
以下のページから同じ内容のファイルをダウンロードすることができる様です。
https://drive.google.com/u/0/uc?id=0B7XkCwpI5KDYNlNUTTlSS21pQmM&export=download
恐らくファイルリンクを変更しないといけないはずですが、どの部分を変更すればよいのか分かりません。
自然言語処理(テキスト処理)を行うにあたり、いまにゅさんの動画を参考にしています。
https://www.youtube.com/watch?v=gPV7SuZiVu4
上記動画に添付してある講義内使用コードをコピペし内容理解に取り組んでいるのですが、「15.単語ベクトルの読み込み」で下記コード
FILE_ID = "0B7XkCwpI5KDYNlNUTTlSS21pQmM" FILE_NAME = "GoogleNews-vectors-negative300.bin.gz" !wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt
を入力すると、
--2022-10-05 07:26:16-- https://docs.google.com/uc?export=download&confirm=&id=0B7XkCwpI5KDYNlNUTTlSS21pQmM Resolving docs.google.com (docs.google.com)... 172.253.63.101, 172.253.63.138, 172.253.63.139, ... Connecting to docs.google.com (docs.google.com)|172.253.63.101|:443... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘GoogleNews-vectors-negative300.bin.gz’ GoogleNews-vectors- [ <=> ] 2.33K --.-KB/s in 0s 2022-10-05 07:26:16 (41.2 MB/s) - ‘GoogleNews-vectors-negative300.bin.gz’ saved [2386]
と返ってきます。
講義内使用コードと比較すると返ってきたメッセージは異なりますが、エラーにはならなかったので、次の
from gensim.models import KeyedVectors
を入力し
model = KeyedVectors.load_word2vec_format('/content/GoogleNews-vectors-negative300.bin.gz', binary=True)
上記コードを実行すると、
--------------------------------------------------------------------------- OSError Traceback (most recent call last) <ipython-input-3-e3c3e0db66bd> in <module> ----> 1 model = KeyedVectors.load_word2vec_format('/content/GoogleNews-vectors-negative300.bin.gz', binary=True) 5 frames /usr/local/lib/python3.7/dist-packages/gensim/models/keyedvectors.py in load_word2vec_format(cls, fname, fvocab, binary, encoding, unicode_errors, limit, datatype) 1436 return _load_word2vec_format( 1437 cls, fname, fvocab=fvocab, binary=binary, encoding=encoding, unicode_errors=unicode_errors, -> 1438 limit=limit, datatype=datatype) 1439 1440 def get_keras_embedding(self, train_embeddings=False): /usr/local/lib/python3.7/dist-packages/gensim/models/utils_any2vec.py in _load_word2vec_format(cls, fname, fvocab, binary, encoding, unicode_errors, limit, datatype) 170 logger.info("loading projection weights from %s", fname) 171 with utils.smart_open(fname) as fin: --> 172 header = utils.to_unicode(fin.readline(), encoding=encoding) 173 vocab_size, vector_size = (int(x) for x in header.split()) # throws for invalid file format 174 if limit: /usr/lib/python3.7/gzip.py in readline(self, size) 383 def readline(self, size=-1): 384 self._check_not_closed() --> 385 return self._buffer.readline(size) 386 387 /usr/lib/python3.7/_compression.py in readinto(self, b) 66 def readinto(self, b): 67 with memoryview(b) as view, view.cast("B") as byte_view: ---> 68 data = self.read(len(byte_view)) 69 byte_view[:len(data)] = data 70 return len(data) /usr/lib/python3.7/gzip.py in read(self, size) 472 # jump to the next member, if there is one. 473 self._init_read() --> 474 if not self._read_gzip_header(): 475 self._size = self._pos 476 return b"" /usr/lib/python3.7/gzip.py in _read_gzip_header(self) 420 421 if magic != b'\037\213': --> 422 raise OSError('Not a gzipped file (%r)' % magic) 423 424 (method, flag, OSError: Not a gzipped file (b'<!')
上記のようなエラーメッセージが出てしまいました。
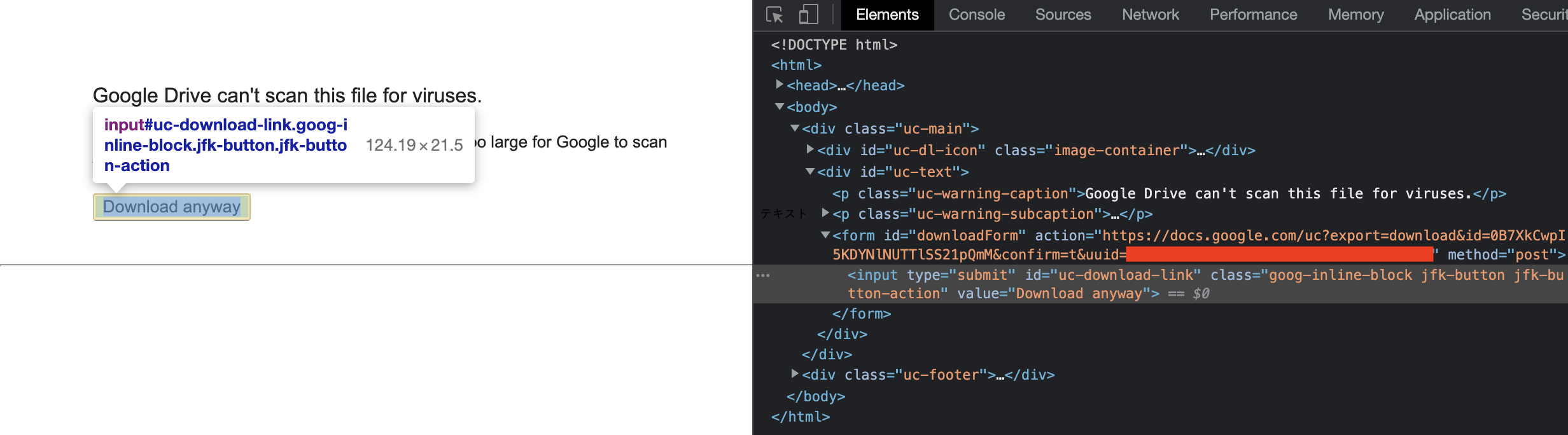
「Not a gzipped file (b'<!')のエラー」として、他サイトhttps://ja.stackoverflow.com/questions/78347/not-a-gzipped-file-b%E3%81%AE%E3%82%A8%E3%83%A9%E3%83%BC
の回答を参考にしようと思ったのですが、回答者さんがどの様にしてダウンロード出来たのかも分かりません…。
(https://~ だったのでブラウザで検索をかけましたが、結局エラーコードが表示され余計に分からなくなりました。)
上記コードのどこを修正すれば、エラーせず次のコードに進めるのか教えていただきたいです。
追記
melian様よりいただいたリンクにてファイルをダウンロードすることが出来ました。
model = KeyedVectors.load_word2vec_format('/content/GoogleNews-vectors-negative300.bin.gz', binary=True)
ファイルのパスを入れ直し実行したところ、以下の様に異なるエラーが出てきました。
--------------------------------------------------------------------------- EOFError Traceback (most recent call last) <ipython-input-3-e3c3e0db66bd> in <module> ----> 1 model = KeyedVectors.load_word2vec_format('/content/GoogleNews-vectors-negative300.bin.gz', binary=True) 4 frames /usr/local/lib/python3.7/dist-packages/gensim/models/keyedvectors.py in load_word2vec_format(cls, fname, fvocab, binary, encoding, unicode_errors, limit, datatype) 1436 return _load_word2vec_format( 1437 cls, fname, fvocab=fvocab, binary=binary, encoding=encoding, unicode_errors=unicode_errors, -> 1438 limit=limit, datatype=datatype) 1439 1440 def get_keras_embedding(self, train_embeddings=False): /usr/local/lib/python3.7/dist-packages/gensim/models/utils_any2vec.py in _load_word2vec_format(cls, fname, fvocab, binary, encoding, unicode_errors, limit, datatype) 210 word.append(ch) 211 word = utils.to_unicode(b''.join(word), encoding=encoding, errors=unicode_errors) --> 212 weights = fromstring(fin.read(binary_len), dtype=REAL).astype(datatype) 213 add_word(word, weights) 214 else: /usr/lib/python3.7/gzip.py in read(self, size) 285 import errno 286 raise OSError(errno.EBADF, "read() on write-only GzipFile object") --> 287 return self._buffer.read(size) 288 289 def read1(self, size=-1): /usr/lib/python3.7/_compression.py in readinto(self, b) 66 def readinto(self, b): 67 with memoryview(b) as view, view.cast("B") as byte_view: ---> 68 data = self.read(len(byte_view)) 69 byte_view[:len(data)] = data 70 return len(data) /usr/lib/python3.7/gzip.py in read(self, size) 491 break 492 if buf == b"": --> 493 raise EOFError("Compressed file ended before the " 494 "end-of-stream marker was reached") 495 EOFError: Compressed file ended before the end-of-stream marker was reached

ありがとうございます。
無事ダウンロード出来ました!
ファイルにドラッグアンドドロップで追加し、
model = KeyedVectors.load_word2vec_format('/content/GoogleNews-vectors-negative300.bin.gz',binary=True)
で実行したのですが、やはりエラーとなってしまいました…
FILE_ID = "0B7XkCwpI5KDYNlNUTTlSS21pQmM"
FILE_NAME = "GoogleNews-vectors-negative300.bin.gz"
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt
二つ前のこのコードの時点で何か間違っているのでしょうか?
エラーの内容は同じでしたか?
異なるエラーが出ました。
質問にエラー文の追記と作業画面の画像も添付しております。
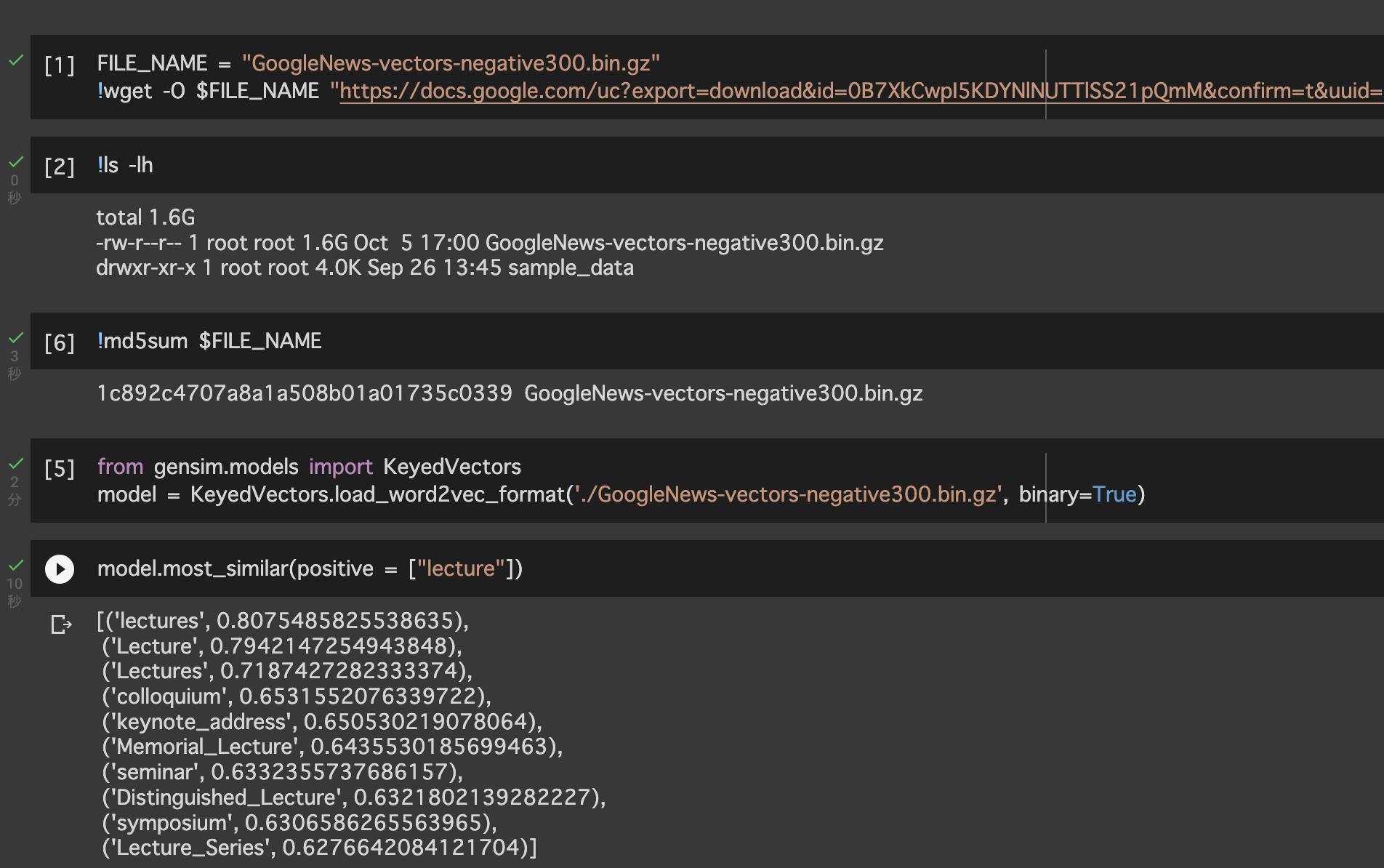
wgetのダウンロードプログレスバーから察するに,まだファイルのダウンロードが終わっていないようにも見えます.全体で1.5[GB]あるそうなのですが,ls -lhコマンドでファイルサイズを確認して同じファイルサイズになっていますか?ちなみにNot a gzipped file (b'<!')と言われたときは2.4[KB]しかありませんでした.
ちゃんとファイル全体1.5[GB]をダウンロードした後は正常に実行できましたのでダウンロード未完了説が考えられます.
回答1件
あなたの回答
tips
プレビュー


