
実現したいこと
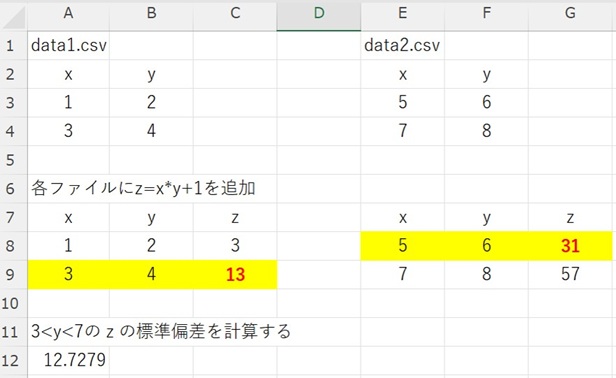
data1.csvは次のようなファイルです。
x y 1 2 3 4
data2.csvは次のようなファイルです。
x y 5 6 7 8
この2つのファイルを読み込んで、3<y<7を満たすデータだけを取り出して、z=xy+1の標準偏差を計算したいです。
やりたいことを模式的に書くと下図のようになります。
発生している問題・エラーメッセージ
Traceback (most recent call last): File "…\testCV571.py", line 9, in <module> z=x*y+1 ^ NameError: name 'x' is not defined
該当のソースコード
こちらを参考にして書きました。
python
1import pandas as pd 2import statistics 3from glob import glob 4 5ymin = 3 6ymax = 7 7 8df = pd.concat([pd.read_csv(f) for f in glob("data*csv")]) 9z=x*y+1 10l = df.query("@ymin < `y` < @ymax")["z"].tolist() 11 12print(l) 13print(statistics.stdev(l))
試したこと
9行目の先頭に#をつけ、10行目の["z"]を["y"]にすると、正しく動いて1.4142135623730951が出力されます。
回答1件
あなたの回答
tips
プレビュー



2025/12/08 06:56