



入力画像とセグメンテーション結果のファイルをどこかにアップしていただくことはできますか?
変数 seg_map も実態が ndarray ならば、 CSV 形式ではなく、png 形式で保存すれば、画像になるので、teratail の質問欄にアップできると思います。
前提・実現したいこと
前回『セマンティックセグメンテーション Deeplab v3+を用いて画像から人型を認識させたい。』の引き続きになります。
ローカルより人と認識するところへマスクする画像を取得することはできました。
手順
tensorflow/models
このコードを改変したものをanaconda仮想環境上で実行。
python
1import os 2from io import BytesIO 3import tarfile 4import tempfile 5from six.moves import urllib 6 7from matplotlib import gridspec 8from matplotlib import pyplot as plt 9import numpy as np 10from PIL import Image 11 12import tensorflow as tf 13 14import random 15 16class DeepLabModel(object): 17 """Class to load deeplab model and run inference.""" 18 19 INPUT_TENSOR_NAME = 'ImageTensor:0' 20 OUTPUT_TENSOR_NAME = 'SemanticPredictions:0' 21 INPUT_SIZE = 513 22 FROZEN_GRAPH_NAME = 'frozen_inference_graph' 23 24 def __init__(self, tarball_path): 25 """Creates and loads pretrained deeplab model.""" 26 self.graph = tf.Graph() 27 28 graph_def = None 29 # Extract frozen graph from tar archive. 30 tar_file = tarfile.open(tarball_path) 31 for tar_info in tar_file.getmembers(): 32 if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name): 33 file_handle = tar_file.extractfile(tar_info) 34 graph_def = tf.GraphDef.FromString(file_handle.read()) 35 break 36 37 tar_file.close() 38 39 if graph_def is None: 40 raise RuntimeError('Cannot find inference graph in tar archive.') 41 42 with self.graph.as_default(): 43 tf.import_graph_def(graph_def, name='') 44 45 self.sess = tf.Session(graph=self.graph) 46 47 def run(self, image): 48 """Runs inference on a single image. 49 Args: 50 image: A PIL.Image object, raw input image. 51 Returns: 52 resized_image: RGB image resized from original input image. 53 seg_map: Segmentation map of `resized_image`. 54 """ 55 width, height = image.size 56 resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height) 57 target_size = (int(resize_ratio * width), int(resize_ratio * height)) 58 resized_image = image.convert('RGB').resize(target_size, Image.ANTIALIAS) 59 batch_seg_map = self.sess.run( 60 self.OUTPUT_TENSOR_NAME, 61 feed_dict={self.INPUT_TENSOR_NAME: [np.asarray(resized_image)]}) 62 seg_map = batch_seg_map[0] 63 return resized_image, seg_map 64 65 66def create_pascal_label_colormap(): 67 """Creates a label colormap used in PASCAL VOC segmentation benchmark. 68 Returns: 69 A Colormap for visualizing segmentation results. 70 """ 71 colormap = np.zeros((256, 3), dtype=int) 72 ind = np.arange(256, dtype=int) 73 74 for shift in reversed(range(8)): 75 for channel in range(3): 76 colormap[:, channel] |= ((ind >> channel) & 1) << shift 77 ind >>= 3 78 79 return colormap 80 81 82def label_to_color_image(label): 83 """Adds color defined by the dataset colormap to the label. 84 Args: 85 label: A 2D array with integer type, storing the segmentation label. 86 Returns: 87 result: A 2D array with floating type. The element of the array 88 is the color indexed by the corresponding element in the input label 89 to the PASCAL color map. 90 Raises: 91 ValueError: If label is not of rank 2 or its value is larger than color 92 map maximum entry. 93 """ 94 if label.ndim != 2: 95 raise ValueError('Expect 2-D input label') 96 97 colormap = create_pascal_label_colormap() 98 99 if np.max(label) >= len(colormap): 100 raise ValueError('label value too large.') 101 102 return colormap[label] 103 104 105def vis_segmentation(image, seg_map): 106 """Visualizes input image, segmentation map and overlay view.""" 107 plt.figure(figsize=(15, 5)) 108 grid_spec = gridspec.GridSpec(1, 4, width_ratios=[6, 6, 6, 1]) 109 110 plt.subplot(grid_spec[0]) 111 plt.imshow(image) 112 plt.axis('off') 113 plt.title('input image') 114 115 plt.subplot(grid_spec[1]) 116 seg_image = label_to_color_image(seg_map).astype(np.uint8) 117 plt.imshow(seg_image) 118 plt.axis('off') 119 plt.title('segmentation map') 120 121 plt.subplot(grid_spec[2]) 122 plt.imshow(image) 123 plt.imshow(seg_image, alpha=0.7) 124 plt.axis('off') 125 plt.title('segmentation overlay') 126 127 unique_labels = np.unique(seg_map) 128 ax = plt.subplot(grid_spec[3]) 129 plt.imshow( 130 FULL_COLOR_MAP[unique_labels].astype(np.uint8), interpolation='nearest') 131 ax.yaxis.tick_right() 132 plt.yticks(range(len(unique_labels)), LABEL_NAMES[unique_labels]) 133 plt.xticks([], []) 134 ax.tick_params(width=0.0) 135 plt.grid('off') 136 plt.show() 137 138 139LABEL_NAMES = np.asarray([ 140 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 141 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 142 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv' 143]) 144 145FULL_LABEL_MAP = np.arange(len(LABEL_NAMES)).reshape(len(LABEL_NAMES), 1) 146FULL_COLOR_MAP = label_to_color_image(FULL_LABEL_MAP) 147 148#@title Select and download models {display-mode: "form"} 149 150MODEL_NAME = 'mobilenetv2_coco_voctrainaug' # @param ['mobilenetv2_coco_voctrainaug', 'mobilenetv2_coco_voctrainval', 'xception_coco_voctrainaug', 'xception_coco_voctrainval'] 151 152_DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/' 153_MODEL_URLS = { 154 'mobilenetv2_coco_voctrainaug': 155 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz', 156 'mobilenetv2_coco_voctrainval': 157 'deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz', 158 'xception_coco_voctrainaug': 159 'deeplabv3_pascal_train_aug_2018_01_04.tar.gz', 160 'xception_coco_voctrainval': 161 'deeplabv3_pascal_trainval_2018_01_04.tar.gz', 162} 163_TARBALL_NAME = 'deeplab_model.tar.gz' 164 165model_dir = tempfile.mkdtemp() 166tf.gfile.MakeDirs(model_dir) 167 168download_path = os.path.join(model_dir, _TARBALL_NAME) 169print('downloading model, this might take a while...') 170urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + _MODEL_URLS[MODEL_NAME], 171 download_path) 172print('download completed! loading DeepLab model...') 173 174MODEL = DeepLabModel(download_path) 175print('model loaded successfully!') 176 177#@title Run on sample images {display-mode: "form"} 178 179''' 180SAMPLE_IMAGE = 'image1' # @param ['image1', 'image2', 'image3'] 181IMAGE_URL = '' #@param {type:"string"} 182_SAMPLE_URL = ('https://github.com/tensorflow/models/blob/master/research/' 183 'deeplab/g3doc/img/%s.jpg?raw=true') 184''' 185 186 187def run_visualization(url): 188 """Inferences DeepLab model and visualizes result.""" 189 try: 190 # f = urllib.request.urlopen(url) 191 # jpeg_str = f.read() 192 # original_im = Image.open(BytesIO(jpeg_str)) 193 original_im = Image.open(url) 194 except IOError: 195 print('Cannot retrieve image. Please check url: ' + url) 196 return 197 198 print('running deeplab on image %s...' % url) 199 resized_im, seg_map = MODEL.run(original_im) 200 201 vis_segmentation(resized_im, seg_map) 202 import csv 203 f = open('./test_image/seg_map.csv', 'w') 204 writer = csv.writer(f, lineterminator='\n') 205 writer.writerow(seg_map) 206 f.close() 207 208image_path = './test_image/3.jpg' 209run_visualization(image_path)
test_imageフォルダを同階層に準備し目当ての画像(3.jpgなど)置いて実行。
例)(再使用が許可された画像を使用しています。)

↓
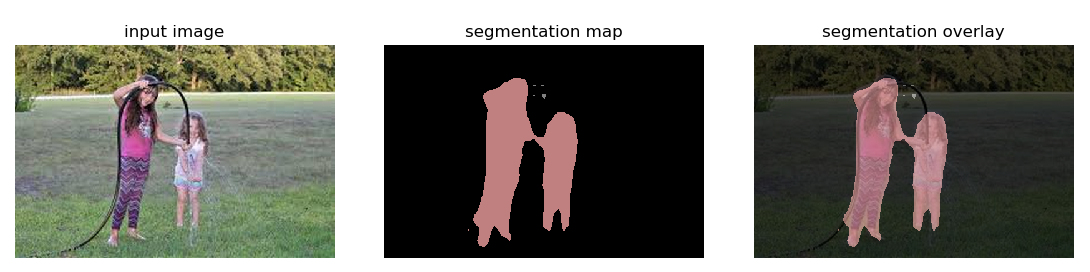
ここから、人物以外を透過処理させたいと考えています。
特にこちらの方がphpで実践していましたが、pythonとしてローカル上で実行させたいと考えています。
もしこれを利用するとなりますと、xamppや他のサーバなどの準備が必要になると考えています。
最終的にはpythonのexeにまとめたいため、phpのexecファイルが絡むと他サーバなどの準備が絡むので不可能と判断しています。そのためpythonとして統一して作りたいと思いました。
私の環境
OS Windows10
GPU RTX2070
GPUのドライバー 26.21.14.4166
python Python 3.7 :: Anaconda, Inc.
CUDA CUDA Toolkit 9.0
cuDNN release 9.0, V9.0.176
tensorflow_gpu v1.13.1
keras 2.3.4
行ったこと
seg_mapの中身を確認しますと、
python
1import csv 2f = open('./test_image/seg_map2.csv', 'w') 3writer = csv.writer(f, lineterminator='\n') 4writer.writerow(seg_map) 5f.close()
seg_map.csv

ここから視認性を高くするために
①\r\nを空白置換
②","を",\r\n"へ置換
置換後seg_map.csv

semantic segmentationはピクセル単位で認識するため、人を15と表示しています。
これは姉妹兄弟?のお姉ちゃんの頭の部分でしょうか。
座標情報から0と表示されているところのみ、以下コードを利用しようと考えています。
OpenCV python 座標情報から画像を切り抜きたい
python
1import cv2 2import numpy as np 3 4# img1: 元の画像, 形状が (Width, Height, 3) の numpy 配列 5# contour: 輪郭の頂点情報, 形状が (NumPoints, 2) の numpy 配列 6 7# マスク画像を作成する。 8# 前景の画素は (255, 255, 255)、背景の画素は (0, 0, 0) 9mask = np.zeros_like(img1) 10cv2.fillConvexPoly(mask, contour, color=(255, 255, 255)) 11 12# 背景画像 13bg_color = (50, 200, 0) 14img2 = np.full_like(img, bg_color) 15 16# np.where() はマスクの値が (255, 255, 255) の要素は前景画像 img1 の値、 17# マスクの値が (0, 0, 0) の要素は背景画像 img2 の値を返す。 18result = np.where(mask==255, img1, img2)
しかし、このcontourを取得する方法が必要でした。
contourは、もともと多角形を記述を行うために
python
1contours = np.array( [ [100,100], [100,230], [230, 250], [150,70] ] )
と座標を並べ行くイメージで、この人物と背景の堺の座標が取得できれば上記codeで可能とは考えているのですが、そもそもこの座標情報から背景を透過させるライブラリなどあるものなのでしょうか。人へのマスキングができているのなら、それ以外を透過させるのはすぐにできると考えていましたが、これはどのような方向性でいったほうがよろしいのでしょうか。知見ある方アドバイス頂けないでしょうか。よろしくお願い致します。
20200705 13:50追記
seg_map.csvと対象画像になります。
結果画像は保存を試したのですがmatplotlibで表示されるのみでした。
python
1fig.figure() 2fig.savefig(image.jpg)
こちらのコードを途中入れたのですが保存ができませんでした。
20200705 14:05 追記
| 追加コマンド | 結果 |
|---|---|
| print(type(seg_map)) | <class 'numpy.ndarray'> |
| print(seg_map.shape, seg_map.dtype) | (341, 513) int64 |
| np.save("seg_map.npy", seg_map) | (GoogleDriveに追加します) |
| cv2.imwrite("seg_map.png", seg_map.astype(np.uint8)) | (GoogleDriveに追加します) |
ありがとうございます。結果などアップします。お待ちください。
Google 共有ドライブへアップしました。結果画像は保存が難しいようです。。
segmap の型はどうなっていますか?
print(type(segmap)) の結果を教えて下さい
その結果が ndarray 配列であれば、
print(segmap.shape, segmap.dtype) の出力結果も記載していただけますか
もし ndarray 配列であれば、
np.save("segmap.npy", segmap) で npy ファイルで保存するか
または
cv2.imwrite("segmap.png", segmap.astype(np.uint8))
で画像として保存できるのではないかと思います。
ありがとうございます。npyで保存もできましたし画像も保存できました。結果を追記しました。
回答1件

あなたの回答
tips
プレビュー


