
文字化けの状況から、UTF-8 エンコーディングの文字列を Shift-JIS(CP932) モードのターミナルで表示している様に見えます。ターミナル上で chcp を実行して現在のコードページを確認してみてください。
実現したいこと
C言語で将棋のゲームを作成しています。以下のコードをvisualstudiocodeからgccにより、
コンパイルして実行しています。以下がソースコードです。ソースファイルはutf-8で、
開かれています。コンパイルから実行しても、表示が文字化けしてしまいます。
表示は画像に記載しています。解決方法があれば、お聞きしてもよろしいですか。
shougi_shisaku.c
#include <stdio.h> #include <string.h> #include <stdlib.h> #include <time.h> // #include <iostream> // #include "shougi_shisaku.h" extern void explode(const char*, char*, int); // 項目を取り出す person data[81]; // 駒のデータの読み込み person dataretu[81]; // 駒のデータのコピー先 char kuuhaku[] = " "; char tate_str[] = "一二三四五六七八九"; int tate_mae, yoko_mae, tate_ato, yoko_ato; void banmen_hyouji() { int readtate, readyoko, coma_cnt = 0; char sub_str[4]; printf("将棋盤\n"); printf("|9 |8 |7 |6 |5 |4 |3 |2 |1 \n"); printf("--------------------------------------------------------------------------------------------\n"); for (readtate = 1; readtate < 10; readtate++) { for (readyoko = 9; readyoko > 0; readyoko--) { if (dataretu[coma_cnt].tate == readtate && dataretu[coma_cnt].yoko == readyoko && dataretu[coma_cnt].koma[0] != '\0') { // 駒の情報がある時 printf("|%s ", &dataretu[coma_cnt].koma[0]); coma_cnt++; } else { // 駒の情報がない時 printf("|%s ", kuuhaku); coma_cnt++; } if (readyoko == 1) { // 縦の駒番号を表示する。 // strから部分文字列を切り出す strncpy(sub_str, tate_str + (readtate - 1) * 2, 2); sub_str[3] = '\0'; // 切り出した部分の終端文字を追加 printf("|%s ", sub_str); } } printf("\n"); printf("--------------------------------------------------------------------------------------------\n"); } } void taikyoku_kaisi() { int koma_data; char koma_str[10] = {}; printf("***先手の番です***\n"); printf("***どの地点を動かしますか***\n"); scanf("%d%d", &tate_mae,&yoko_mae); printf("***どこにを動かしますか***\n"); scanf("%d%d", &tate_ato, &yoko_ato); for (koma_data = 0; koma_data < 81; koma_data++){ if (dataretu[koma_data].tate == tate_mae && dataretu[koma_data].yoko == yoko_mae){ memcpy((void *)koma_str, &dataretu[koma_data].koma[0], 4); memset((void *)dataretu[koma_data].koma, '\0', 10); } } for (koma_data = 0; koma_data < 81; koma_data++){ if (dataretu[koma_data].tate == tate_ato && dataretu[koma_data].yoko == yoko_ato){ memcpy((void*)dataretu[koma_data].koma, (const void*)koma_str, 10); } } } int main() { FILE* fp; char buf[512], * cp; int tatehoukou; printf("\n***将棋ゲーム***\n"); fopen_s(&fp,"shougi_banmen.csv", "r"); // 将棋のファイルを開く if (fp == NULL) goto END; // ファイルを開けない tatehoukou = 0; memset(&data[0], '\0', sizeof(data)); // データの全文字をNULLに while (1) { cp = fgets(buf, 256, fp); // 1レコードを読む if (cp == NULL) break; // EOF explode(",", buf, tatehoukou); // csvデータを1行ずつ、項目を取り出す tatehoukou = tatehoukou + 1; if (tatehoukou == 9) break; } fclose(fp); // 将棋のファイルを閉じる // memcpyを使ったコピー memcpy(&dataretu, &data, sizeof(person)*81); banmen_hyouji(); taikyoku_kaisi(); banmen_hyouji(); END:; }
explode.c
#include <stdio.h> // #include <iostream> // #include "shougi_shisaku.h" void explode(const char*, char*, int); // 項目を取り出す extern person data[81]; // 駒のデータの読み込み int koma_cnt = 0; void explode( /*----------------------------------*/ /* CSVデータから項目を取り出す */ /*----------------------------------*/ const char* kugiri, // 区切り文字 char* buf, // CSVの1レコード int tatehoukou) { char* cp0, * cp; int yokohoukou = 0, len; cp0 = buf; // CSVデータの先頭アドレス for (yokohoukou = 0; yokohoukou < 9; yokohoukou++) { if (*cp0 == 0x22) cp0++; // 最初の"(0x22)を除く cp = strstr(cp0, kugiri); // 区切り文字を検索 if (cp == NULL) break; // 区切り文字なし len = cp - cp0; // 項目の文字数 if (*(cp - 1) == 0x22) len--; // 最後の"(0x22)を除く if (len > 0) // 項目あり { memcpy(&data[koma_cnt].koma[0], cp0, len); // 項目の文字列をコピー data[koma_cnt].tate = tatehoukou + 1; data[koma_cnt].yoko = 9 - yokohoukou; koma_cnt = koma_cnt + 1; }else{ data[koma_cnt].tate = tatehoukou + 1; data[koma_cnt].yoko = 9 - yokohoukou; koma_cnt = koma_cnt + 1; } cp0 = cp + 1; // 次の文字のアドレス } }
shougi_banmen.csv
後香,後桂,後銀,後金,後王,後金,後銀,後桂,後香, ,後飛,,,,,,後角,, 後歩,後歩,後歩,後歩,後歩,後歩,後歩,後歩,後歩, ,,,,,,,,, ,,,,,,,,, ,,,,,,,,, 先歩,先歩,先歩,先歩,先歩,先歩,先歩,先歩,先歩, ,先角,,,,,,先飛,, 先香,先桂,先銀,先金,先王,先金,先銀,先桂,先香,
Makefile
# コンパイラの指定 CC=gcc # コンパイル時のオプション CFLAGS=-I. -Wall # 最終的な実行ファイル名 TARGET=myapp.exe # 最終ターゲット $(TARGET): shougi_shisaku.o explode.o $(CC) -o $(TARGET) shougi_shisaku.o explode.o # main.cからmain.oを生成 shougi_shisaku.o: shougi_shisaku.c $(CC) -c shougi_shisaku.c $(CFLAGS) # sub.cからsub.oを生成 explode.o: explode.c $(CC) -c explode.c $(CFLAGS) # 'make clean' を実行した時に実行ファイルとオブジェクトファイルを削除 clean: rm -f $(TARGET) shougi_shisaku.o explode.o
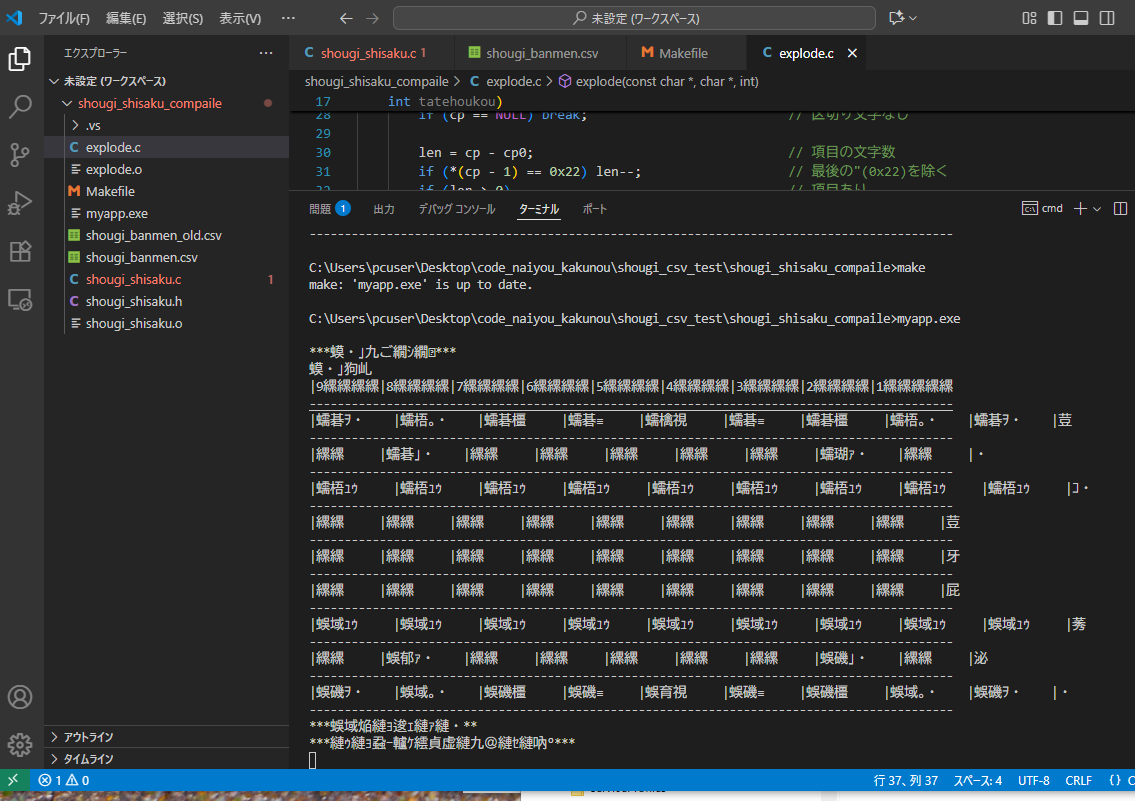
発生している問題・分からないこと
質問に詳細は記載しています。
エラーメッセージ
error
1質問に詳細は記載しています。
該当のソースコード
特になし
試したこと・調べたこと
- teratailやGoogle等で検索した
- ソースコードを自分なりに変更した
- 知人に聞いた
- その他
上記の詳細・結果
質問に詳細は記載しています。
補足
特になし
回答1件
あなたの回答
tips
プレビュー


