
やりたいこととしては、`model.fit()`のバッチ処理ごとに、どのデータがサンプリングされて、分類確率はどうなっているかを知ることです。
Keras(バックエンドはTensorFlow)を利用して、各バッチ処理毎に入力データと予測結果を取得したいです。
ドキュメントを読んだところ、精度等はコールバック関数を利用して取得できるのですが、入力データと予測結果の取得方法がわかりません。
何卒ご教示のほどお願い申し上げます。
気になる質問をクリップする
クリップした質問は、後からいつでもMYページで確認できます。
またクリップした質問に回答があった際、通知やメールを受け取ることができます。
回答2件
0
以下の種類のコールバック関数があるので、各バッチ処理毎にログをファイルに保存したい等あれば、そこで行うとよいでしょう。
- 各反復開始時に呼ばれるコールバック関数
- 各反復終了時に呼ばれるコールバック関数
- 各エポック開始時に呼ばれるコールバック関数
- 各エポック終了時に呼ばれるコールバック関数
- 学習開始時に呼ばれるコールバック関数
- 学習終了時に呼ばれるコールバック関数
コールバック関数 を参考にしてください。
各反復終了時に学習誤差、学習精度を print する例
python
1from keras import backend as K 2from keras.callbacks import Callback 3from keras.datasets import mnist 4from keras.layers import Activation, BatchNormalization, Dense, Dropout 5from keras.models import Sequential 6from keras.utils.np_utils import to_categorical 7import numpy as np 8 9# MNIST データを取得する。 10(x_train, y_train), (x_test, y_test) = mnist.load_data() 11print('x_train.shape', x_train.shape) # x_train.shape (60000, 28, 28) 12print('y_train.shape', y_train.shape) # y_train.shape (60000,) 13print('x_test.shape', x_test.shape) # x_test.shape (10000, 28, 28) 14print('y_test.shape', y_test.shape) # y_test.shape (10000,) 15 16# 1次元配列にする。 (28, 28) -> (784,) にする 17x_train = x_train.reshape(len(x_train), -1) 18x_test = x_test.reshape(len(x_test), -1) 19 20# one-hot 表現に変換する。 21y_train = to_categorical(y_train) 22y_test = to_categorical(y_test) 23 24# モデルを作成する。 25model = Sequential() 26model.add(Dense(10, input_dim=784)) 27model.add(BatchNormalization()) 28model.add(Activation('relu')) 29model.add(Dense(10)) 30model.add(BatchNormalization()) 31model.add(Activation('relu')) 32model.add(Dense(10)) 33model.add(BatchNormalization()) 34model.add(Activation('softmax')) 35model.compile(optimizer='adam', 36 loss='categorical_crossentropy', 37 metrics=['accuracy']) 38 39# 各イテレーション開始時に呼ばれるコードバック関数 40class MyCallback(Callback): 41 def on_batch_end(self, batch, logs={}): 42 '''1反復分終了した際に呼ばれる関数 43 ''' 44 print('iteration: {}, train loss: {:.2f}, train accuracy: {:.2f}'.format( 45 logs['batch'], logs['loss'], logs['acc'])) 46 47# 学習する。 48history = model.fit(x_train, y_train, epochs=10, batch_size=128, 49 validation_data=(x_test, y_test), 50 callbacks=[MyCallback()]) 51
質問の内容について
予測結果は、分類するクラスに対するそれぞれの確率のことを意図していました。 また、バッチ処理でランダムにサンプリングされた入力も取得したいです。
上記のコールバック関数の引数で対応できないことなので、自分でミニバッチを作成し、 train_on_batch() で1バッチ分学習したあと、バッチごとに行いたい処理を書きます。
以下は次の処理を行うサンプルコードになります。
- 1イテレーションごとのみにバッチの入力を取得する。
- 1エポックごとにテストデータによる各クラスの分類精度と混合行列を表示する。
python
1import numpy as np 2import seaborn as sn 3from keras.datasets import mnist 4from keras.layers import Activation, BatchNormalization, Dense, Dropout 5from keras.models import Sequential 6from keras.utils.np_utils import to_categorical 7from sklearn import metrics 8 9# MNIST データを取得する。 10(x_train, y_train), (x_test, y_test) = mnist.load_data() 11print('x_train.shape', x_train.shape) # x_train.shape (60000, 28, 28) 12print('y_train.shape', y_train.shape) # y_train.shape (60000,) 13print('x_test.shape', x_test.shape) # x_test.shape (10000, 28, 28) 14print('y_test.shape', y_test.shape) # y_test.shape (10000,) 15 16# モデルを作成する。 17model = Sequential() 18model.add(Dense(10, input_dim=784)) 19model.add(BatchNormalization()) 20model.add(Activation('relu')) 21model.add(Dense(10)) 22model.add(BatchNormalization()) 23model.add(Activation('relu')) 24model.add(Dense(10)) 25model.add(BatchNormalization()) 26model.add(Activation('softmax')) 27model.compile(optimizer='adam', 28 loss='categorical_crossentropy', 29 metrics=['accuracy']) 30 31def get_batch(x, y, batch_size, shuffle=False): 32 '''ミニバッチを生成するジェネレーター関数 33 ''' 34 num_samples = len(x) 35 if shuffle: 36 indices = np.random.permutation(num_samples) 37 else: 38 indices = np.random.arange(num_samples) 39 num_iterations = np.ceil(num_samples / batch_size).astype(int) 40 for itr in range(num_iterations): 41 start = batch_size * itr 42 excerpt = indices[start:start + batch_size] 43 yield x[excerpt], y[excerpt] 44 45# モデルの入力に合わせて1次元配列にする。 (28, 28) -> (784,) にする 46x_train = x_train.reshape(len(x_train), -1) 47x_test = x_test.reshape(len(x_test), -1) 48 49# one-hot 表現に変換する。 50y_train_onehot = to_categorical(y_train) 51 52# 学習する。 53epochs = 10 54for i in range(epochs): 55 for x_batch, y_batch in get_batch(x_train, y_train_onehot, batch_size=128, shuffle=True): 56 # x_batch, y_batch が生成されたミニバッチ 57 58 # 1バッチ分学習する 59 model.train_on_batch(x_batch, y_batch) 60 61 # エポックごとにテストデータで推論する。 62 indices = np.random.randint(0, len(x_test), 100) 63 y_pred = model.predict_classes(x_test[indices]) 64 65 # 混合行列を表示する。 66 cmx = metrics.confusion_matrix(y_test[indices], y_pred) 67 accuracies = (cmx.astype(np.float) / cmx.sum(axis=1)).diagonal() 68 for label, accuracy in enumerate(accuracies): 69 print('class: {}: {:.2%}'.format(label, accuracy)) 70 71 plt.figure(figsize=(6, 6)) 72 sn.heatmap(cmx) 73 plt.show()
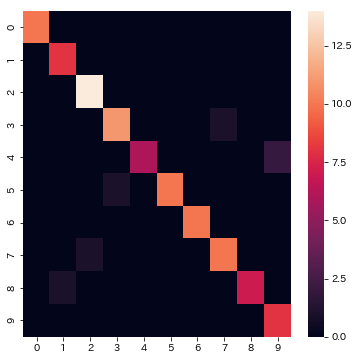
class: 0: 100.00% class: 1: 100.00% class: 2: 100.00% class: 3: 91.67% class: 4: 75.00% class: 5: 90.91% class: 6: 100.00% class: 7: 90.91% class: 8: 87.50% class: 9: 100.00%
投稿2018/09/24 11:39
編集2018/09/27 05:17総合スコア21962
0
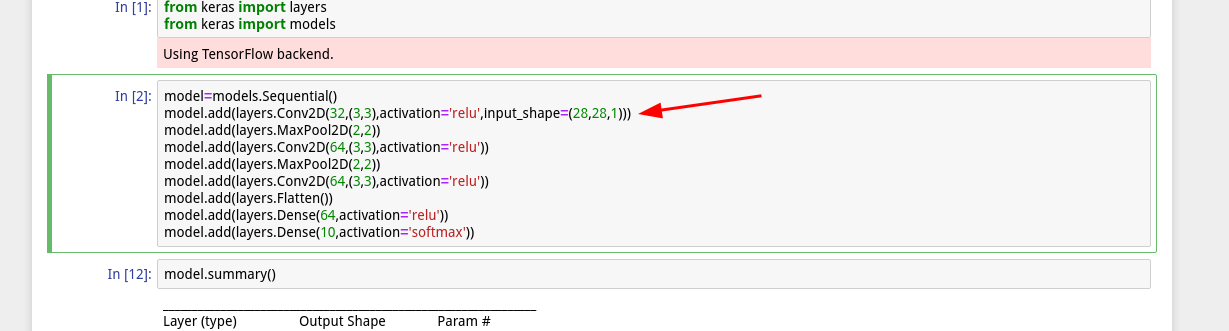
1,ネットワークを作る
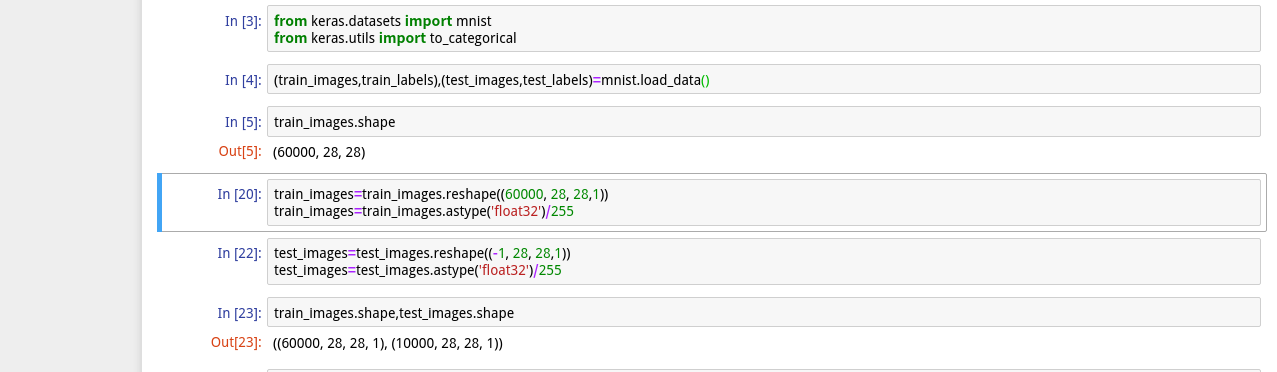
2,データをロードする
3,train
model.fit()

4,テストデータをテストする
model.evaluate()

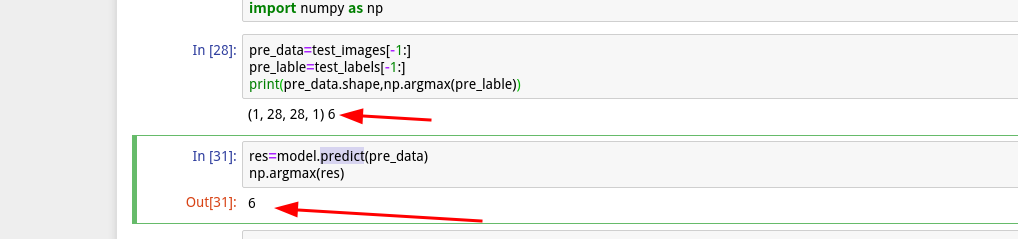
5 予測する
model.predict()
私は馬鹿です、よろしく.
投稿2018/09/24 10:23
総合スコア134
![]()
あなたの回答
tips
太字
斜体
打ち消し線
見出し
引用テキストの挿入
コードの挿入
リンクの挿入
リストの挿入
番号リストの挿入
表の挿入
水平線の挿入
プレビュー
質問の解決につながる回答をしましょう。 サンプルコードなど、より具体的な説明があると質問者の理解の助けになります。 また、読む側のことを考えた、分かりやすい文章を心がけましょう。



2018/09/27 03:01
2018/09/27 05:18