
コサイン類似度そのものについては理解していますか?
前提・実現したいこと
Word2Vecにおける類似度測定関数について、
コサイン類似度で測定しているとあるのですが、
①
コサイン類似度の式に当てはめたときに、
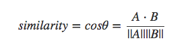
このコードでは一体分母と分子が何にあたるのかよくわかりません。
コード参照元
Python
1import gensim 2word2vec_model = gensim.models.KeyedVectors.load_word2vec_format('model/model_neologd.vec', binary=False) 3import pprint 4pprint.pprint(word2vec_model.similarity('国王', '王妃'))
②
また、word2vecでベクトルから単語を出力するコードにおいて、
どのような原理で類似単語が出力され、コサイン類似度による類似度測定はどのように関わっているのかわからず、困っています。
コード参照元2
python
1sentences = gensim.models.word2vec.Text8Corpus(filename) 2model = Word2Vec(sentences, size=100, window=5, min_count=5, workers=4) 3vector = model.wv["明智"] 4word = model.most_similar( [ vector ], [], 5)
### 試したこと
どちらの問題も
gensimにおけるsimilarity関数の説明を読みましたが、
よくわかりませんでした。
①
n_similarity(ws1, ws2) Compute cosine similarity between two sets of words. Parameters: ws1 (list of str) – Sequence of words. ws2 (list of str) – Sequence of words. Returns: Similarities between ws1 and ws2. Return type: numpy.ndarray
②
most_similar(**kwargs) Find the top-N most similar entities. Possibly have positive and negative list of entities in **kwargs.
他、参考資料
補足情報(FW/ツールのバージョンなど)
python3.6
ご質問いただきましてありがとうございます。強調フィルタリングにおけるコサイン類似度は、cos(a,b) = a・b / (|a| ・ |b|) = 両方アクセスしたユーザ数 / 商品a, bそれぞれにアクセスしたユーザ数で求められているという理解です。コサイン類似度自体は、コサイン値を求めており2点のベクトルのなす角度によって類似度を測定しているという理解です。
回答2件
あなたの回答
tips
プレビュー


