
ネットワークスパラメーターが同じ状態での報酬のばらつきが大き過ぎます。
ネットパラメータはきちんとリストアできているのに、上記の問題が発生するということはコードに何らかのバグが存在するということになりますが、自分が確認してもどこにバグがあるのかわかりません。
コードは文字制限により一部とはなりますが、よろしくお願いします。
報酬の決定
python
1import numpy as np 2 3def reward2(double trend,list pip,int action,int position,list states,double pip_cost,double spread): 4 cdef list r = [] 5 cdef int sub = 0 6 if position != 3: 7 if action == 0: 8 p = [(trend - s) * pip_cost for s in states] 9 else: 10 p = [(s - trend) * pip_cost for s in states] 11 spread *= -1 12 13 if action == position: 14 sub = 0 15 for b in range(0, len(p)): 16 r = [-40.0, True] if p[b] <= -40 else [p[b], False] 17 if r[1]: 18 pip.append(r[0]) 19 states.pop(b - sub) 20 sub += 1 21 states.append(trend+ spread) 22 position = action 23 else: 24 for b in p: 25 b = -40.0 if b <= -40 else b 26 pip.append(b) 27 states = [trend+ spread] 28 position = action 29 30 else: 31 states = [trend + spread] if action == 0 else [trend - spread] 32 position = action 33 34 return states,pip,position
アクションの決定
python
1def exploration(prediction,output_size,e = 0.2): 2 prediction = prediction.astype("float64") 3 4 if np.random.rand() < e: 5 tau=2.0 6 clip=(-1.0, 1.0) 7 exp_values = np.exp(np.clip(prediction / tau, clip[0], clip[1])) 8 probs = exp_values / np.sum(exp_values) 9 action = np.random.choice(range(output_size), p=probs) 10 else: 11 action = np.argmax(prediction) 12 13 return action
強化学習のトレーニング
python
1 def train(self, iterations, checkpoint, spread, pip_cost, n=4): 2 copy = 0 3 for i in range(iterations): 4 position = 3 5 total_pip = 0.00 6 pip = [] 7 spread = spread / pip_cost 8 done = False 9 states = [] 10 p = [] 11 h_s = [] 12 h_r = [] 13 h_i = [] 14 h_p = [] 15 self.init_value = np.zeros((1, 128)) 16 tau = 0 17 old_reword = 0.0 18 self.history = [] 19 self.best_pip = 0 20 self.MEMORIES = deque() 21 self.pip = [] 22 if (copy + 1) % 2 == 0: 23 self._assign('actor-original', 'actor-target') 24 self._assign('critic-original', 'critic-target') 25 for t in range(0, len(self.trend)-1, self.skip): 26 state = self.get_state(t) 27 h_s.append(state) 28 next_state = self.get_state(t + 1) 29 h_i.append(self.init_value[0]) 30 action = self._select_action(state,next_state) 31 self.history.append(action) 32 h_p.append(self.pred) 33 34 states,pip,position = self.reward(self.trend,t,pip,action,position,states,pip_cost,spread) 35 36 if len(pip) != 0: 37 self.pip = np.asanyarray(pip) 38 total_pip = np.sum(self.pip) 39 mean_pip = total_pip / (t + 1) 40 reward = total_pip - old_reword + self.ri 41 old_reword = total_pip 42 h_r.append(reward) 43 44 tau = t - n + 1 45 if tau >= 0: 46 reward = self.discount_rewards([r for r in h_r[tau+1:tau+n]]) 47 self._memorize(h_s[tau], self.history[tau], reward, next_state,h_p[tau], done, h_i[tau])
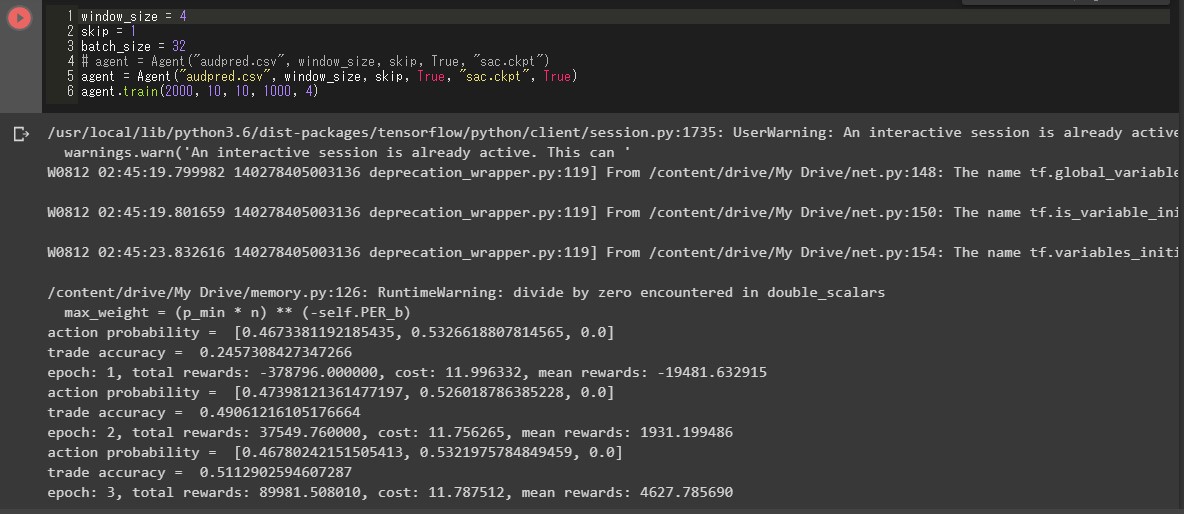


コードを追加します。
python
1 def __init__(self, path, window_size, skip, save=False, saver_path=None, restore=False,sess=None, noise=True,norm=True): 2 self.path = path 3 self.window_size = window_size 4 self._preproc() 5 self.state_size = (None, self.window_size, self.df.shape[-1]) 6 self.skip = skip 7 self.reward = reward 8 self.memory = Memory(self.MEMORY_SIZE) 9 self.mem = Memory 10 # 11 self.ent_coef = ent_coef 12 self.target_entropy = target_entropy 13 self.sess = sess 14 self.actor = Actor('actor-original', self.state_size, self.OUTPUT_SIZE,noise,norm) 15 self.critic = Critic('critic-original', self.state_size, self.OUTPUT_SIZE, self.LEARNING_RATE,noise,norm) 16 self.critic_target = Critic('critic-target', self.state_size, self.OUTPUT_SIZE, self.LEARNING_RATE,noise,norm) 17 self.icm = ICM(self.state_size, self.OUTPUT_SIZE, self.LEARNING_RATE) 18 19 with tf.variable_scope("loss"): 20 if self.target_entropy == 'auto': 21 self.target_entropy = -np.prod(self.OUTPUT_SIZE).astype(np.float32) 22 self.target_entropy = float(self.target_entropy) 23 24 entropy = tf.reduce_mean(self.actor.entropy) 25 26 if isinstance(self.ent_coef, str) and self.ent_coef.startswith('auto'): 27 init_value = 1.0 28 if '_' in self.ent_coef: 29 init_value = float(self.ent_coef.split('_')[1]) 30 assert init_value > 0., "The initial value of ent_coef must be greater than 0" 31 32 self.log_ent_coef = tf.get_variable('log_ent_coef', dtype=tf.float32,initializer=np.log(init_value).astype(np.float32)) 33 self.ent_coef = tf.exp(self.log_ent_coef) 34 else: 35 self.ent_coef = float(self.ent_coef) 36 37 min_qf = tf.minimum(self.critic.qf1, self.critic.qf2) 38 ent_coef_loss, entropy_optimizer = None, None 39 if not isinstance(self.ent_coef, float): 40 ent_coef_loss = -tf.reduce_mean( 41 self.log_ent_coef * tf.stop_gradient(self.actor.log_pi + self.target_entropy)) 42 43 policy_kl_loss = tf.reduce_mean(self.ent_coef * self.actor.log_pi - self.critic.qf1) 44 policy_loss = policy_kl_loss 45 v_backup = tf.stop_gradient(min_qf - self.ent_coef * self.actor.log_pi) 46 value_loss = 0.5 * tf.reduce_mean((self.critic.value_fn - v_backup) ** 2) 47 value_loss += self.critic.td_loss 48 self.policy_loss = policy_loss 49 self.actor_optimizer = tf.train.AdamOptimizer(self.LEARNING_RATE,name="actor_optimizer").minimize(policy_loss,var_list=get_vars("actor-original")) 50 self.vf_optimizer = tf.train.AdamOptimizer(self.LEARNING_RATE,name="actor_optimizer").minimize(value_loss,var_list=get_vars("critic-original")) 51 self.entropy_optimizer = tf.train.AdamOptimizer(learning_rate=self.LEARNING_RATE,name="entropy_optimizer").minimize(ent_coef_loss,var_list=self.log_ent_coef) 52 53 self.save = save 54 self.saver = tf.train.Saver(tf.global_variables()) 55 self.actor_saver = tf.train.Saver(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, "actor-original")) 56 self.saver_path = saver_path 57 58 if restore==True: 59 self.saver.restore(self.sess,self.saver_path) 60 self.actor_saver.restore(self.sess,"actor_sac") 61 else: 62 self.sess.run(tf.global_variables_initializer())
環境の準備
def _preproc(self): df = pd.read_csv(self.path) X = df[["Close"]] X = MinMaxScaler().fit_transform(X) # X = np.asanyarray(X) gen = tf.keras.preprocessing.sequence.TimeseriesGenerator(X, np.asanyarray(df[["Open"]])[-len(X)::], self.window_size) x = [] y = [] for i in gen: x.extend(i[0].tolist()) x = np.asanyarray(x) self.df = x[-self.STEP_SIZE::] self.trend = np.asanyarray(df[["Open"]])[-len(self.df)::]
探査
def _select_action(self, state,next_state=None): prediction, self.init_value = self.sess.run([self.actor.logits,self.actor.last_state], feed_dict={self.actor.X:[state],self.actor.initial_state:self.init_value}) self.pred = prediction action = exploration(prediction[0], self.OUTPUT_SIZE,self.EPSILON) if next_state is not None: self.ri = self.sess.run(self.icm.ri, feed_dict={self.icm.state:[state],self.icm.next_state:[next_state],self.icm.action:action.reshape((-1,1))}) return action
エージェントの評価
def buy(self, spread, pip_cost, sl): position = 3 pip = [] states = [] spread = spread / pip_cost loscut = False self.init_value = np.zeros((1, 512)) for t in range(0, len(self.trend), self.skip): state = self.get_state(t) action = self._select_action(state) states,pip,position = self.reward(self.trend,t,pip,action,position,states,pip_cost,spread) if len(pip) != 0: self.pip = np.asanyarray(pip) total_pip = np.sum(self.pip) # st ate = next_state return total_pip, self.pip



退会済みユーザー
2019/08/17 12:42 編集
2019/08/18 04:56
退会済みユーザー
2019/08/18 05:57