
スクリーンショット中にも、私が実際にアクセスしてみても、columnTitle というIDを持った要素は見当たらないので、これがどこから来たのか不思議です。
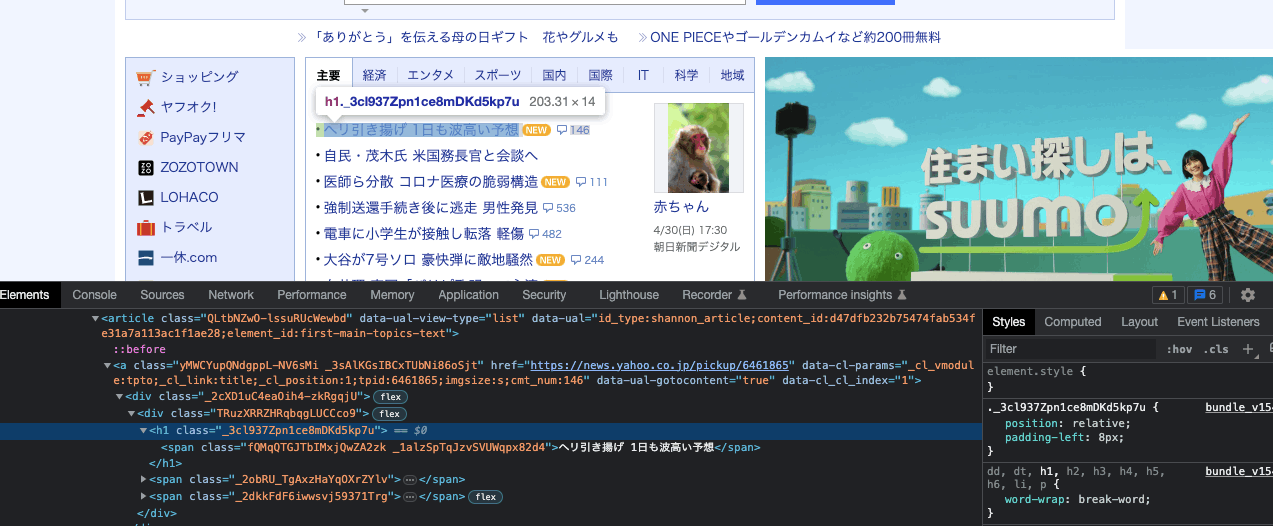
とりあえず、2枚めのスクリーンショットの吹き出しにあるように h1._3cl937Zpn1ce8mDKd5kp7u を試してみてはどうでしょうか。
実現したいこと
yahooニュースの以下の箇所のテキストをCSSセレクタを用いて取得したい

前提
SeleniumでYahoo.co.jpにアクセスしてスクレイピングを行っています。その際、「実現したいこと」に添付されている箇所のテキスト情報を出力するコードを書きたいです。
ここでは「ヘリ引き揚げ 1日も波高い予想」というタイトル名を取得したいです。
発生している問題・エラーメッセージ
NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"#columnTitle h3 *"} (Session info: headless chrome=112.0.5615.137)
該当のソースコード
Python
1from selenium.webdriver.common.by import By 2options = webdriver.ChromeOptions() 3options.add_argument('--headless')#ブラウザ立ち上げずにやる 4#2 シークレットモード 5options.add_argument('--incognito') 6 7#3 User-Agentの設定 8options.add_argument('--user-agent = Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36') 9 10time.sleep(5) 11#STEP1: driverを作成する 12driver = webdriver.Chrome(executable_path = 'img/chromedriver', 13 options = options) 14driver.implicitly_wait(10) 15 16 17#STEP2: driver.get()でサイトにアクセスする 18driver.get('https://news.yahoo.co.jp/') 19 20time.sleep(5) 21#h2の中にあるhtmlソース&テキスト部分を取得 22e = driver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *') 23print(sentence.get_attribute("innerHTML")) 24 25 26driver.quit()
試したこと
全てBy.CSS_SELECTORをBy.CLASS_NAMEのバージョンでもやってます
・e = driver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *')
print(sentence.get_attribute("innerHTML"))
の箇所を
e = driver.find_element(By.CLASS_NAME, '_2j0udhv5jERZtYzddeDwcv')
print(e)
print(e.text)
に変更
→同じエラー
・options.add_argument('--enable-javascript')をした後に、実行→同じエラー
・上のスクショ画像にあるh1._3cl937Zpn1ce8mDKd5kp7uのようなclassと記載されている要素は全てdriver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *')の「#columnTitle h3 *」部分に挿入して実行→どれも同じエラーでした。
・一方、
e = driver.find_element(By.CSS_SELECTOR, 'h2') print(e.text)
をすると、
トピックス
が帰ってくる。
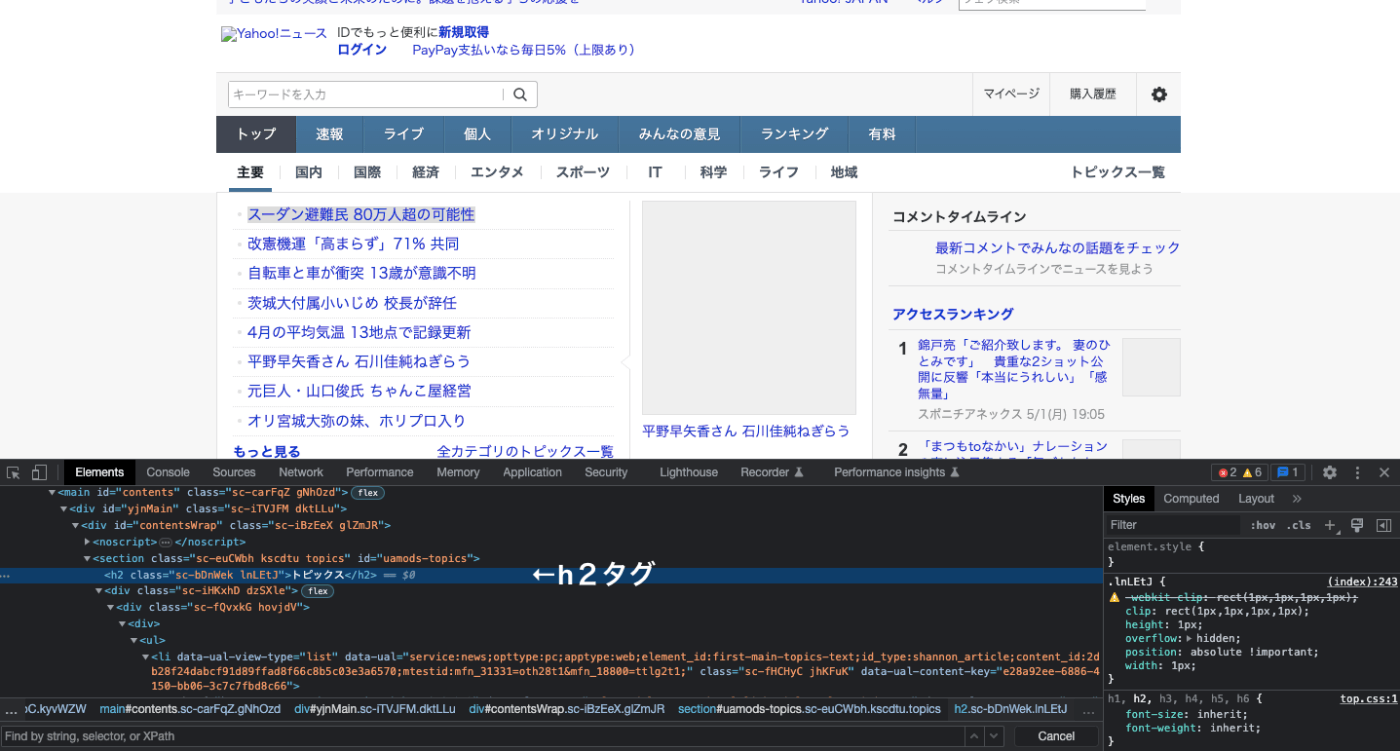
そのため、このCSSセレクタの記述法は間違っていないことがわかる。ということは、CSSセレクタで指定する場所が間違っていると思うのですが、いろんな箇所を指定してみましたがエラーが起きてしまいます。どうすれば良いのでしょうか?
・以下の回答をいただき、
スクリーンショットを見ると https://news.yahoo.co.jp/ ではなくて https://yahoo.co.jp/ の様です。そうでしたら、
e = driver.find_element(By.CSS_SELECTOR, 'div[aria-label="主要 ニュース"] * h1')
となるのではないかと思います。(10:00 時点では「首相 7日からの韓国訪問を表明」が取得されます)
個人的に
e = driver.find_element(By.CSS_SELECTOR, 'div[aria-label="主要 ニュース"] * h1')
の書き方を調べてみましたが、よくわかりませんでした。これはyahoo newsの検索欄で「主要 ニュース」と検索するという意味ですか?また、なぜ https://news.yahoo.co.jp/ ではなく https://yahoo.co.jp/であると、書き方が変わるのかも教えていただけると非常に嬉しいです。
一応、ソースコードの
e = driver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *')
部分を
e = driver.find_element(By.CSS_SELECTOR, 'div[aria-label="主要 ニュース"] * h1')
に書き直して実行してみましたが、同じエラーが出てしまいます。
・print(driver.page_source)を
e = driver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *')
の前にかき、
以下画像の赤線箇所をe = driver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *')の「#columnTitle h3 *」部分に挿入して実行してみましたが全て同じエラーでした。
<span class="sc-WZYut jLeSfx"><span type="NEW" aria-label="NEW" class="sc-eirqVv XiyIJ" role="img"></span></span></a></li><li data-ual-view-type="list" data-ual="service:news;opttype:pc;apptype:web;element_id:first-main-topics-text;id_type:shannon_article;content_id:a1f7fb0d5e83c1833d8c4cc37ba925639899ff54;mtestid:mfn_31331=oth28t1&mfn_18800=ttlg1tc;" class="sc-fHCHyC jhKFuK" data-ual-content-key="8ef6f43a-8dbe-4c89-9bfb-2b1b98049ee4"><a href="https://news.yahoo.co.jp/pickup/6462083" data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:2;" data-ual-gotocontent="true" class="sc-dtLLSn dpehyt" data-cl_cl_index="36">

補足情報(FW/ツールのバージョンなど)
Pythonのバージョン:3.10.9
使用PC:Intel MacBook
バージョン:macOS Monterey Version 12.4
実装環境:Jupyter Lab
Chromeのバージョン:112.0.5615.137
ChromeDriverのバージョン:112.0.5615.49
selenium 4.9.0
*seleniumのバージョンを3系に変更してfind_element_by_idのような記述する方法でやるという方法もあると思います。しかし以前そうしたことで、Chrome driverに関するエラーが頻発したため、この方法ではやりたくないのが正直なところです。
解決しました
本来はa.sc-dtLLSn.dpehytのところを、「class= 〜」の「〜」部分をコピーしていたため、ずっと指定している要素がみつからないという状態に陥っていました!

スクリーンショットを見ると https://news.yahoo.co.jp/ ではなくて https://yahoo.co.jp/ の様です。そうでしたら、
e = driver.find_element(By.CSS_SELECTOR, 'div[aria-label="主要 ニュース"] * h1')
となるのではないかと思います。(10:00 時点では「首相 7日からの韓国訪問を表明」が取得されます)
画像は見にくいので、プログラムとエラーメッセージしか見てませんが、
22行目の e = driver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *') の直前に、
print(driver.page_source) を入れて、その時点でのHTMLを見ましょう。
そこに無いので、no such element となっているわけですが、
HTMLをよく見れば、なぜ無いのにあると思ったのかがわかるのではないかと思います。
int32_tさんご回答ありがとうございます。おっしゃる通り、h1._3cl937Zpn1ce8mDKd5kp7uのようなclassと記載されている要素は全てdriver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *')の「#columnTitle h3 *」部分に挿入しましたが、どれも同じエラーでした。
melianさんご回答ありがとうございます。個人的に
e = driver.find_element(By.CSS_SELECTOR, 'div[aria-label="主要 ニュース"] * h1')
の書き方を調べてみましたが、よくわかりませんでした。これはyahoo newsの検索欄で「主要 ニュース」と検索するという意味ですか?また、なぜ https://news.yahoo.co.jp/ ではなく https://yahoo.co.jp/であると、書き方が変わるのかも教えていただけると非常に嬉しいです。
一応、ソースコードの
e = driver.find_element(By.CSS_SELECTOR, '#columnTitle h3 *')
部分を
e = driver.find_element(By.CSS_SELECTOR, 'div[aria-label="主要 ニュース"] * h1')
に書き直して実行してみましたが、同じエラーが出てしまいます。
'div[aria-label="主要 ニュース"] h1' の意味は、aria-label 属性の値が "主要 ニュース" になっている div 要素内にある h1 要素、という意味です。また、https://yahoo.co.jp/ と https://news.yahoo.co.jp/ とでは中身(HTML コンテンツ)が違います。( https://yahoo.co.jp/ の場合は JavaScript コードですが)
こちらの環境は、Python 3.11.2, Ubuntu Linux 23.04, Chrome 112.0.5615.165, ChromeDriver 112.0.5615.28, selenium 4.9.0 です。8:48 時点で以下を実行すると "憲法改正「賛成」が61% 読売" になります。
driver.get('https://yahoo.co.jp/')
title = driver.find_element(By.CSS_SELECTOR, 'div[aria-label="主要 ニュース"] h1')
print(title.text)
https://news.yahoo.co.jp/ ではなくて https://yahoo.co.jp/ にしたところしっかりと「憲法改正「賛成」が61% 読売」が返ってきました!!心が折れかけていたので、本当に助かりました!ありがとうございます!
https://yahoo.co.jp/ のページのスクレイピングをしたいにもかかわらず、https://yahoo.co.jp/ じゃなくて https://news.yahoo.co.jp/ と書いていて、しかもそれに長時間気づかなかったというオチだったのでしょうか???
そういうことです!
回答1件
あなたの回答
tips
プレビュー


