
csvの一行目をご提示ください。
機械学習で分類を行うプログラムをアヤメの分類のプログラムを元に作りました。
以下プログラムとエラーです。何かわかりましたらよろしくお願いします。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.metrics import accuracy_score # アヤメデータの読み込み --- (*1) analysisresults_data = pd.read_csv("analysis_results.csv", encoding="utf-8") # アヤメデータをラベルと入力データに分離する --- (*2) y = analysisresults_data.loc[:,"結果"] x = analysisresults_data.loc[:,["番号1","番号2","番号3","URL","日付"]] # 学習用とテスト用に分離する --- (*3) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, train_size = 0.7, shuffle = True) # 学習する --- (*4) clf = SVC() clf.fit(x_train, y_train) # 評価する --- (*5) y_pred = clf.predict(x_test) print("正解率 = " , accuracy_score(y_test, y_pred))
Traceback (most recent call last):
File "4iris.py", line 7, in <module>
analysisresults_data = pd.read_csv("analysis_results.csv", encoding="utf-8")
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/pandas/io/parsers.py", line 702, in parser_f
return _read(filepath_or_buffer, kwds)
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/pandas/io/parsers.py", line 429, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/pandas/io/parsers.py", line 895, in init
self._make_engine(self.engine)
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/pandas/io/parsers.py", line 1122, in _make_engine
self._engine = CParserWrapper(self.f, **self.options)
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/pandas/io/parsers.py", line 1853, in init
self._reader = parsers.TextReader(src, **kwds)
File "pandas/_libs/parsers.pyx", line 542, in pandas._libs.parsers.TextReader.cinit
File "pandas/_libs/parsers.pyx", line 782, in pandas._libs.parsers.TextReader._get_header
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x94 in position 0: invalid start byte
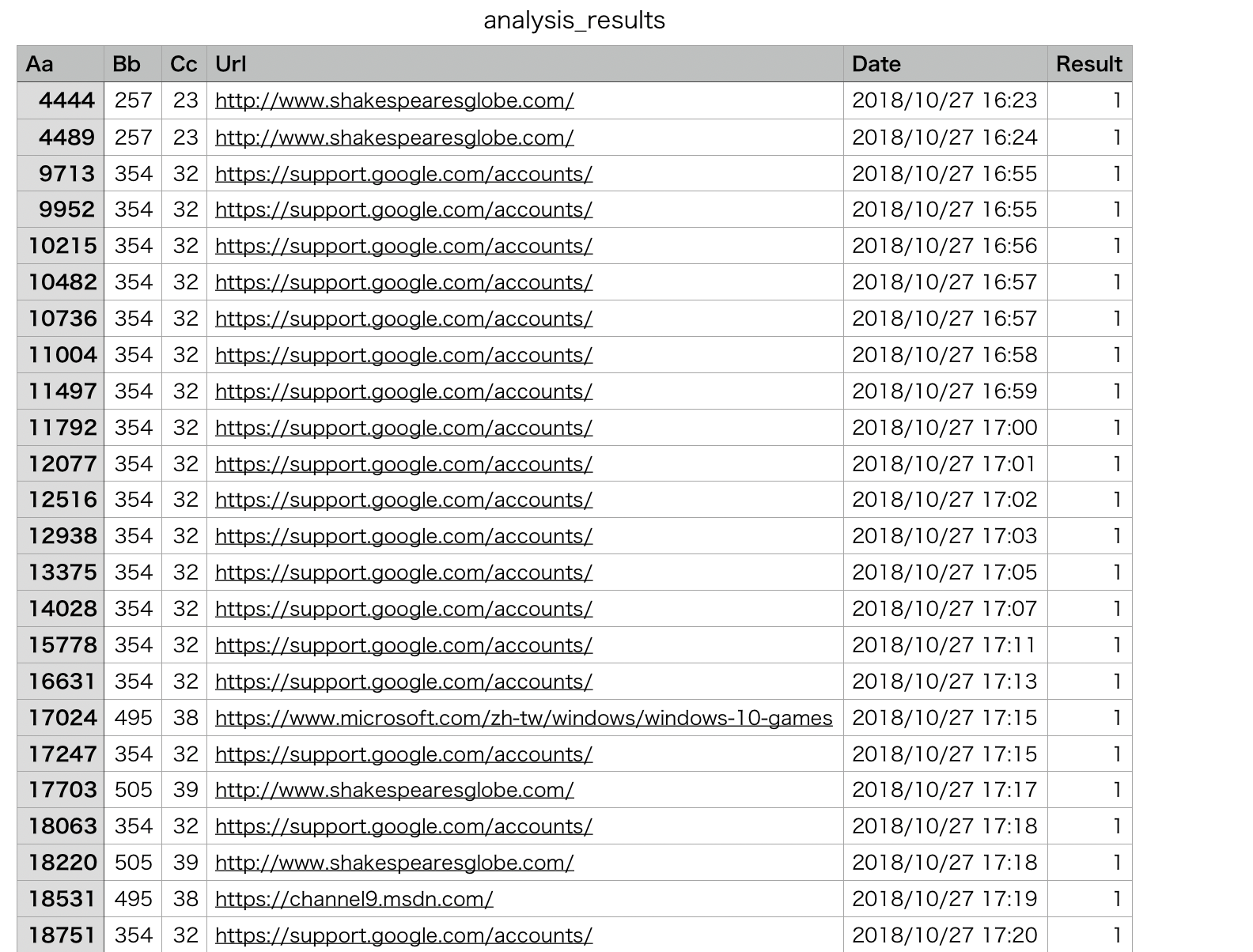
analysis_results.csv
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# アヤメデータの読み込み --- (*1)
analysisresults_data = pd.read_csv("analysis_results.csv", encoding="utf-8")
# アヤメデータをラベルと入力データに分離する --- (*2)
y = analysisresults_data.loc[:,"Result"]
x = analysisresults_data.loc[:,["Aa","Bb","Cc","Url","Date"]]
# 学習用とテスト用に分離する --- (*3)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, train_size = 0.7, shuffle = True)
# 学習する --- (*4)
clf = SVC()
clf.fit(x_train, y_train)
# 評価する --- (*5)
y_pred = clf.predict(x_test)
print("正解率 = " , accuracy_score(y_test, y_pred))
csvの一行目
Aa Bb Cc Url Date Result
少し変更点ありますがよろしくお願いします。
Aa Bb Cc Url Date Result
は元のままですか? そうでなければ、元の文字列をご提示ください。
また追加になりますが、どのようにして得たCSVファイルなのかも併せて教えていただいた方が良いかもしれません。
csvファイルを追記しました。
このCSVファイルはデータベースサーバからscpを使ってコピーをして得たデータです。
データベースのテーブルから
select * from analysis_results where analysis_result = 1 limit 10000 INTO OUTFILE '/tmp/analysis_resultstable.csv' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"';
をして
ローカルから
scp j16040@202.26.158.105:/tmp/analysis_resultstable.csv ~/Desktop/
をして取り出しました。
Excelでutf-8で保存したらエラー内容が減りました。
以下のエラーが出ます何かわかりますでしょうか?
Traceback (most recent call last):
File "analysis_results.py", line 18, in <module>
clf.fit(x_train, y_train)
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/sklearn/svm/base.py", line 146, in fit
accept_large_sparse=False)
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/sklearn/utils/validation.py", line 719, in check_X_y
estimator=estimator)
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/sklearn/utils/validation.py", line 496, in check_array
array = np.asarray(array, dtype=dtype, order=order)
File "/Users/idaryuunosuke/.pyenv/versions/anaconda3-5.3.1/envs/py35/lib/python3.5/site-packages/numpy/core/numeric.py", line 538, in asarray
return array(a, dtype, copy=False, order=order)
ValueError: could not convert string to float: '2018/11/18 11:18'
>ValueError: could not convert string to float: '2018/11/18 11:18'
エラーの内容が最後に出てますけど。
調べたのですがこれは具体的にどこを直せばいいのでしょうか?
データがおかしくないですか?
以下エラー全て最後の文章です。
どうやらCSVファイルが読み込めてないみたいです。
何か対策があればよろしくお願いします。
ValueError: could not convert string to float: '2018/12/19 10:13'
ValueError: could not convert string to float: '2019/1/7 9:13'
ValueError: could not convert string to float: '2019/1/17 4:01'
ValueError: could not convert string to float: '2018/11/9 10:07'
日付と時間が表示されてますよね?これは読み込んだCSVファイルの内容では無いですか?
だとしたら読み込めてますよね?
ValueError=値のエラーです。簡単な英語ですよね。
値のエラーというのは何をしたら良いのでしょうか?
>値のエラーというのは何をしたら良いのでしょうか?
値がおかしいので値を修正する必要があります。
>could not convert string to float: '2018/11/9 10:07'
「StringからFloatに変換することが出来ません」と言う理由が表示されていますが、日付を数値(浮動小数点)に変換しようとしているようです。
アヤメをSVMで分類するのに日付は要らないのでは?と思いますし、数値に変換する処理はコードを見る限りは判りませんでした。
回答2件
あなたの回答
tips
プレビュー


