
ご回答ありがとうございます!
data = """ 〜の部分には【df_event】の全データを打ち込むのでしょうか??
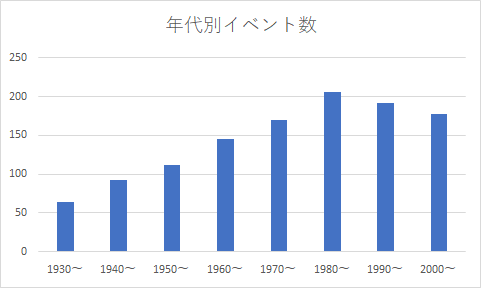
全国のイベント情報をまとめたデータフレーム【df_event】のイベント数を開催年の年代ごとにカウントして棒グラフで可視化したいと考えています。
【df_event】
|イベント名|都道府県名|都道府県ナンバー|費用(万円)|イベント計画(考案)|開催|
|:--|:--:|--:|
|〇〇祭り|北海道|0|780|1983/2/8|1985/4/11
|・|・|・|
|・|・|・|
|〇〇パーティー|東京都|11|428|2003/11/30|2007/1/22
|・|・|・|
|・|・|・|
|〇〇生誕祭|大阪府|26|227|1894/9/17|1896/10/2
|・|・|・|
|・|・|・|
|〇〇イベント|沖縄|46|356|1961/5/7|1963/3/14
何もいい方法が浮かばずつまずいている状態です。。
【イメージ画像】のように出力するのが目的です。。
どなたかご教授よろしくお願いいたします。。
【イメージ画像】
回答2件
あなたの回答
tips
プレビュー



退会済みユーザー
2019/12/22 14:45
2019/12/22 14:54
2019/12/22 15:23 編集
2019/12/22 15:23
退会済みユーザー
2019/12/23 10:05
2019/12/23 10:21
退会済みユーザー
2019/12/23 10:27
2019/12/23 11:41 編集