data = val_test[np.where(test_label==0)]
|
|
69
|
+
b_test_data = val_test[np.where(test_label==1)]
|
|
70
|
+
c_test_data = val_test[np.where(test_label==2)]
|
|
71
|
+
|
|
72
|
+
val_test = a_test_data
|
|
73
|
+
val_test = np.vstack([val_test,b_test_data])
|
|
74
|
+
val_test = np.vstack([val_test,c_test_data])
|
|
75
|
+
|
|
76
|
+
y_train=np.full((a_train_data.shape[0],1),0)
|
|
77
|
+
y_train=np.vstack([y_train,np.full((b_train_data.shape[0],1),[1])])
|
|
78
|
+
y_train=np.vstack([y_train,np.full((c_train_data.shape[0],1),[2])])
|
|
79
|
+
|
|
80
|
+
y_test=np.full((a_test_data.shape[0],1),[0])
|
|
81
|
+
y_test=np.vstack([y_test,np.full((b_test_data.shape[0],1),[1])])
|
|
82
|
+
y_test=np.vstack([y_test,np.full((c_test_data.shape[0],1),[2])])
|
|
83
|
+
|
|
84
|
+
|
|
85
|
+
|
|
86
|
+
## 変換処理
|
|
87
|
+
x_datagen_base = ImageDataGenerator(
|
|
88
|
+
rescale = 1 / 255,
|
|
89
|
+
dtype = np.float64
|
|
90
|
+
)
|
|
91
|
+
|
|
92
|
+
|
|
21
|
-
|
|
93
|
+
x_datagen_partial = image.ImageDataGenerator(
|
|
22
94
|
rescale = 1./255,
|
|
23
95
|
rotation_range = 180,
|
|
24
96
|
fill_mode="constant",
|
|
25
97
|
vertical_flip = True,
|
|
26
|
-
brightness_range = [0.7, 1.117],
|
|
98
|
+
# brightness_range = [0.7, 1.117],
|
|
27
|
-
horizontal_flip = True
|
|
99
|
+
horizontal_flip = True,
|
|
100
|
+
dtype = np.float64
|
|
28
101
|
)
|
|
29
102
|
|
|
30
|
-
x_train_generator =
|
|
103
|
+
x_train_generator = x_datagen_base.flow(x_train, y_train, batch_size= 13)
|
|
31
104
|
|
|
32
|
-
x_train_gen2 = image.ImageDataGenerator(rescale=1./ 255)
|
|
33
|
-
x_train_generator2 = x_train_datagen.flow(x_train2, y_train2, batch_size= 13)
|
|
34
|
-
|
|
35
|
-
|
|
36
105
|
val_datagen = image.ImageDataGenerator(rescale=1./ 255)
|
|
37
106
|
val_test_generator = val_datagen.flow(val_test, y_test,batch_size = 13)
|
|
38
107
|
|
|
108
|
+
def myflow(gen: ImageDataGenerator):
|
|
109
|
+
for x, y in gen:
|
|
110
|
+
for i, _x in enumerate(x):
|
|
111
|
+
if y[i] != 0:
|
|
112
|
+
x[i] = x_datagen_base.apply_transform(
|
|
113
|
+
_x,
|
|
114
|
+
x_datagen_partial.get_random_transform(_x.shape)
|
|
115
|
+
)
|
|
116
|
+
yield x, y
|
|
117
|
+
|
|
118
|
+
|
|
119
|
+
from tensorflow.keras.utils import to_categorical
|
|
120
|
+
y_train = to_categorical(y_train,3)
|
|
121
|
+
y_test = to_categorical(y_test,3)
|
|
122
|
+
|
|
123
|
+
from tensorflow.python.keras.models import Sequential
|
|
124
|
+
model = Sequential()
|
|
125
|
+
|
|
126
|
+
from tensorflow.python.keras.layers import Conv2D
|
|
127
|
+
from tensorflow.keras.layers import PReLU
|
|
128
|
+
from tensorflow.python.keras.layers import BatchNormalization
|
|
129
|
+
model.add( #畳み込み
|
|
130
|
+
Conv2D(
|
|
131
|
+
filters=64, #出力
|
|
132
|
+
input_shape=(50,50,3),
|
|
133
|
+
kernel_size=(3,3), #フィルタサイズ
|
|
134
|
+
strides=(1,1),
|
|
135
|
+
padding='valid',
|
|
136
|
+
kernel_initializer = "he_uniform"
|
|
137
|
+
))
|
|
138
|
+
|
|
139
|
+
model.add(BatchNormalization())
|
|
140
|
+
model.add(PReLU(alpha_initializer=tf.constant_initializer(0.25)))
|
|
141
|
+
|
|
142
|
+
|
|
143
|
+
from tensorflow.python.keras.layers import MaxPooling2D
|
|
144
|
+
from tensorflow.python.keras.layers import Dropout
|
|
145
|
+
|
|
146
|
+
|
|
147
|
+
model.add(MaxPooling2D(pool_size=(2,2))) #マックスプーリング
|
|
148
|
+
#ドロップアウト
|
|
149
|
+
|
|
150
|
+
#追加畳み込み
|
|
151
|
+
model.add(
|
|
152
|
+
Conv2D(
|
|
153
|
+
filters =128,
|
|
154
|
+
kernel_size = (3,3),
|
|
155
|
+
strides = (1,1),
|
|
156
|
+
padding = 'valid',
|
|
157
|
+
kernel_initializer = "he_uniform",
|
|
158
|
+
))
|
|
159
|
+
|
|
160
|
+
model.add(BatchNormalization())
|
|
161
|
+
model.add(PReLU(alpha_initializer=tf.constant_initializer(0.25)))
|
|
162
|
+
|
|
163
|
+
|
|
164
|
+
model.add(MaxPooling2D(pool_size=(2,2)))
|
|
165
|
+
|
|
166
|
+
|
|
167
|
+
#追加畳み込み
|
|
168
|
+
model.add(
|
|
169
|
+
Conv2D(
|
|
170
|
+
filters = 256,
|
|
171
|
+
kernel_size = (3,3),
|
|
172
|
+
strides = (1,1),
|
|
173
|
+
padding = 'valid',
|
|
174
|
+
kernel_initializer = "he_uniform",
|
|
175
|
+
))
|
|
176
|
+
|
|
177
|
+
model.add(BatchNormalization())
|
|
178
|
+
model.add(PReLU(alpha_initializer=tf.constant_initializer(0.25)))
|
|
179
|
+
|
|
180
|
+
model.add(MaxPooling2D(pool_size=(2,2)))
|
|
181
|
+
|
|
182
|
+
|
|
183
|
+
#追加畳み込み
|
|
184
|
+
model.add(
|
|
185
|
+
Conv2D(
|
|
186
|
+
filters = 512,
|
|
187
|
+
kernel_size = (3,3),
|
|
188
|
+
strides = (1,1),
|
|
189
|
+
padding = 'valid',
|
|
190
|
+
kernel_initializer = "he_uniform",
|
|
191
|
+
))
|
|
192
|
+
|
|
193
|
+
model.add(BatchNormalization())
|
|
194
|
+
model.add(PReLU(alpha_initializer=tf.constant_initializer(0.25)))
|
|
195
|
+
|
|
196
|
+
model.add(MaxPooling2D(pool_size=(2,2)))
|
|
197
|
+
|
|
198
|
+
|
|
199
|
+
from tensorflow.python.keras.layers import Flatten
|
|
200
|
+
model.add(Flatten()) #2次元配列に
|
|
201
|
+
|
|
202
|
+
from tensorflow.python.keras.layers import Dense
|
|
203
|
+
|
|
204
|
+
model.add(Dense(units=1536))
|
|
205
|
+
|
|
206
|
+
model.add(PReLU(alpha_initializer=tf.constant_initializer(0.25)))
|
|
207
|
+
|
|
208
|
+
model.add(Dropout(0.5))
|
|
209
|
+
model.add(Dense(units=3,activation='softmax',name="f3"))
|
|
210
|
+
|
|
211
|
+
model.summary();
|
|
212
|
+
|
|
213
|
+
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=10, min_lr=0.0001)
|
|
214
|
+
|
|
215
|
+
model.compile(
|
|
216
|
+
optimizer = Adam(), #自動で学習率が設定される
|
|
217
|
+
loss = 'categorical_crossentropy', #多分類のときにしていできる交差エントロピー
|
|
218
|
+
metrics = ['accuracy']
|
|
219
|
+
)
|
|
220
|
+
|
|
39
221
|
history_model = model.fit(
|
|
40
|
-
x_train_generator,
|
|
222
|
+
myflow(x_train_generator),
|
|
41
223
|
epochs = 10,
|
|
42
224
|
validation_data = val_test_generator,
|
|
43
225
|
validation_steps = None,
|
|
44
226
|
shuffle = True,
|
|
45
227
|
callbacks = [reduce_lr]
|
|
46
228
|
)
|
|
229
|
+
|
|
230
|
+
## モデルの保存
|
|
231
|
+
model_json_str = model.to_json()
|
|
232
|
+
open('Output_file/9/cnn_model_3Gatu_50_500.json', 'w').write(model_json_str)
|
|
233
|
+
model.save_weights('Output_file/9/mnist_mlp_3Gatu_50_500_weights2.h5');
|
|
234
|
+
|
|
235
|
+
score = model.evaluate( val_test_generator, verbose=0)
|
|
236
|
+
print('Test loss :', score[0])
|
|
237
|
+
print('Test accuracy :', score[1])
|
|
238
|
+
|
|
239
|
+
|
|
240
|
+
loss = history_model.history['loss'] #訓練データの誤差
|
|
241
|
+
val_loss = history_model.history['val_loss'] #テストデータ誤差
|
|
242
|
+
accuracy = history_model.history['accuracy'] #訓練データの誤差
|
|
243
|
+
val_accuracy = history_model.history['val_accuracy'] #テストデータ誤差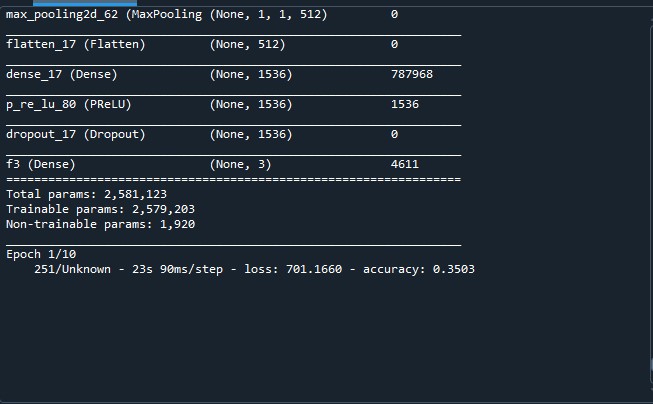
|
|
47
244
|
```
|
|
48
245
|
|
|
49
246
|
### 試したこと
|
|
50
247
|
|
|
51
|
-
|
|
248
|
+
myflowの適用をしてみました。
|
|
52
249
|
|
|
53
250
|
### 補足情報(FW/ツールのバージョンなど)
|
|
54
|
-
|
|
251
|
+
windows11(64bit)
|
|
55
252
|
anacondaを使用
|
|
56
253
|
python 3.8.13
|
|
57
254
|
TensorFlow 2.3
|
|
58
255
|
Spyder 5.3.3を利用
|
|
256
|
+
|
|
257
|
+
トレーニングデータはもっとあるのですが、省力させていただきました。
|