


回答ありがとうございます。valuesの要素を取り出せば良かったのですね。また、グラフの範囲についてもアドバイスありがとうございます。
実現したいこと
いつも大変お世話になっております。
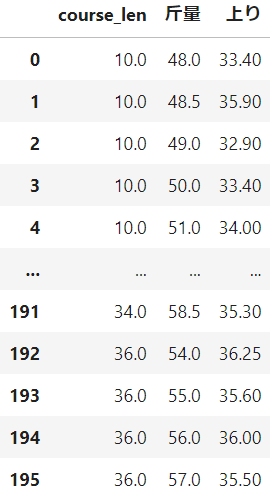
下図のデータフレームの斤量と上りの散布図をcourse_lenごとにプロットしたいと考えています。1つの散布図に全てをプロットするのではなく、course_lenの数の分だけ表示させたいです。
発生している問題・エラーメッセージ
下のコードのようにplt.subplotで散布図をcourse_lenの分、用意することはできましたが、全てのデータが全ての散布図に入ってしまいます(コード下の画像参照)。
values = list(df['course_len'].unique()) fig = plt.figure(figsize=(10,20)) for i in range(len(values)): plt.subplot(len(values), 1, i+1) plt.title('course_len ' + str(values[i])) for value in values: x = df[df['course_len'] == value]['斤量'] y = df[df['course_len'] == value]['上り'] plt.scatter(df[df['course_len'] == value]['斤量'], df[df['course_len'] == value]['上り'])
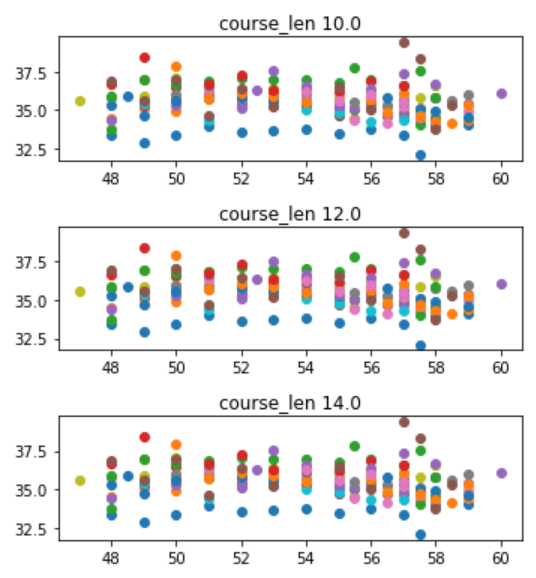
これをcourse_lenごとに散布したいと考えています。ご教示のほどよろしくお願いいたします。
回答2件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2022/07/16 02:40