
質問の説明の意味がわからないのはぼくだけだろうか。
各塊は、
x座標
y座標
z座標
値
のような構成で、 ファイルにはたとえば、
4
0
0
13
とあるので、これが対応しているのだろうと思います。
で、(x, y, z) = (4, 0, 0)の値が13なので、 表の(y, z) = (0, 0) のところが13になっているのでいいのですが、
5
0
0
8
この8は、どこにあるものですか?
あと、xはどこにいった?
また、「対角状に並べるデータのサイズは最大で2×2です。」の意味もわかりません。何をどこに対角状にならべるのでしょう。
実現したいこと
sample10.txtは以下のようなファイルです。
4
0
0
13
sample20.txtは以下のようなファイルです。
5
0
0
8
5
0
1
4
5
1
1
1
sample30.txtは以下のようなファイルです。
6
0
0
5
6
1
0
8
各塊は、
x座標
y座標
z座標
値
の順番に並んでいます。
このデータを以下の図のようなデータにしたいです。
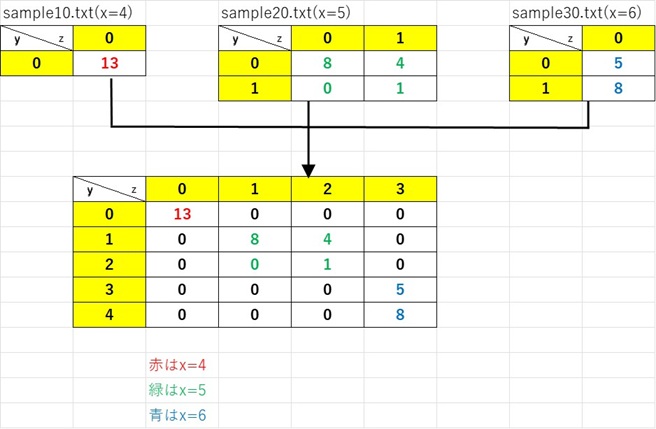
対角状に並べるデータのサイズは最大で2×2です。(1×1、1×2、2×1、2×2があり得ます)
一応できたのですが、14~27行目は似たような内容を書いています。
今はsample10.txt、sample20.txt、sample30.txtの3つのファイルですが、もっとファイルの個数が多くなることを想定しています。ファイルの個数が多くなったときには、コードをどのように直したら良いでしょうか。
該当のソースコード
python
1import numpy as np 2import pandas as pd 3from scipy.linalg import block_diag 4 5cols = 2 6rows = 2 7R10 = np.arange(rows*cols,dtype=np.float32).reshape(rows,cols) 8R10[...] = 0 9R20 = np.arange(rows*cols,dtype=np.float32).reshape(rows,cols) 10R20[...] = 0 11R30 = np.arange(rows*cols,dtype=np.float32).reshape(rows,cols) 12R30[...] = 0 13 14with open('sample10.txt') as f: 15 blocks = f.read().split('\n\n') 16R10[0][0] = int(blocks[0].split('\n')[3]) 17 18with open('sample20.txt') as f: 19 blocks = f.read().split('\n\n') 20R20[0][0] = int(blocks[0].split('\n')[3]) 21R20[0][1] = int(blocks[1].split('\n')[3]) 22R20[1][1] = int(blocks[2].split('\n')[3]) 23 24with open('sample30.txt') as f: 25 blocks = f.read().split('\n\n') 26R30[0][0] = int(blocks[0].split('\n')[3]) 27R30[1][0] = int(blocks[1].split('\n')[3]) 28 29A = block_diag(R10, R20, R30) 30print(A) 31#[[13. 0. 0. 0. 0. 0.] 32# [ 0. 0. 0. 0. 0. 0.] 33# [ 0. 0. 8. 4. 0. 0.] 34# [ 0. 0. 0. 1. 0. 0.] 35# [ 0. 0. 0. 0. 5. 0.] 36# [ 0. 0. 0. 0. 8. 0.]] 37 38A = A[np.ix_(~np.all(A == 0, axis=1), ~np.all(A == 0, axis=0))] 39print(A) 40#[[13. 0. 0. 0.] 41# [ 0. 8. 4. 0.] 42# [ 0. 0. 1. 0.] 43# [ 0. 0. 0. 5.] 44# [ 0. 0. 0. 8.]]
試したこと
データファイルを1個のフォルダの中にまとめて保存し、その中のファイルについて14~27行目のような操作をすれば良いのではないかと考えています。あるいは、ファイル名を関数の変数にすれば良いかなと思っています。(やり方が分かりませんでした)
sample10.txt、sample20.txt、sample30.txtの行数を調べると、
python
1nl = len(open('sample10.txt').readlines()) 2print(nl)#4 3nl = len(open('sample20.txt').readlines()) 4print(nl)#14 5nl = len(open('sample30.txt').readlines()) 6print(nl)#9
なので、14、18、24行目の場合分けは、ファイルの行数で行えば良いかなと思っています。
>TakaiY様
コメントありがとうございます。
説明が分かりづらくて申し訳ありません。図を直しましたので、ご確認ください。
そういうことだしたか。理解できました。 ありがとうございます。
回答1件
あなたの回答
tips
プレビュー


