print(df)
#match #set #game #gamewinner #team1 #team2
#1 1 1 1 1 A B
#2 1 1 2 1 A B
#3 1 2 1 2 A B
#4 1 2 2 1 A B
#5 1 2 3 2 A B
#6 1 3 1 1 A B
#7 1 3 2 2 A B
#8 1 3 3 1 A B
#9 1 3 4 1 A B
#10 2 1 1 2 C D
...続く
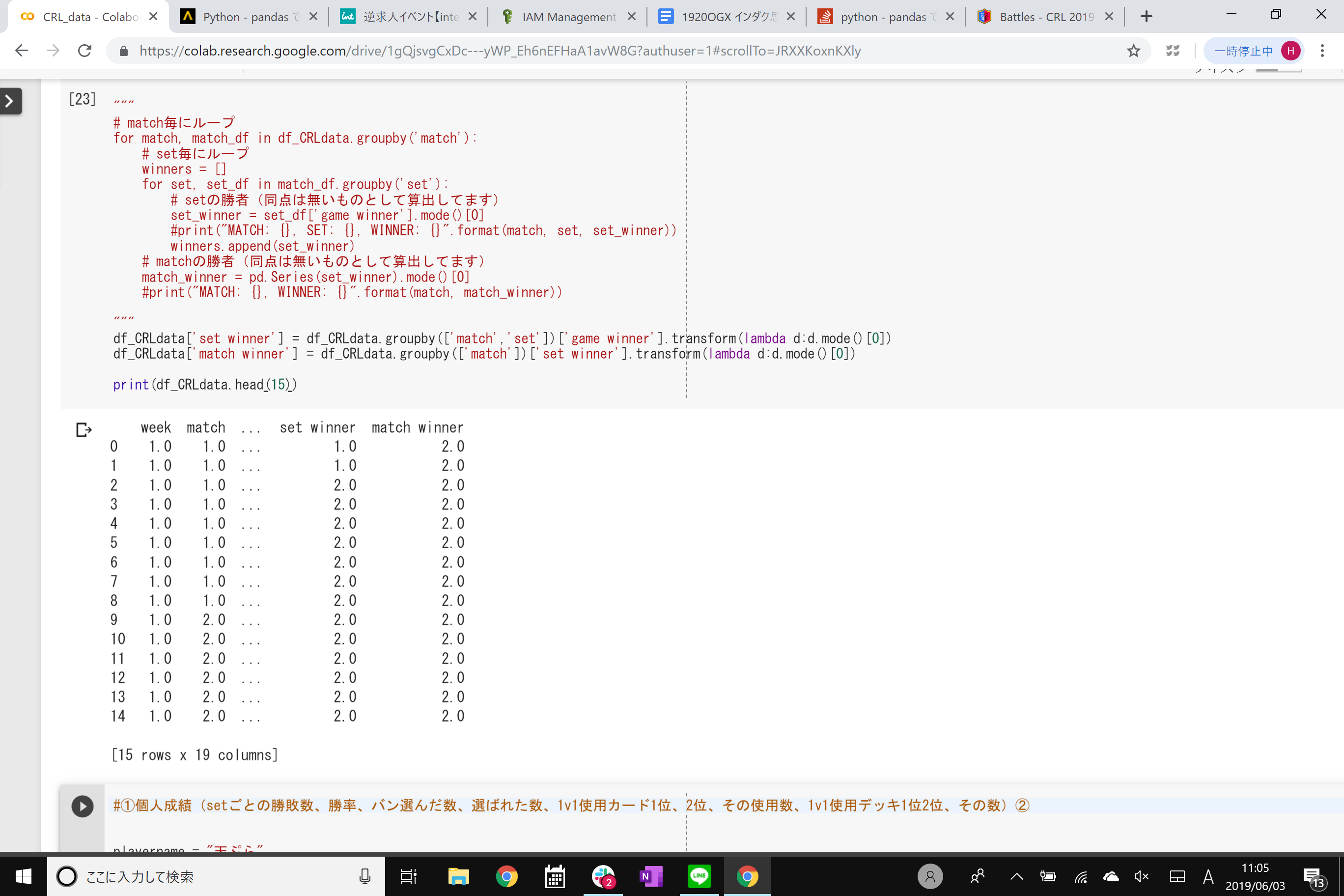
print(df)
#match #set #game #gamewinner #team1 #team2 #setwinner #matchwinner
#1 1 1 1 1 A B 1 1
#2 1 1 2 1 A B 1 1
#3 1 2 1 2 A B 2 1
#4 1 2 2 1 A B 2 1
#5 1 2 3 2 A B 2 1
#6 1 3 1 1 A B 1 1
#7 1 3 2 2 A B 1 1
#8 1 3 3 1 A B 1 1
#9 1 3 4 1 A B 1 1
#10 2 1 1 2 C D 2 1
1import pandas as pd
2import io
34csv ="""
5match,set,game,gamewinner,team1,team2
61,1,1,1,A,B
71,1,2,1,A,B
81,2,1,2,A,B
91,2,2,1,A,B
101,2,3,2,A,B
111,3,1,1,A,B
121,3,2,2,A,B
131,3,3,1,A,B
141,3,4,1,A,B
152,1,1,2,B,C
162,1,2,2,B,C
172,2,1,1,B,C
182,2,2,2,B,C
192,2,3,2,B,C
202,3,1,1,B,C
212,3,2,2,B,C
222,3,3,1,B,C
232,3,4,2,B,C
242,3,5,2,B,C
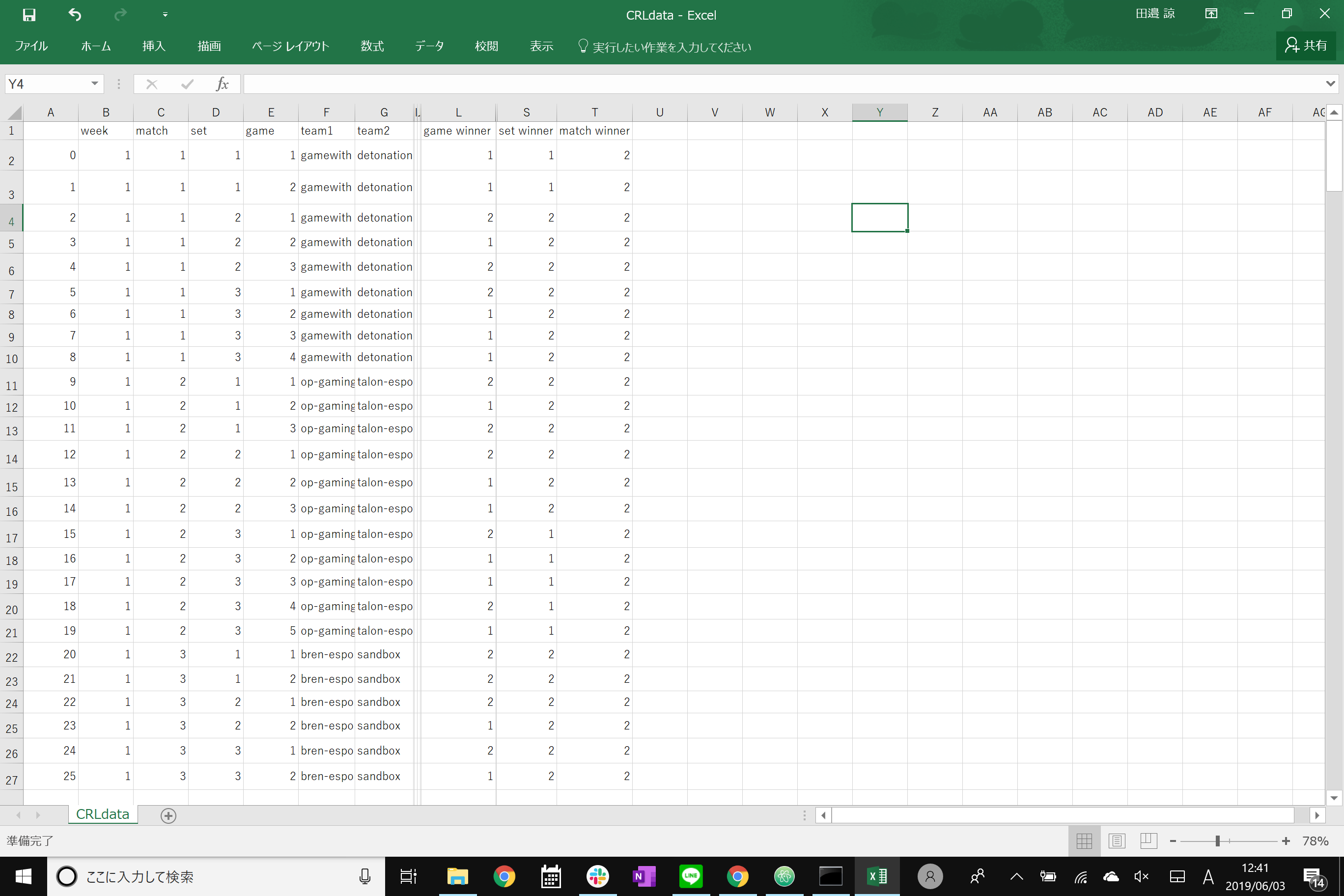
25"""2627df = pd.read_csv(io.StringIO(csv))2829df['setwinner']= df.groupby(['match','set'])['gamewinner'].transform(lambda d:d.mode()[0])30df['matchwinner']= df.groupby(['match'])['setwinner'].transform(lambda d:d.mode()[0])31print(df)32# match set game gamewinner team1 team2 setwinner matchwinner33#0 1 1 1 1 A B 1 134#1 1 1 2 1 A B 1 135#2 1 2 1 2 A B 2 136#3 1 2 2 1 A B 2 137#4 1 2 3 2 A B 2 138#5 1 3 1 1 A B 1 139#6 1 3 2 2 A B 1 140#7 1 3 3 1 A B 1 141#8 1 3 4 1 A B 1 142#9 2 1 1 2 B C 2 243#10 2 1 2 2 B C 2 244#11 2 2 1 1 B C 2 245#12 2 2 2 2 B C 2 246#13 2 2 3 2 B C 2 247#14 2 3 1 1 B C 2 248#15 2 3 2 2 B C 2 249#16 2 3 3 1 B C 2 250#17 2 3 4 2 B C 2 251#18 2 3 5 2 B C 2 2
print(df)
for i in range(1,11):
#すでに終了したマッチの分しか正確に記入できないので注意
#セット勝利の記入
df.loc[(df["#match"]==df.at['#'+str(i),'#match'])&(df["#set"]==df.at['#'+str(i),'#set']),"#setwinner"] = df.at['#'+str(i),'#gamewinner']
#マッチ勝利の記入
df.loc[(df["#match"]==df.at['#'+str(i),'#match']),"#matchwinner"] = df.at['#'+str(i),'#setwinner']
print(df)
import pandas as pd
df=pd.read_excel('excel1.xlsx')
print(df)
for i in range(1,11):
#セット勝利数リセット
if df.at['#'+str(i),'#set']==1:
print('match start')
times_won_set_team1=0
times_won_set_team2=0
#ゲーム勝利数リセット
if df.at['#'+str(i),'#game']==1:
print('set start')
times_won_game_team1=0
times_won_game_team2=0
#ゲーム勝利数カウント
if df.at['#'+str(i),'#gamewinner']==1:
print('team1 won')
times_won_game_team1+=1
print('team1:'+str(times_won_game_team1))
else:
print('team2 won')
times_won_game_team2+=1
print('team2:'+str(times_won_game_team2))
#セット勝利数カウント、セット勝利の記入
#第1、第2セットの場合
if times_won_game_team1==2 and df.at['#'+str(i),'#set']<=2:
print('team1 set won')
times_won_set_team1+=1
df.at['#'+str(i),'#setwinner']=1
elif times_won_game_team2==2 and df.at['#'+str(i),'#set']<=2:
print('team2 set won')
times_won_set_team2+=1
df.at['#'+str(i),'#setwinner']=2
#第3セットの場合
elif times_won_game_team1==3 and df.at['#'+str(i),'#set']==3:
print('team1 set won')
times_won_set_team1+=1
df.at['#'+str(i),'#setwinner']=1
elif times_won_game_team2==3 and df.at['#'+str(i),'#set']==3:
print('team2 set won')
times_won_set_team2+=1
df.at['#'+str(i-1),'#setwinner']=2
#マッチ勝利の記入
if times_won_set_team1==2:
print('team1 match won')
df.at['#'+str(i),'#matchwinner']=1
elif times_won_set_team2==2:
print('team2 match won')
df.at['#'+str(i),'#matchwinner']=2
print(df)




2019/06/03 02:08
2019/06/03 02:32
2019/06/03 03:46
2019/06/03 04:47
2019/06/03 06:04