



実現したいこと
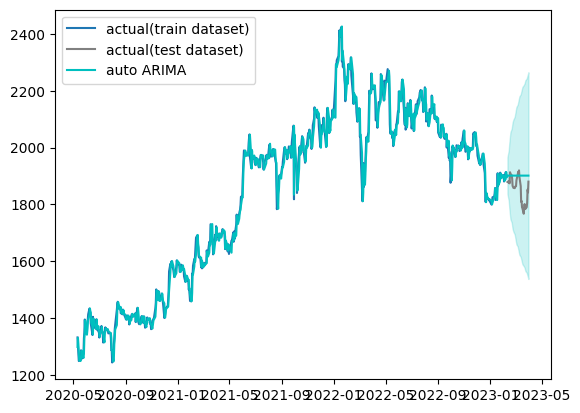
表示される予測期間のグラフがほぼ平坦になってしまいます。
推定された値(auto ARIMA)を見てみましたが、ほぼ数値が変わらない状態になっています。
こういう結果になるのが普通か、あるいは修正する方法があるのかを教えていただきたいです
前提
Google ColabにおいてPythonコードを使って推定を進めています。
該当のソースコード
Python
1# ライブラリのインポート 2!pip install pmdarima 3import pandas as pd 4import numpy as np 5from scipy import signal 6from statsmodels.tsa.seasonal import seasonal_decompose 7from statsmodels.tsa.seasonal import STL 8from statsmodels.tsa.stattools import adfuller 9from statsmodels.graphics.tsaplots import plot_acf, plot_pacf 10import matplotlib.pyplot as plt 11import pmdarima as pm 12from pmdarima import utils 13from pmdarima import arima 14from pmdarima import model_selection 15from statsmodels.tsa.statespace.sarimax import SARIMAX 16from sklearn.metrics import mean_squared_error 17from sklearn.metrics import mean_absolute_error 18from sklearn.metrics import mean_absolute_percentage_error 19 20 21 22 23TOYOTA_stock_Source = pd.read_csv("/content/drive/MyDrive/7203トヨタ自動車株価.csv", index_col=['日付'], parse_dates=True) 24 25# 終値の抽出 26TOYOTA_stock = TOYOTA_stock_Source['終値'] 27# データの前処理 28TOYOTA_stock = TOYOTA_stock_Source['終値'].str.replace(',', '').astype(float) 29#欠損値の置換 30TOYOTA_stock_imp_pd = TOYOTA_stock.fillna(TOYOTA_stock.mean()) 31 32plt.plot(TOYOTA_stock_imp_pd) 33 34dfr = TOYOTA_stock_imp_pd.pct_change(1).dropna() 35 36# 対数変換後、階差をとったものにADF検定 37dftest = adfuller(np.diff(np.log(TOYOTA_stock_imp_pd))) 38print('ADF Statistic: %f' % dftest[0]) 39print('p-value: %f' % dftest[1]) 40 41dftest = adfuller(np.diff(np.log(TOYOTA_stock_imp_pd),n=2)) 42print('ADF Statistic: %f' % dftest[0]) #検定統計量を表示させる 43print('p-value: %f' % dftest[1]) 44print('Critical values :') 45for k, v in dftest[4].items(): #1%,5%,10%信頼区間を表示させている 46 print('\t', k, v) 47 48# 対数化後、階差数列化後、季節階差を除いたものにADF検定 49dftest = adfuller(pd.DataFrame(np.diff(np.log(TOYOTA_stock_imp_pd))).diff(12).dropna()) 50print('p-value: %f' % dftest[1]) 51 52# 原系列 53plot_acf(TOYOTA_stock_imp_pd, lags=20) 54plot_pacf(TOYOTA_stock_imp_pd, lags=20) 55 56# 対数化後、階差数列化後、季節階差を除いたもの 57syori_dt = pd.DataFrame(np.diff(np.log(TOYOTA_stock_imp_pd))).diff(12).dropna() 58acf = plot_acf(syori_dt, lags=20) 59pacf = plot_pacf(syori_dt, lags=20) 60 61# データ分割(train:学習データ、test:テストデータ) 62train, test = model_selection.train_test_split(TOYOTA_stock_imp_pd, train_size=700) 63 64arima_model = pm.auto_arima(train, 65 seasonal=True, 66 m = 12, 67 trace=True, 68 n_jobs=-1, 69 maxiter=10) 70 71# 予測 72##学習データの期間の予測値 73train_pred = arima_model.predict_in_sample() 74##テストデータの期間の予測値 75test_pred, test_pred_ci = arima_model.predict( 76 n_periods=test.shape[0], 77 return_conf_int=True 78) 79 80print(test_pred) 81 82# テストデータで精度検証 83print('RMSE:') 84print(np.sqrt(mean_squared_error(test, test_pred))) 85print('MAE:') 86print(mean_absolute_error(test, test_pred)) 87print('MAPE:') 88print(mean_absolute_percentage_error(test, test_pred)) 89 90# グラフ化 91fig, ax = plt.subplots() 92ax.plot(train[24:].index, train[24:].values, label="actual(train dataset)") 93ax.plot(test.index, test.values, label="actual(test dataset)", color="gray") 94ax.plot(train[24:].index, train_pred[24:], color="c") 95ax.plot(test.index, test_pred, label="auto ARIMA", color="c") 96ax.fill_between( 97 test.index, 98 test_pred_ci[:, 0], 99 test_pred_ci[:, 1], 100 color='c', 101 alpha=.2) 102ax.legend()
試したこと
データの欠損を埋める方法などを変えてみましたが大きく値が変動しませんでした。
補足情報(FW/ツールのバージョンなど)
csvファイルのリンクです。
トヨタ株価
初心者ゆえ抽象的な質問をして申し訳ありません。よろしくお願いします。
あなたの回答
tips
プレビュー


