
結果(計算過程で構築したツリーの)データ例と、その結果グラフ(絵)を示すと回答得られやすいかと思います。
FP-Growthというアルゴリズムを利用してアソシエーションルール分析を行い、その途中で生成されるFP-Treeを図示してくれるプログラムを書こうとしています。
FP-Growthのアルゴリズムについては下記の動画が詳しいです。
youtube
上記の動画と同じように
「入力されたリストと途中まで同じ構造の枝がすでにあるかどうかを調べて、有った場合は共通部分のカウントを増やしつつ新規部分を枝分かれさせて追加し、なかった場合はrootである[NULL]から新しく枝を生やす」
という作業を繰り返してグラフ化したいのですが、これを実現する方法がわかりません。
python
1from collections import defaultdict, Iterator 2import graphviz 3dot = graphviz.Digraph() 4X=[["b","c","a"], 5 ["b","a","d"], 6 ["c"]] 7 8#全く同じ組み合わせのトランザクションを数え、[count,transaction]の二項をもつdbを作る(countで降順ソート) 9 db = ((X.count(transaction), transaction) for transaction in X) 10 11#トランザクション内の要素ごとに出現数を数え、[item:count]の辞書を作る 12 item_support = defaultdict(int) 13 node_support = defaultdict(int) 14 for count, transaction in db: 15 for item in transaction: 16 item_support[item] += count 17 node_support[item] += 1 18 19#辞書から出現数がしきい値以下の要素を切り捨てる 20 frequent_items = {item 21 for item, support in item_support.items() 22 if support >= min_support} 23 24#要素数でtransactionを降順ソートするため、辞書型の(sort_index)を作る 25 sort_index = {item: i 26 for i, item in 27 enumerate(sorted(frequent_items, 28 key=item_support.__getitem__, 29 reverse=True))}.__getitem__ 30#dbのtransaction内部をsort_indexでソートする 31db = [(count, sorted(frequent_items.intersection(transaction), 32 key=sort_index)) for count, transaction in db]
上記のようにグラフ描画用のdbを前処理で作るところまではできたのですが、この後でツリーを走査して枝を分岐させるか新しく生やすかを判断してグラフ描画関数に渡す部分で行き詰っています。
この時点でfrequent_itemsには
| item | support |
|---|---|
| a | 2 |
| b | 2 |
| c | 2 |
| d | 1 |
dbには
| count | transaction |
|---|---|
| 1 | ["a","b","c"] |
| 1 | ["a","b","d"] |
| 1 | ["c"] |
という内容が入っている想定です。
図の出力にはGraphvizを使おうと思っており、graphvizでは
ノードの追加
python
1dot.node("<ノード名>")
ノードの親子関係設定
python
1dot.edge("<親ノード名>","<子ノード名>")
という操作ができるため、これを利用しようと思っています。
期待する出力は下記の通りです。
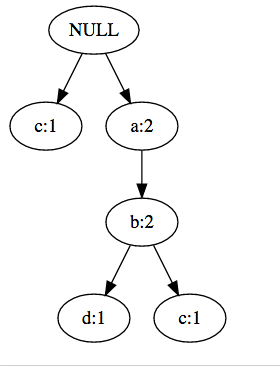
解決法をご存知でしたらご教示ください。


