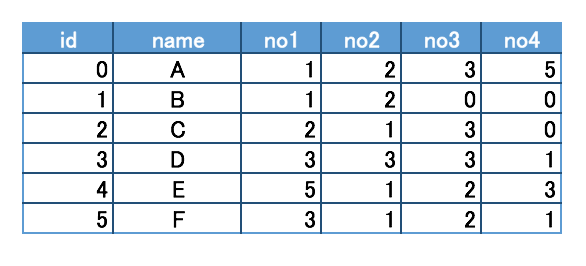
1mysql>SELECT id, name FROM tbl AS t1 WHEREEXISTS(2->SELECT*FROM tbl AS t2
3->WHERE t1.id = t2.no1
4->OR t1.id = t2.no2
5->OR t1.id = t2.no3
6->OR t1.id = t2.no4
7->);8+----+------+9| id | name |10+----+------+11|0| A |12|1| B |13|2| C |14|3| D |15|5| F |16+----+------+175rowsinset(0.00 sec)
このクエリだと、以下の通り2回の全表走査で済みます。
SQL
1mysql>EXPLAINSELECT id, name FROM tbl AS t1 WHEREEXISTS(2->SELECT*FROM tbl AS t2
3->WHERE t1.id = t2.no1
4->OR t1.id = t2.no2
5->OR t1.id = t2.no3
6->OR t1.id = t2.no4
7->);8+----+--------------------+-------+------+---------------+------+---------+------+------+-------------+9| id | select_type |table|type| possible_keys |key| key_len | ref |rows| Extra |10+----+--------------------+-------+------+---------------+------+---------+------+------+-------------+11|1|PRIMARY| t1 |ALL|NULL|NULL|NULL|NULL|6|Usingwhere|12|2| DEPENDENT SUBQUERY | t2 |ALL|NULL|NULL|NULL|NULL|6|Usingwhere|13+----+--------------------+-------+------+---------------+------+---------+------+------+-------------+142rowsinset(0.00 sec)