


ありがとうございます!
Groupbyは全く考えになかったので、大変勉強になりました。
わざわざご丁寧にありがとうございます。
お世話になっております。
Pandasのデータフレームのマージ機能を使って下記図のようなことをやりたいです
もし、共通のものがあれば新しい行を作成して追加するのではなく、新しい列を追加してそこに追加する
行数は変えない。という感じです
下記図の場合、新しく追加するTitle列のコラム名前はどんなものでも構いません
※下記図のDataA基準というのはDataAのHash基準、という意味です
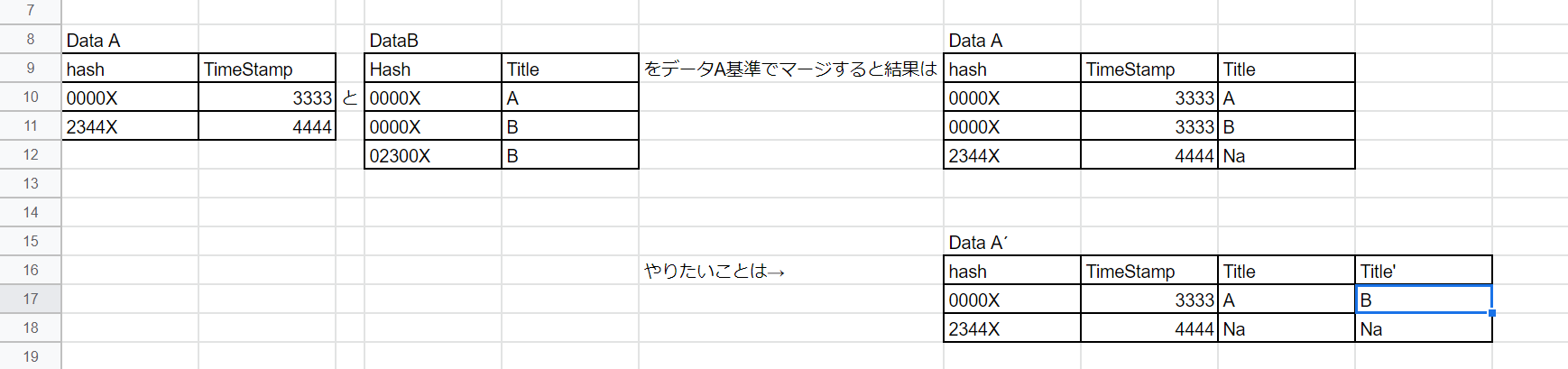
考え方だけでも良いのでご教示いただけますと幸いです。
一応下記にデータフレームのコードを貼っておきます。
dfA = pd.DataFrame({'HASH':['000x','001X'],'TimeStamp':['11','22']}) dfB = pd.DataFrame({'HASH':['000x','000x','003x'], 'Title':['A','B','C']})
宜しくお願い致します。
回答2件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2019/04/19 07:52