



他のサイトとは?同じデータを使っているんですか?
kerasを用いたRNNのプログラミングを勉強しております。
RNNを用いて乗客数のグラフの予測をしているサイトがありましたので、それをkerasで行なってみたいと思って以下のプログラムを作ってみております。predictが全く予測していなく、困っております。
以下RNN学習のために試しておりますプログラムです。
python
1 2df = pd.read_csv('international-airline-passengers.csv',skipfooter=3) 3 4data=np.array(data) 5 6sabun_data=[] 7for i in range(len(data)-1): 8 temp_sabun=data[i+1]-data[i] 9 sabun_data.append(temp_sabun) 10sabun_data=np.array(sabun_data) 11data=sabun_data 12#data.shapeは(143)です。 13 14#sinwaveを予測するプログラミングを参考にしてます。 15 16#5個ずつのデータサイズごとにX,yを作成する。 17X_data=[] 18target=[] 19 20manabu_len=5 21for i in range(0,len(data)-manabu_len): 22 X_data.append(data[i:i+manabu_len]) 23 target.append(data[i+manabu_len]) 24 25from sklearn.model_selection import train_test_split 26X=np.array(X_data).reshape(len(X_data),manabu_len,1) 27y=np.array(target).reshape(len(X_data),1) 28(train_X,test_X,train_y,test_y)=train_test_split(X,y,test_size=0.2) 29 30from keras.layers import LSTM,SimpleRNN 31from keras.models import Sequential 32from keras.optimizers import Adam 33from keras.layers import Dense,Activation 34 35n_in=1 36n_hidden=20 37n_out=1 38model=Sequential() 39model.add(LSTM(n_hidden,input_shape=(manabu_len,n_in),kernel_initializer="random_normal")) 40model.add(Dense(n_out)) 41model.add(Activation("linear")) 42model.compile(loss="mean_squared_error",optimizer="Adam") 43model.fit(X,y,batch_size=20,epochs=100,validation_data=(test_X,test_y)) 44 45 46#modelを参考にして、predictをグラフ化してみる。 47 48#予測したデータをpredictに格納してグラフにしてみる。 49in_=X[:1] 50predicted=[] 51for i in range(len(data)-manabu_len): 52 out_=model.predict(in_) 53 in_ = np.vstack( (in_.reshape(manabu_len,n_in)[1:], out_)).reshape(1, manabu_len, n_in) 54 predicted.append(out_.reshape(-1)) 55plt.plot(data, label="original") 56plt.plot(predicted, label="predicted") 57plt.legend() 58plt.show() 59コード

他のサイトでは、同じdata数でtensorflow,tflearnでグラフに近似したpredictを出せているみたいなのですが、自分のプログラミングの問題がどこにあるのかわからないでおります。SimpleRNNなどもためしてみましたが同じ状況でした。
RNNについて初心者ですが、アドバイスをいただけますと幸いです。よろしくお願いいたします。
==========================================================
追記
アドバイスをいただきまして差分データから特徴量と教師データにすることで予測できるようになってきました.
ありがとうございます。
#差分データ予想
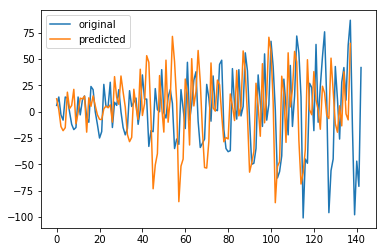
差分データから得られた元データと予測の比較

ただ、手法によるためか精度には課題が多いようです。進むにつれてかなりずれていきました。
精度を上げられるようにするにはどうすべきか、いろいろ調べてみます。
ボストンの乗客数というデータを使用させていただき、RNNについて勉強しております。https://datamarket.com/data/set/22u3/international-airline-passengers-monthly-totals-in-thousands-jan-49-dec-60#!ds=22u3&display=line
追記ですが、yを設定する際に使用しているinput_lenの数値を大きくしても同じようになってしまっています。
回答2件
あなたの回答
tips
プレビュー


