



ご回答ありがとうございます!stack()というのは、列のデータを行にピポッド(?)させるようなイメージの処理のようなのですが、index_col=0を指定してあげないときちんと動かないのでしょうか。
また、このコードだと2階層の場合はできそうに思うのですが、n階層のように一般化することは難しいでしょうか。(stackを、階層分コールする?実務では、この部分がたまに3階層、4階層のものが出てきてしまっています…)
前提・実現したいこと
下記の図のように、Excelから読み込んだ、複数列にまたがってヘッダが存在するデータを、
縦持ちに変換したいと考えています。
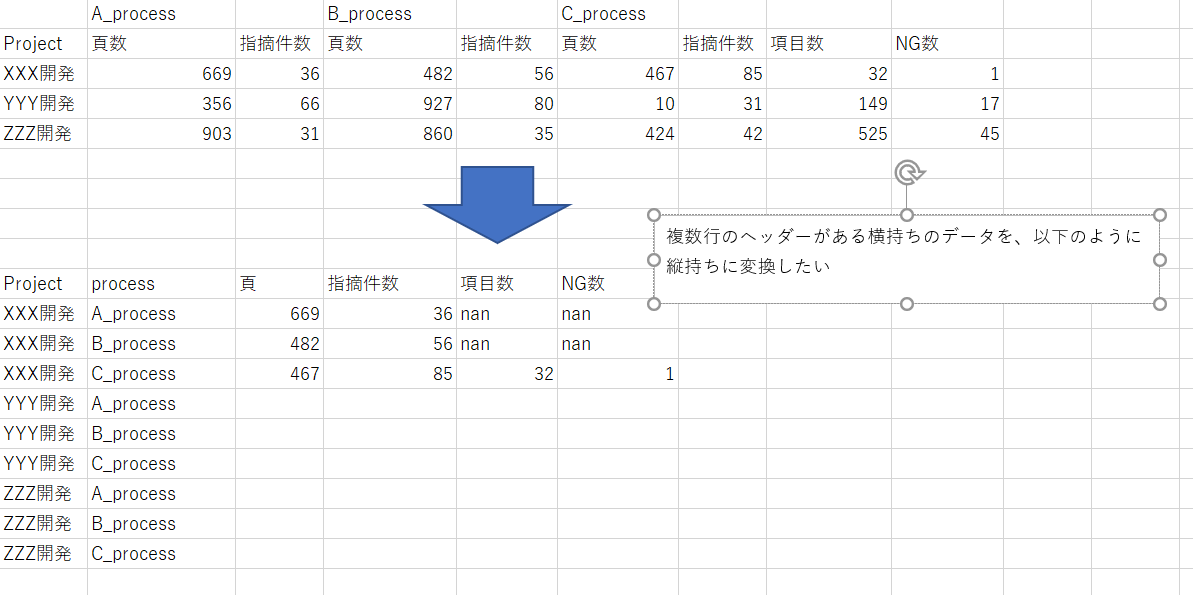
やり方を調べていると、meltを使うと実現できそうなので、参考URLをもとに、meltを実施したのですが、下記エラーが出てしまいました。下記2点についてご教示いただけましたら幸甚です。
①下記コードのどこがまずいのかご教示いただけないでしょうか。
(エラーコードを見る限り、A_Processのキーが見つけられないように見えるのですが、指定に問題があるのでしょうか。データの渡し方などに問題あり?)
②複数列にまたがるデータを縦持ちに変換するシンプルで一般的な方法があれば(メソッド化できる?)
ご教示いただけますでしょうか。
発生している問題・エラーメッセージ
KeyError: 'A_process' --------------------------------------------------------------------------- KeyError Traceback (most recent call last) ~\AppData\Local\Temp/ipykernel_28196/3457535453.py in <module> ----> 1 df = df.melt( 2 id_vars=id_vars, 3 value_vars=value_vars, 4 ) ~\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\frame.py in melt(self, id_vars, value_vars, var_name, value_name, col_level, ignore_index) 8333 ) -> DataFrame: 8334 -> 8335 return melt( 8336 self, 8337 id_vars=id_vars, ~\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\reshape\melt.py in melt(frame, id_vars, value_vars, var_name, value_name, col_level, ignore_index) 135 mdata = {} 136 for col in id_vars: --> 137 id_data = frame.pop(col) 138 if is_extension_array_dtype(id_data): 139 id_data = cast("Series", concat([id_data] * K, ignore_index=True)) ~\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\frame.py in pop(self, item) 5219 3 monkey NaN 5220 """ -> 5221 return super().pop(item=item) 5222 5223 @doc(NDFrame.replace, **_shared_doc_kwargs) ~\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\generic.py in pop(self, item) 865 866 def pop(self, item: Hashable) -> Series | Any: --> 867 result = self[item] 868 del self[item] 869 ~\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\frame.py in __getitem__(self, key) 3452 if is_single_key: 3453 if self.columns.nlevels > 1: -> 3454 return self._getitem_multilevel(key) 3455 indexer = self.columns.get_loc(key) 3456 if is_integer(indexer): ~\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\frame.py in _getitem_multilevel(self, key) 3503 def _getitem_multilevel(self, key): 3504 # self.columns is a MultiIndex -> 3505 loc = self.columns.get_loc(key) 3506 if isinstance(loc, (slice, np.ndarray)): 3507 new_columns = self.columns[loc] ~\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\indexes\multi.py in get_loc(self, key, method) 2920 2921 if not isinstance(key, tuple): -> 2922 loc = self._get_level_indexer(key, level=0) 2923 return _maybe_to_slice(loc) 2924 ~\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\core\indexes\multi.py in _get_level_indexer(self, key, level, indexer) 3221 if start == end: 3222 # The label is present in self.levels[level] but unused: -> 3223 raise KeyError(key) 3224 return slice(start, end) 3225 KeyError: 'A_process'
該当のソースコード
Python3
1import pandas as pd 2df = pd.read_excel("test_viz_proj.xlsx", header=[0,1]) 3 4# 縦持ち変換 5id_vars = ["A_process", "B_process", "C_process"] 6value_vars = ["頁数", "指摘件数", "項目数", "NG数"] 7 8df = df.melt( 9 id_vars=id_vars, 10 value_vars=value_vars, 11)
試したこと
複数行の横持データを縦持ちデータに変換するための方法を調査した。
補足情報(FW/ツールのバージョンなど)
python 3.9.6
pandas 1.3.0
回答2件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2021/09/01 06:12