単純に重複するyearを除去したいだけならdrop_duplicatesでよいかと思いますが
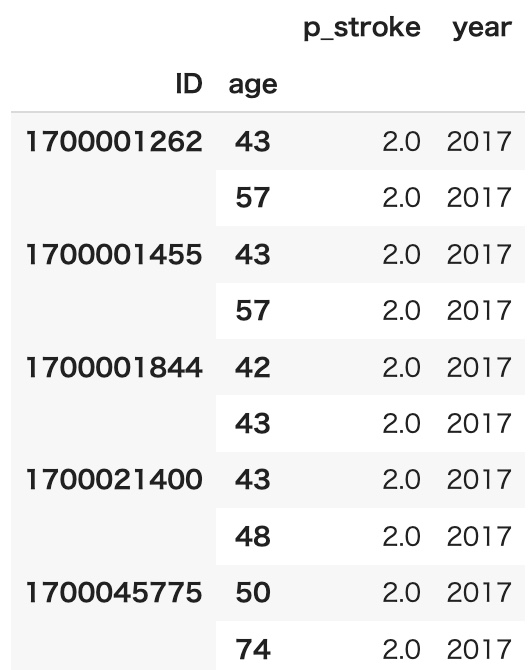
年齢ageと計測年yearが乖離してしまっています
とあるように、両者に何らかの制約条件があるなら、その条件で絞る(さらに重複していたらdrop_する)とよいです。
あるいは、同じyearが複数存在するID(複数)行全体を削除することもできます。
Python
1
2import pandas as pd
3from io import StringIO
4
5s = """ID,age,year
61,10,2012
71,11,2011
82,20,2000
92,22,2000"""
10df = pd.read_csv(StringIO(s), index_col=['ID','age'])
11print(df)
12"""
13 year
14ID age
151 10 2012
16 11 2011
172 20 2000
18 22 2000
19"""
20
21# 単純に重複を除去
22df2 = df.drop_duplicates('year')
23print(df2)
24"""
25 year
26ID age
271 10 2012
28 11 2011
292 20 2000
30"""
31
32# ageとyearに「age+year=2022」なりの何らかの制約条件があるなら
33filter = (df.index.get_level_values(1) + df['year'] == 2022)
34df2 = df[filter]
35print(df2)
36"""
37 year
38ID age
391 10 2012
40 11 2011
412 22 2000
42"""
43
44# yearが重複しているID(複数)行全体を削除したいなら
45df_g1 = (df.groupby(['ID','year']).size() <= 1) # yearが重複していなければTrue
46df_g2 = (df_g1.groupby('ID').sum() >= 1) # yearが重複していないID行ならTrue
47df_g3 = df_g2[df_g2] # 条件に一致するIDを抽出
48filter = (df.index.get_level_values(0).isin( df_g3.index)) # ID値で抽出
49df2 = df[filter]
50print(df2)
51"""
52ID age
531 10 2012
54 11 2011
55"""





バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2022/06/06 09:06