
SatoshiMashinoさま、おはようございます:)
ありがとうございます(*≧∀≦) おかげさまで動きました!
これでロシア文学をロシア語で読むのを簡単にするコードが進められます!
ちなみに、キリル文字はutf-8だと文字化けしたので、utf-8-sigを使いました^^/
ロシア語でドストエフスキーの『26人の男と1人の少女』という小説を読んでみようと思っています。しかし如何せん単語力がないため、まず一つ一つの単語を.csvファイルに書き込んで、それに対応する日本語をつける予定です。
そのための第一歩、「split()した単語をcsvファイルに書き込む」という段階で躓いています。
ちなみに『26人の男と1人の少女』は、現れた1人のかわいらしい少女に夢も希望もない26人の男が好意を抱き、彼女の前では言動を慎み、女神に対する態度もかくやと思われるほど彼女をみんなで敬い大切にしていたが、その幻想がもろくも崩れ去り男達は夢も希望もない精神状態に逆戻り、という内容です。
ロマン・ガリの『天国の根』の逆バージョンとも言えます。
実行環境
- Python 3.6.5
- Windows7
- Jupyter notebook
実現したいこと
.txtの内容を1単語ずつ.csvファイルに書き込みたい。なんとかcsvファイルに書き込めるまで改善できましたが、なぜか最初の5単語しかcsvファイルに書き込まれていません。
すべての単語をcsvファイルに書き込めるようにしたいです。
成功イメージ

.txtの内容
Нас было двадцать шесть человек — двадцать шесть живых машин, запертых в сыром подвале,...(略)
.txtファイル内容のsplit()はできた
コード
python
1f = open('26and1.txt', 'r', encoding = 'utf-8') 2for line in f: 3 print(line.split())
実行結果
['\ufeffНас', 'было', 'двадцать', 'шесть', 'человек', '—', 'двадцать', ...(略)]
上記でsplit()した単語をcsvファイルに書き込みたい
私が考えたコード (なぜかリスト0-4しかcsvに書き込まれない)
python
1import csv 2f = open('26and1.txt', 'r', encoding = 'utf-8-sig') 3 4with open('26and1.csv', 'w') as file: 5 for line in f: 6 # print(line) 7 data = line.split() 8 # print(data[0:2]) 9 for n in range(0, 103): 10 writer = csv.writer(file, lineterminator = '\n') 11 writer.writerow([data[n]])
出力結果
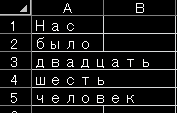
現状
- 単語数は103個あるはずなのに0~4までしかcsvファイルに書き込まれていない。
よろしくお願いしますorz
できましたー!
キリル文字はutf-8だと文字化けするので、utf-8-sigを使用。
python
1import csv 2f = open('26and1.txt', 'r', encoding = 'utf-8-sig') 3 4with open('26and1.csv', 'w', encoding = 'utf-8-sig') as file: 5 for line in f: 6 data = line.split() 7 for n in range(0, len(data)): 8 writer = csv.writer(file, lineterminator = '\n') 9 writer.writerow([data[n]])
回答2件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2018/09/18 22:10
2018/09/18 22:38
2018/09/18 22:48
2018/09/18 22:52
2018/09/18 23:54