

現在、深層学習について勉強中です。
Attention機構について理解につまっている部分があります。
Seq2Seqモデルにおいて利用されるAttention機構という前提でお伺いしたいのですが、
時刻tにおけるDecoderの出力__Y(t)を計算する際、これはどのように計算されるのでしょうか。
私の現状の理解では、Encoderの出力__O(1~N)(NはEncoderの系列長)とDecoderの出力__Y(t)__を利用してAttention機構から__C(t)__を計算し、再び__C(t)__と__Y(t)__を結合してからtanhなどの活性化関数にかけるものだと思っていました。
しかし、TensorflowのAttentionのチュートリアルではどうも違うように実装されているように思えます。チュートリアルページ(英語)
上記のページでは__C(t)__を計算する際に__Y(t-1)__を用いており、また、GRU層に入力する前に__C(t)__と入力を結合しています。
つまり、時刻tの出力__Y(t)__を得る時、Attentionの計算は時刻tのGRUの出力__Y(t)__を利用するのか、前時刻(t-1)のGRUの出力__Y(t-1)__を利用するのかを知りたいです。
以下に現状の理解の齟齬を画像にしたので載せておきます。上が自分の中での理解で、下がTensorflowのチュートリアルにあったものを自分なりに図にしたものです。
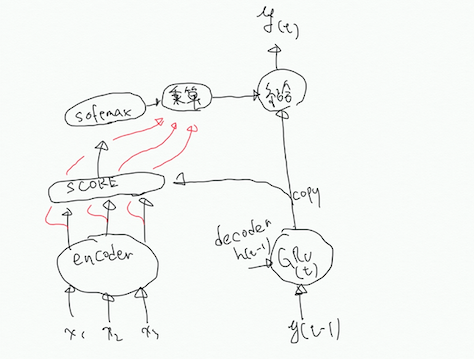

線の色に特に意味はないです。
また、RNN系のネットワークでは前時刻の状態__h(t-1)__を時刻tの入力に用いるという風に理解しているのですが、ここでいう__h(t-1)__というのは前時刻のRNNの出力である__Y(t-1)__と同義でしょうか。
稚拙な質問で申し訳ないですが、ご存知の方がいらっしゃったら、ご教授いただけると幸いです。
あなたの回答
tips
プレビュー


