



使用するデータ
使用するデータは以下のような短時間の時系列データです.
左の画像:右方向の短時間時系列データ
右の数字:その時系列に対する教師データ(0または1)

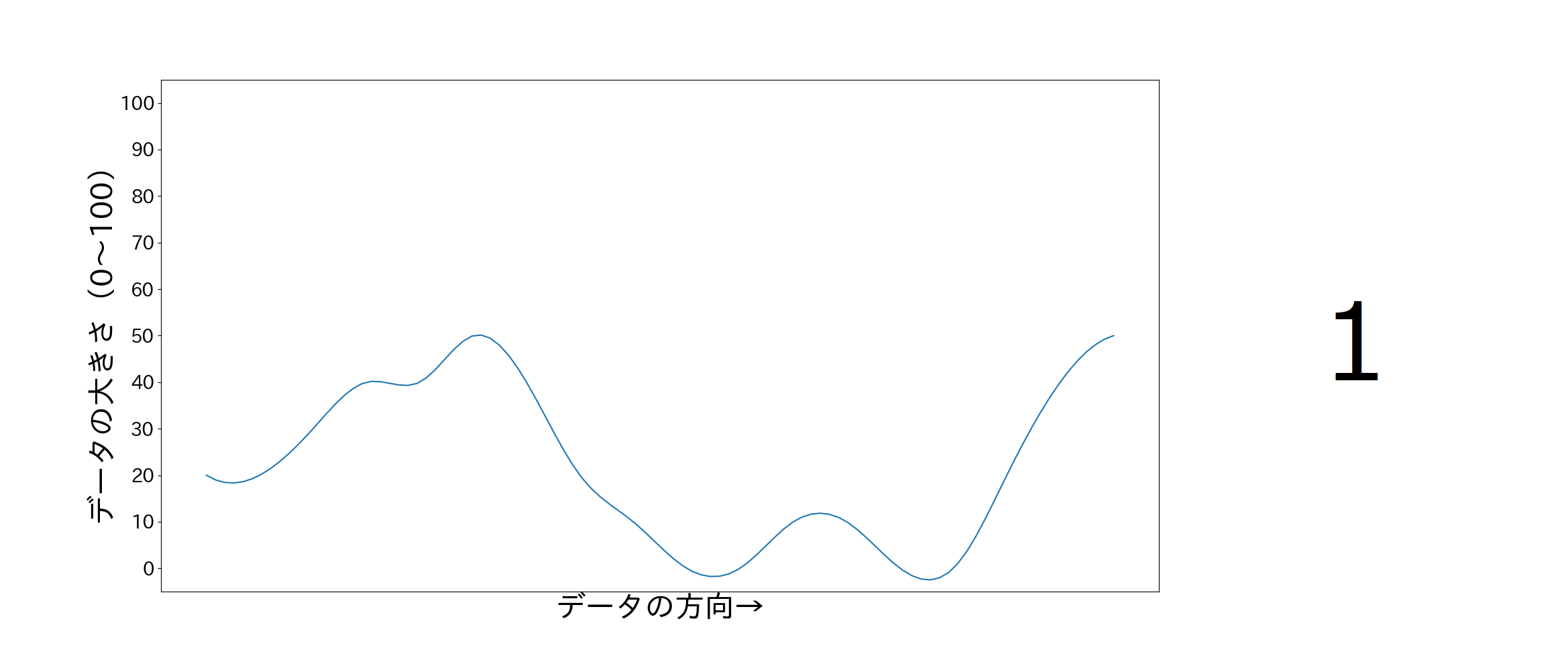
※このような短時間の時系列データとそれに対応する教師データは約1000件ほどあります.
データの特徴(ヒトが見た感じ)
ヒトが上記に示した使用する2件データを見ると,
- 時系列データの最終データが小さければ,0になりやすい
- 時系列データの最終データが大きければ,1になりやすい
という特徴が見えてくるはずです.
※2件では断定できませんが,全データを見た場合でも上記のような特徴をつかめています(ヒト).
機械学習によって特徴をつかみたい
上記に示す,ヒトでは感じ取れるデータの特徴を機械学習によって学習できないかと模索しております.
ただデータの特徴というだけでは抽象的すぎるため,実際に得られてほしいデータとしては,1になる確率です.
ヒトが感じる「最終データが大きければ1になりやすい」というのは言い換えると「1になる確率」とも言えます.
したがって,学習モデルから必要とする最終的なデータとしては1になる確率です.
現在分かっていること
このような問題は2値分類に相当すると考えています.すなわち,学習時の最終層にはsigmoid関数を用意し,1になる確率を算出するのだと思います.
また,現在はKerasのSimpleRNNを用いて以下のようなモデルを構成しています.
model = Sequential() model.add(Masking(mask_value=-1, input_shape=(None, 1))) model.add(SimpleRNN(units=16, activation='tanh')) model.add(Dense(units=1, activation='sigmoid'))
なお,このモデルの結果ですが,あまり良い結果は得られていません.
実現したいこと(最後に)
- データの特徴をつかむための学習方法として現在実装している
SimpleRNNが適切であるかどうか - 上記で示した現在実装している方法以外でより良いものはないか
よろしくお願いします.
回答1件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2020/11/07 13:01
2020/11/07 13:20
2020/11/09 05:56 編集
2020/11/09 10:19 編集
2020/11/16 02:48