



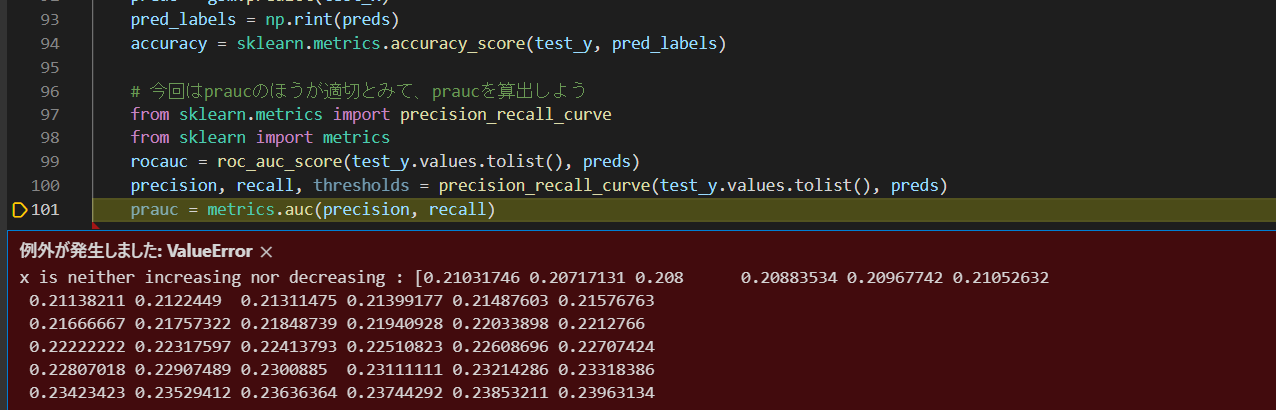
不均衡データの最適化に際し、praucを以下のコードから算出しようとすると、画像のエラーが発生しました。
エラー文を見ると、praucが増えても減ってもいないという不可解なエラーでした。疑問点は次の通りです。
①はじめてpraucを自分で実装したので、precision, recall, thresholds = precision_recall_curve(test_y.values.tolist(), preds)
で算出したprecisionとrecallに対して metrics.auc(precision, recallを適用するという考えが間違っているかどうか。ただし、recall,precisionのシェイプは一致していて、rocaucを出すのと同様にこの場合でも成功するのではないかと考えています。
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.auc.html
の説明と実装例からも、私のやろうとしていることがあっているような印象を受けました。
②praucを算出するときに増減は問題にならないにもかかわらず、このようなエラーが出ている理由と私の認識の誤りは何でしょうか。
以上、よろしくお願いいたします。
エラー部分 from sklearn.metrics import precision_recall_curve from sklearn import metrics rocauc = roc_auc_score(test_y.values.tolist(), preds) precision, recall, thresholds = precision_recall_curve(test_y.values.tolist(), preds) prauc = metrics.auc(precision, recall) 一行うえでエラー発生
auc_list=[] def objective(trial): logger.info('{} START:'.format(trial.number)) data = pd.read_pickle(f'{PATH}prd_tr.pkl') test = pd.read_pickle(f'{PATH}prd_te.pkl') target = pd.read_pickle(f'{PATH}y.pkl') # random_state固定しないほうがはんかできてよさげか train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.25,stratify=target) dtrain = lgb.Dataset(train_x, label=train_y) dtest = lgb.Dataset(test_x, label=test_y) param = { 'objective': 'binary', 'metric': 'auc', 'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0), 'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0), 'num_leaves': trial.suggest_int('num_leaves', 2, 256), 'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0), 'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0), 'bagging_freq': trial.suggest_int('bagging_freq', 1, 7), 'min_child_samples': trial.suggest_int('min_child_samples', 5, 100), } pruning_callback = optuna.integration.LightGBMPruningCallback(trial, 'auc') gbm = lgb.train(param, dtrain,valid_sets=dtest, callbacks=[pruning_callback]) preds = gbm.predict(test_x) pred_labels = np.rint(preds) accuracy = sklearn.metrics.accuracy_score(test_y, pred_labels) # 今回はpraucのほうが適切とみて、praucを算出しよう from sklearn.metrics import precision_recall_curve from sklearn import metrics rocauc = roc_auc_score(test_y.values.tolist(), preds) precision, recall, thresholds = precision_recall_curve(test_y.values.tolist(), preds) prauc = metrics.auc(precision, recall) auc_list.append(rocauc) logger.info(' CURRENT MAX AUC: {}'.format(rocauc)) logger.info(' accuracy:{}'.format(accuracy)) return rocauc if __name__ == "__main__": study = optuna.create_study(direction="maximize") study.optimize(objective, n_trials=2000,timeout=3600) # 目的関数を10回呼び出し、その中で得られた最も良い評価値(ここでは最小化問題を考えます)とそのパラメーターを出力します。
回答1件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。