



データの数がかなり少なかったりしますか? (数百枚未満など)
前提・実現したいこと
Google Coloboratory上で顔コレデータセットに対して4クラス分類を行っています。
Google Drive上のデータセットをImageDataGeneratorなどを用いて取り込み、学習をしようとしています。
発生している問題・エラーメッセージ
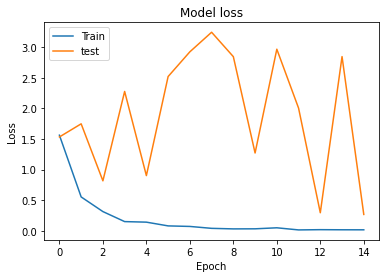
訓練データに対する学習はうまくいっているように思えるのですが、evaluate_generatorで評価した際のlossとグラフから見るlossのグラフの値が明らかに異なるという問題に直面しました。
どのような原因が考えられるでしょうか。また、そのためにはどのような操作が有効でしょうか?

closed accuracy: 0.4878048896789551
open accuracy: 0.47438329458236694
closed loss: 2.028860092163086
open loss: 0.26708337664604187
該当のソースコード
python source code
#データ読み込み部↓↓ from keras.preprocessing.image import ImageDataGenerator from keras.applications.resnet50 import preprocess_input, decode_predictions from keras.applications.resnet50 import ResNet50 from keras.preprocessing import image batch_size = 32 train_datagen = ImageDataGenerator(rotation_range=20,preprocessing_function=preprocess_input, rescale=1.0 / 255) test_datagen = ImageDataGenerator(rescale=1.0 / 255,preprocessing_function=preprocess_input,) train_generator = train_datagen.flow_from_directory( '#自分のドライブのフォルダパス', # kaokore target_size=(224, 224), batch_size=batch_size, class_mode='categorical') test_generator = test_datagen.flow_from_directory( '#自分のドライブのフォルダパス', target_size=(224, 224), batch_size=1, class_mode='categorical') #モデルの作成部 from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense,Conv2D from keras.preprocessing.image import ImageDataGenerator from keras.applications.vgg16 import VGG16 from keras.applications.resnet50 import ResNet50 num_output_channels=32 size_kernel=(2,2) batch_size = 32 epochs = 15 num_classes = 4 #base_model = VGG16(weights='imagenet') #ResNet50の定義 base_model=ResNet50(weights='imagenet',include_top=False,input_shape=(224,224,3)) #上記の層に自作の層を追加 model = Sequential([base_model, Conv2D(num_output_channels, kernel_size = size_kernel,padding='same',activation='relu' ,input_shape=(7,7,2048)), MaxPooling2D(pool_size=(2,2)), Flatten(), Dense(num_classes), Activation('softmax')]) #ResNet50のパラメータのスイッチ用 #base_model.trainable = True base_model.trainable = False #確認用 #base_model.summary() #model.summary() #modelのコンパイル model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) #学習フェーズ %time history = model.fit_generator(train_generator, epochs=epochs,validation_data=test_generator) #modelのセーブ&ロード with open('model.json', 'w') as f: f.write(model.to_json()) model.save_weights('weights.h5') with open('model.json') as f: model = model_from_json(f.read()) model.load_weights('weights.h5') #ロードしたものをもう一度コンパイルする用 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) #評価部 result = model.evaluate_generator(train_generator) print("closed test") print('loss:',result[0]) print('accuracy:',result[1]) result = model.evaluate_generator(test_generator) print("open test") print('loss:',result[0]) print('accuracy:',result[1]) #学習時の様子を可視化 import matplotlib.pyplot as plt plt.plot(history.history['accuracy'],label="training") plt.plot(history.history['val_accuracy'],label="test") plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train','test'], loc='upper left') #plt.ylim(0.2,0.6) #plt.xlim(0,5) plt.show() plt.plot(history.history['loss'],label="training") plt.plot(history.history['val_loss'],label="test") plt.title('Model loss') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['Train','test'], loc='upper left') plt.show()
試したこと
kerasのモデルにはtraining modeとtesting dataが存在し、そのせいで学習時のモデルと評価時のモデルの振る舞いが異なっていることが原因だと考えました。
そのためモデルを保存⇒再ロード⇒評価としてみたのですが、変化なしです。
補足情報(FW/ツールのバージョンなど)
返信ありがとうございます。
以下がコード中の「#データの読み取り部」の結果です。
>Found 533 images belonging to 4 classes.
>Found 527 images belonging to 4 classes.
この結果が示すように、訓練データが533枚、テストデータが527枚です。
内訳は次のようになります。
訓練データ:
0:53枚
1:55枚
2:260枚
3:165枚
テストデータ:
0:63枚
1:48枚
2:250枚
3:166枚
訓練データに対する loss は下がっていて、評価データに対する loss は下がらないということであれば、過学習ではないかとも思えますが、その可能性は排除できているのでしょうか?
仰るように、訓練データに対するlossは正しく減少しているが評価データに対するlossは高いままで推移している(振動すらしている)ことと、accuracyの様子から過学習と言えると思います。
ここで見て頂きたいのが図と、その下のevaluate_generatorによって計算したloss値を見比べて頂きたいです。
openの数値はloss,accuracy共にエポックが15回目の値を取っていると考えられますが、closedの数値はどう見ても表からかけ離れています。
この現状と過学習を切り離して考えていたのですが、それは間違いでしょうか?
Loss のグラフと evaluate_generator() で算出される評価値が異なるというのは質問の旨だとしたら、過学習は関係ないですね。失礼しました。
コードを見ただけだと、ちょっと原因はわからないです。
とりあえずグラフの出力に使っている history.history['val_loss'] の最後の値と model.evaluate_generator(test_generator) で出てくる値を比較してみてはどうでしょうか?
print('loss:',result[0])
print(history.history['val_loss'][-1])
もしこれらの値に違いがあるようであれば、evaluate_generator() が算出した loss と history.history['val_loss'] に格納されてる学習時に記録された loss が同じ方法で計算されたものかを確認する必要があると思います。
あなたの回答
tips
プレビュー


