
前提
python3で、PDFデータを読み込むコードを書いています。
tabula.read_pdfという関数を使用して、以下のようにPDFファイルを読み込もうとしたところ、
以下の通り読み込めませんでした。
#プログラムの中身 filename_m= "test.pdf" tp_m = tabula.read_pdf(filename_m, stream=True, pages = 'all', encoding='shift-jis', silent=True) print("tp_m=") print(tp_m) #出力 tp_m= []
ここでtest.pdfの中身は以下の通りです。
次に、データの行数を2行にした"test2.pdf", 3行の"test3.pdf", 4行の"test4.pdf"を用意しました。

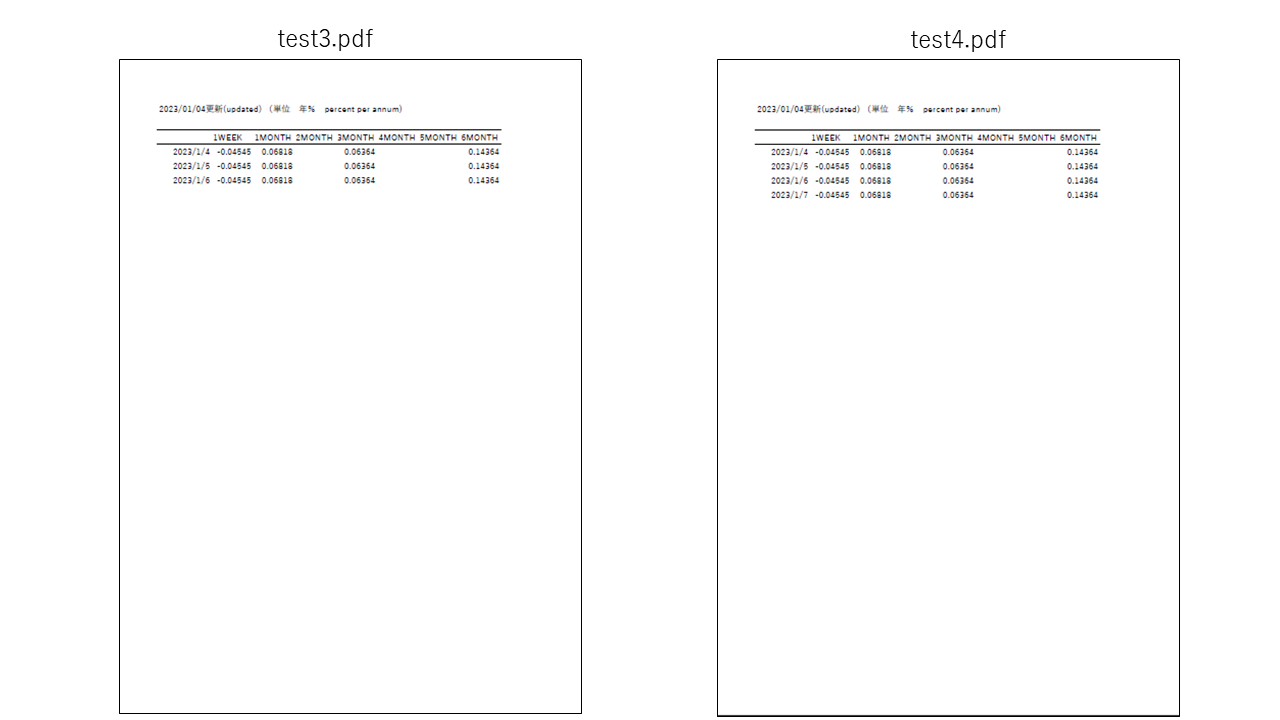
上記のプログラムを実行したところ、
"test2.pdf"と"test3.pdf"については同様に読み込めませんでした。
一方で、"test4.pdf" については以下の通り読み込めました。
filename_m= "test4.pdf" tp_m = tabula.read_pdf(filename_m, stream=True, pages = 'all', encoding='shift-jis', silent=True) print("tp_m=") print(tp_m) #出力 tp_m = [ Unnamed: 0 1WEEK 1MONTH 2MONTH 3MONTH 4MONTH 5MONTH 6MONTH 0 2023/1/4 -0.04545 0.06818 NaN 0.06364 NaN NaN 0.14364 1 2023/1/5 -0.04545 0.06818 NaN 0.06364 NaN NaN 0.14364 2 2023/1/6 -0.04545 0.06818 NaN 0.06364 NaN NaN 0.14364 3 2023/1/7 -0.04545 0.06818 NaN 0.06364 NaN NaN 0.14364]
同様に、5行以上の入力データを作成して試したところ、読み込まれました。
質問
ⅰ) tabula.read_pdfは、入力データが4行以上の場合のみ読み込めるのでしょうか。
ⅱ) もしそうであるなら、改善策はありますか?
入力用のPDFファイルに記述されているデータの行数が1~3行の場合に、それを読み込める関数などがあれば、ご教示いただきたいです。もしくは、現状のプログラムを修正して改善できるのでしょうか
以上、よろしくお願いいたします。
回答1件
あなたの回答
tips
プレビュー



2023/01/16 04:56