
前提実現したいこと
pythonで外務省のサイトをスクレイピングして
SDGs推進企業の一覧をグーグルスプレッドシートに
「企業名」「企業サイトURL」を取得したいです。
別スレッドにて回答者様が
①スプレッドシートの関数を使用した方法
②Pythonでまとめてupdate_cellsを行う方法
の2点を回答いただきました。
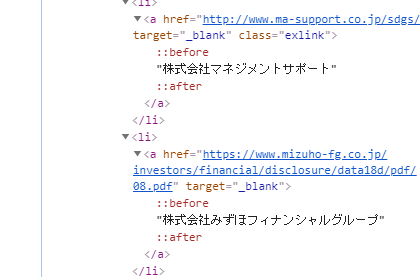
①では全て取得できましたが、②は4件htmlが少し異なるため取得できませんでした。
②では194件全て取得できるようにしたいです。
発生している問題
別スレッドにて収集な回答者様が
①スプレッドシートの関数を使用した方法
②Pythonでまとめてupdate_cellsを行う方法
の2点を回答いただきました。
①では全て取得できましたが、②は4件htmlが少し異なるため取得できませんでした。
②では194件全て取得できるようにしたいです。
#該当のソースコード
import requests
from bs4 import BeautifulSoup
import gspread
from oauth2client.service_account import ServiceAccountCredentials
scope = []
credentials = ServiceAccountCredentials.from_json_keyfile_name('*****', scope)
gs = gspread.authorize(credentials)
wks = gs.open('').sheet1
a = 2
r = requests.get(r"https://www.mofa.go.jp/mofaj/gaiko/oda/sdgs/case/org1.html")
soup = BeautifulSoup(r.content,"html.parser")
data = [[i.get_text(strip=True), i.get("href")] for i in soup.select(".exlink")]
cell_data = sum(data, [])
cell_list = wks.range("C2:D200")
for cell, v in zip(cell_list, cell_data):
cell.value = v
wks.update_cells(cell_list)
#補足
下記の画像のようにhtmlの構成がことなります。
下のhtmlでは上記コードでは取得できません。
回答1件
あなたの回答
tips
プレビュー



2020/01/20 04:43