
読み込んだlistの要素数を取得してループすればいいのでは?
もしくは
for row in lst
といった感じで要素でループすればいいのではないですか?
実現したいこと
test-1-01.csvは以下のようなファイルです。
Run No. A B
100 500 1
101 600 1.8
102 650 2.8
test-1-05.csvは以下のようなファイルです。
Run No. A B
200 550 2.2
201 700 3.1
test-2-14.csvは以下のようなファイルです。
Run No. A B
300 610 2.9
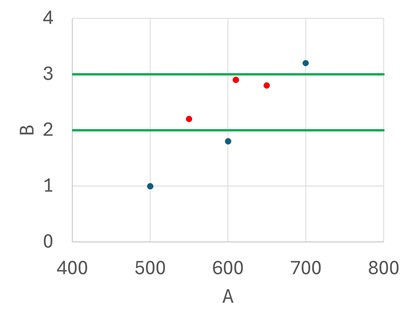
今、この3つのファイルを読み込んで横軸をA、縦軸をBにしてプロットし、2<B<3にある点だけのAの標本標準偏差を計算したいです。図示すると、下図の赤い3点のAの標本標準偏差を知りたいということで、その値はExcelで計算すると、50.33223になります。(関数STDEVを使用)
「該当のソースコード」のように書けたは書けたのですが、データ数(ファイルの行数)によって自分で入力しなければならない状態になっています。
10行目、for i in range(0,3,1):の3
16行目、for i in range(0,2,1):の2
22行目、for i in range(0,1,1):の1
今後、ファイル数が増えたときにいちいちファイルを開いて行数を確認して自分で入力することなくプログラムが動くようにするにはどのように直せば良いでしょうか。
該当のソースコード
python
1import pandas as pd 2import statistics 3 4ymin=2 5ymax=3 6 7l=[] 8 9lst = pd.read_csv("test-1-01.csv",header=0).values.tolist() 10for i in range(0,3,1): 11 if lst[i][2]>ymin and lst[i][2]<ymax: 12 print(lst[i][2])#2.8 13 l.append(lst[i][1]) 14 15lst = pd.read_csv("test-1-05.csv",header=0).values.tolist() 16for i in range(0,2,1): 17 if lst[i][2]>ymin and lst[i][2]<ymax: 18 print(lst[i][2])#2.2 19 l.append(lst[i][1]) 20 21lst = pd.read_csv("test-2-14.csv",header=0).values.tolist() 22for i in range(0,1,1): 23 if lst[i][2]>ymin and lst[i][2]<ymax: 24 print(lst[i][2])#2.9 25 l.append(lst[i][1]) 26 27print(l)#[650.0, 550.0, 610.0] 28print(statistics.stdev(l))#50.33222956847167
試したこと
こちらを参考にするとglobを使えばできるような気がしたのですが、globに慣れていなくて、2<B<3を満たすデータだけを抜き出すところの書き方がよく分かりませんでした。
回答1件
あなたの回答
tips
プレビュー


