

- リスト### 前提・実現したいこと
tensorflowで多クラス分類[nagative1],[negative2],[other]のCNNモデルを作成しています。
そこで今まで二値分類で成功していたモデルで再学習してみたところ、accuracyが0.5から一切上がらない状態になりました。
どこを変更したほうがいいのかをご教示ください。
ちなみにデータセットは[negative1]には一人の顔train1800枚,test1000枚
[negative2]には別の一人の顔
[other]には適当な人の顔
が入っています。

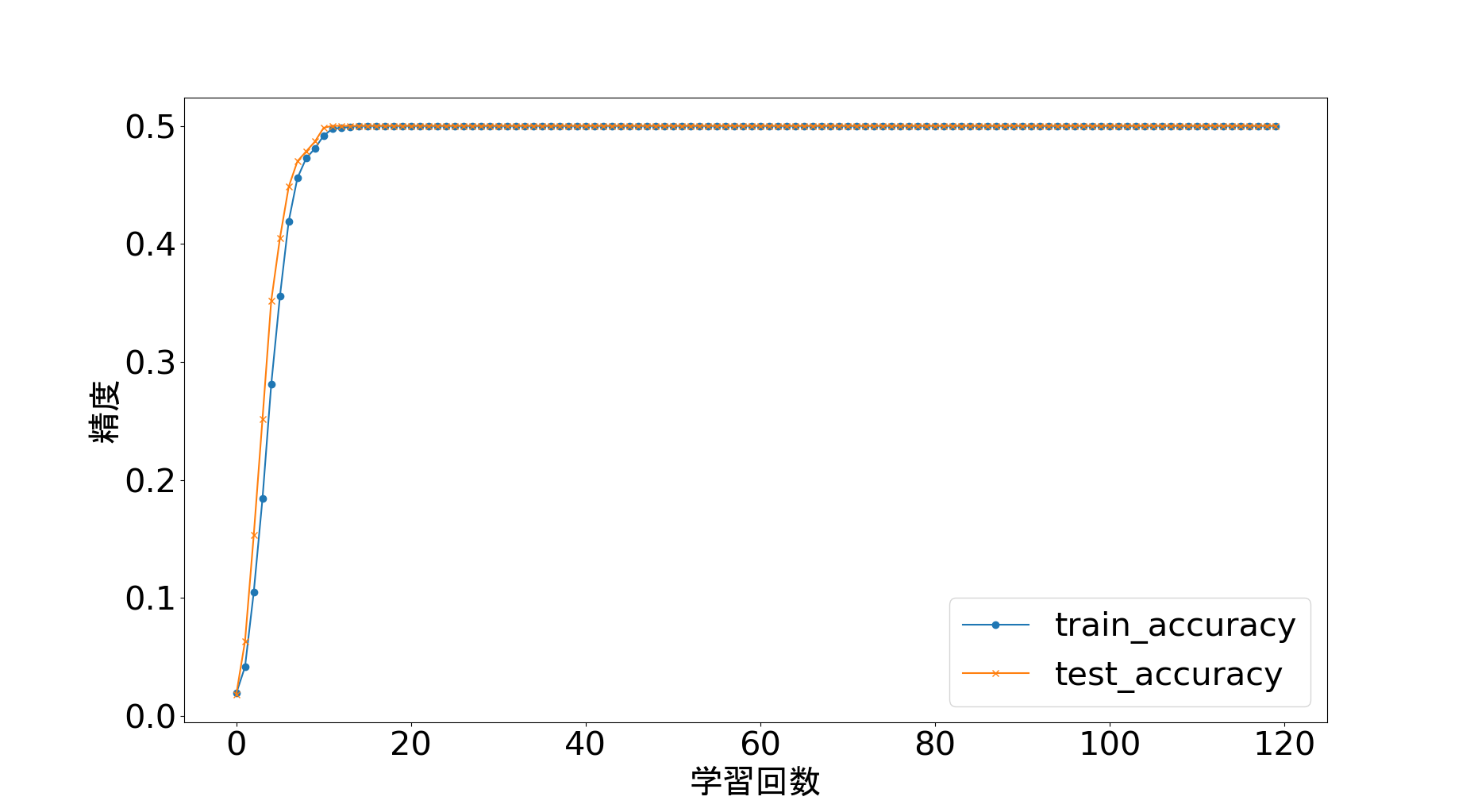
発生している問題・エラーメッセージ
エラーメッセージ
該当のソースコード
python import os import random import cv2 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt #image path path = "./new_face/train" dirs = os.listdir(path) dirs = [f for f in dirs if os.path.isdir(os.path.join(path, f))] label_dict = {} i = 0 for dirname in dirs: label_dict[dirname] = i i += 1 def load_data(data_type): filenames, images, labels = [], [], [] walk = filter(lambda _: not len(_[1]) and data_type in _[0], os.walk('faces')) for root,dirs,files in walk: filenames += ['{}/{}'.format(root, _) for _ in files if not _.startswith('.')] # シャッフル random.shuffle(filenames) # 読み込み, リサイズとリシェープ images = [] for file in filenames: img = cv2.imread(file) img = cv2.resize(img, (32,32)) images.append(img.flatten().astype(np.float32) / 255.0) images = np.asarray(images) for filename in filenames: label = np.zeros(len(label_dict)) for k, v in label_dict.items(): if k in filename: label[v] = 1. labels.append(label) return images, labels def get_batch_list(l, batch_size): # [1, 2, 3, 4, 5,...] -> [[1, 2, 3], [4, 5,..]] return [np.asarray(l[_:_+batch_size]) for _ in range(0, len(l), batch_size)] def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') def inference(images_placeholder, keep_prob): x_image = tf.reshape(images_placeholder, [-1, 32, 32, 3]) # 畳み込み層 W_conv1 = weight_variable([5, 5, 3, 32]) b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # プーリング層 h_pool1 = max_pool_2x2(h_conv1) # 畳み込み層 W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # プーリング層 h_pool2 = max_pool_2x2(h_conv2) # 全結合層 W_fc1 = weight_variable([8 * 8 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 8 * 8 * 64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # ドロップアウト層 h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 全結合層 W_fc2 = weight_variable([1024, len(label_dict)]) b_fc2 = bias_variable([len(label_dict)]) return tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # データ読み込み train_images, train_labels = load_data('train') test_images, test_labels = load_data('test') print("train_images", len(train_images)) print("test_images", len(test_images)) x = tf.placeholder('float', shape=[None, 32 * 32 * 3]) # 32 * 32, 3 channels y_ = tf.placeholder('float', shape=[None, len(label_dict)]) # label_dict size keep_prob = tf.placeholder('float') y_conv = inference(x, keep_prob) # 損失関数 cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv)) tf.summary.scalar('cross_entropy', cross_entropy) # Minimize cross entropy by using SGD train_number = input("Please Input Train Rate : ") train_step = tf.train.AdamOptimizer(float(train_number)).minimize(cross_entropy) #train_step = tf.train.AdadeltaOptimizer(float(train_number)).minimize(cross_entropy) # Accuracy correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float')) saver = tf.train.Saver() sess = tf.InteractiveSession() sess.run(tf.global_variables_initializer()) # バッチ batch = input("Please Input Batch Size : ") batch_size = int(batch) batched_train_images = get_batch_list(train_images, batch_size) batched_train_labels = get_batch_list(train_labels, batch_size) print(len(batched_train_labels)) train_labels, test_labels = np.asarray(train_labels), np.asarray(test_labels) cnt = 0 loss_list = [] accuracys = [] test_accuracys=[] train_loss_list = [] test_loss_list = [] # 学習 steps = input("Please Input Steps Number : ") for i in range(int(steps)): #1 => 20 , 2 => 40 ... for step, (images, labels) in enumerate(zip(batched_train_images, batched_train_labels)): sess.run(train_step, feed_dict={ x: images, y_: labels, keep_prob: 0.5 }) train_accuracy = accuracy.eval(feed_dict = { x: train_images, y_: train_labels, keep_prob: 1.0 }) accuracys.append(train_accuracy) train_loss = cross_entropy.eval(feed_dict = { x: train_images, y_: train_labels, keep_prob: 1.0 }) train_loss_list.append(train_loss) #cnt += 1 print('step {}, training accuracy {}'.format(cnt, train_accuracy)) # 学習されたモデルをテスト test_accuracy = accuracy.eval(feed_dict = { x: test_images, y_: test_labels, keep_prob: 1.0 }) test_accuracys.append(test_accuracy) print('test accuracy {}'.format(test_accuracy)+"\n") test_loss = cross_entropy.eval(feed_dict = { x: test_images, y_: test_labels, keep_prob: 1.0 }) test_loss_list.append(test_loss) cnt += 1 # モデルのセーブ save_path = saver.save(sess, "model_face2/model2.ckpt") sess.close() plt.xlabel("学習回数" , fontname = "MS Gothic",fontsize=30) plt.ylabel("コスト" , fontname = "MS Gothic",fontsize=30) plt.plot(train_loss_list,marker="o",label="train_loss") plt.plot(test_loss_list,marker="x",label="test_loss") plt.legend(fontsize=30) plt.tick_params(labelsize=30) plt.show() plt.xlabel("学習回数", fontname = "MS Gothic",fontsize=30) plt.ylabel("精度", fontname = "MS Gothic",fontsize=30) plt.plot(accuracys,marker="o",label="train_accuracy") plt.plot(test_accuracys,marker="x",label="test_accuracy") plt.legend(fontsize=30) plt.tick_params(labelsize=30) plt.show() #Result indicate import tkinter root = tkinter.Tk() root.geometry("400x300") label1 = tkinter.Label(root,text="学習率 : "+train_number).pack() label2 = tkinter.Label(root,text="バッチ数 : "+batch).pack() label3 = tkinter.Label(root,text="学習回数 : "+str(cnt)).pack() label4 = tkinter.Label(root,text="train_accuracy : "+str(train_accuracy)).pack() label5 = tkinter.Label(root,text="test_accuracy : "+str(test_accuracy)).pack() root.mainloop()
試したこと
何通りかのパラメータで学習させた。
オプティマイザーをいくつか試してみた。
補足情報(FW/ツールのバージョンなど)
ここにより詳細な情報を記載してください。
あなたの回答
tips
プレビュー


