

前提・実現したいこと
リストの各要素の出現個数をカウントして最頻値の要素を全て出力しようとしています。
具体的には以下のことを実現したいです。
l = ['a', 'a', 'a', 'a', 'b', 'c', 'c', 'c', 'c'] であれば ['a', 'c']
発生している問題・エラーメッセージ
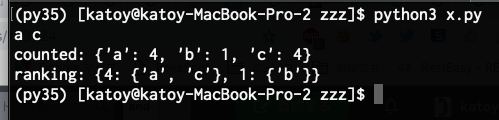
現状のコードでは、最頻値のカウントと文字の特定はできていますが、配列の0番目のものしか取得できず、最頻値が同値であってもすべての要素を取得できていない状態です。
PythonのCounterを使っているので、どのようにすれば、全ての最頻値の要素を取得できるかわからないので困っています。
現在の出力結果
a
該当のソースコード
Python
1import collections 2l = ['a', 'a', 'a', 'a', 'b', 'c', 'c', 'c', 'c'] 3counted = collections.Counter(l) 4#最頻値が同値である場合全て出力したい 5print(counted.most_common()[0][0]) 6#頻出数ではなく、文字だけ出力したい
補足情報(FW/ツールのバージョンなど)
Python3.6
回答4件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
退会済みユーザー
2018/11/21 09:31
2018/11/21 10:51
退会済みユーザー
2018/11/22 11:43