
実現したいこと
Self-Attentionから得られた重みであるAttention Weightを正しく出力したい
前提
Self-Attentionから得られた重みであるAttention Weightを正しく出力したい。
入力は動画データをI3Dに適用した特徴マップの0次元目にバッチサイズ30を設定したもの(30, 64, 1024)で、1次元目はフレーム数、2次元目は次元の大きさです。
正常映像と異常映像を同時入力するため、フレーム数の次元はtorch.catで結合しています。
検証時は正常と異常を別で入力するのでtorch.catで結合していません。
Attention Weightは検証時のみ、呼び出してヒートマップで保存するように設定してます。
Self-Attentionのネットワークは下記記載URLのVideoClassifierクラスから持ってきました。
https://github.com/yaegasikk/attention_anomaly_detector/blob/main/network/video_classifier.py
未だに原因が判明していない状況です。
発生している問題・エラーメッセージ
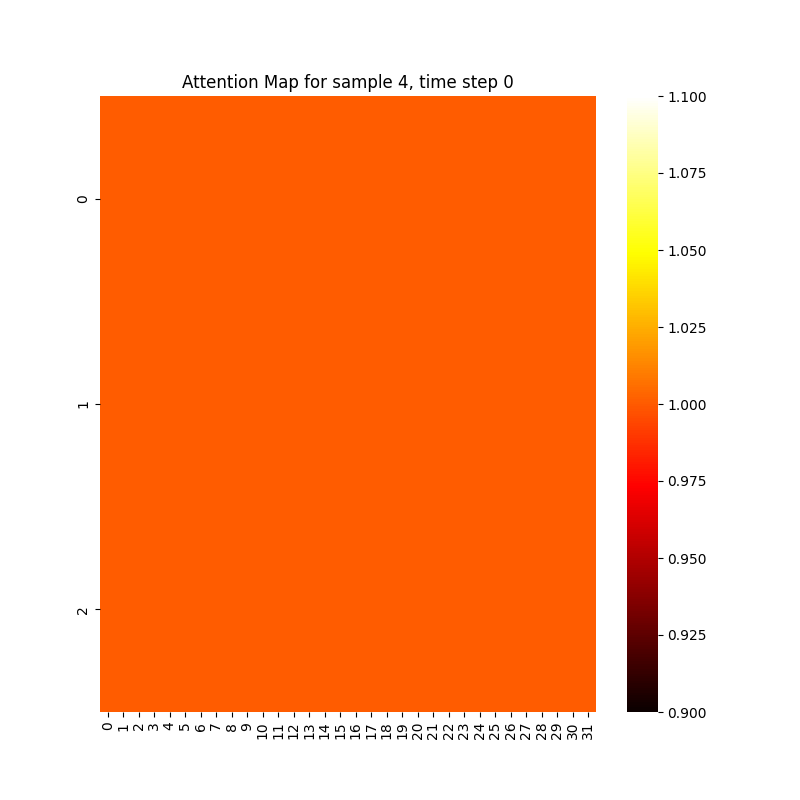
問題としては、AUCは高く(0.81)、Loss(0.27)も下がっているのにも関わらず、Attention Weightのヒートマップが全て同じ値になっていることです。
検証データは290あるのですが、全て添付画像のようになってしまいます。
各フレームで動きが無い箇所ほど値が低く(黒く)動きがある箇所ほど値が高く(白く)なるのを期待していました。
該当のソースコード
main.py
1from torch.utils.data import DataLoader 2from learner import Learner 3from loss import * 4# from dataset import * 5from dataset import * 6import os 7from sklearn import metrics 8from radam import RAdam 9import argparse 10from FFC import * 11import matplotlib.pyplot as plt 12import seaborn as sns 13import numpy as np 14from torchinfo import summary 15import time 16from radam import RAdam 17 18parser = argparse.ArgumentParser(description='PyTorch MIL Training') 19parser.add_argument('--lr', default=0.001, type=float, help='learning rate') 20parser.add_argument('--w', default=0.0010000000474974513, type=float, help='weight_decay') 21parser.add_argument('--modality', default='RGB', type=str, help='modality') 22parser.add_argument('--input_dim', default=1024, type=int, help='input_dim') 23parser.add_argument('--drop', default=0.3, type=float, help='dropout_rate') 24parser.add_argument('--FFC', '-r', action='store_true',help='FFC') 25parser.add_argument('--seed',default=9111,type=int,help='random seed') 26args = parser.parse_args() 27 28 29best_auc = 0 30 31normal_train_dataset = Normal_Loader(is_train=1, modality=args.modality) 32normal_test_dataset = Normal_Loader(is_train=0, modality=args.modality) 33 34anomaly_train_dataset = Anomaly_Loader(is_train=1, modality=args.modality) 35anomaly_test_dataset = Anomaly_Loader(is_train=0, modality=args.modality) 36 37normal_train_loader = DataLoader(normal_train_dataset, batch_size=30, shuffle=False) 38normal_test_loader = DataLoader(normal_test_dataset, batch_size=1, shuffle=True) 39 40anomaly_train_loader = DataLoader(anomaly_train_dataset, batch_size=30, shuffle=False) 41anomaly_test_loader = DataLoader(anomaly_test_dataset, batch_size=1, shuffle=True) 42 43device = 'cuda' if torch.cuda.is_available() else 'cpu' 44 45if args.FFC: 46 model = Learner(input_dim=args.input_dim, dropout=args.drop).to(device) 47else: 48 model = Learner(input_dim=args.input_dim, dropout=args.drop).to(device) 49 50optimizer = RAdam(model.parameters()) 51scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[25, 50]) 52criterion = MIL 53# train_loss_history = [] 54seed = args.seed 55torch.manual_seed(seed) 56np.random.seed(seed) 57# torch.cuda.synchronize() 58 59def train(epoch): 60 print('\nEpoch: %d' % epoch) 61 model.train() 62 train_loss = 0 63 correct = 0 64 total = 0 65 torch.cuda.synchronize() 66 67 for batch_idx, (normal_inputs, anomaly_inputs) in enumerate(zip(normal_train_loader, anomaly_train_loader)): 68 inputs = torch.cat([anomaly_inputs, normal_inputs], dim=1) 69 # print(inputs.shape) 70 batch_size = inputs.shape[0] 71 inputs = inputs.view(-1, inputs.size(-2), inputs.size(-1)).to(device) 72 # inputs = inputs.view(-1, inputs.size(-1)).to(device) 73 # print(inputs.shape) 74 # print(inputs.shape) 75 outputs, attention_weights = model(inputs) 76 # print(outputs.shape) 77 loss = criterion(outputs, batch_size) 78 optimizer.zero_grad() 79 loss.backward() 80 optimizer.step() 81 train_loss += loss.item() 82 # torch.cuda.synchronize() 83 # train_loss_history.append(train_loss/len(normal_train_loader)) 84 print('loss = ', train_loss/len(normal_train_loader)) 85 scheduler.step() 86 87 88def test_abnormal(epoch): 89 model.eval() 90 global best_auc 91 auc = 0 92 # all_fpr = np.linspace(0, 1, 150) 93 # mean_tpr = 0 94 # torch.cuda.synchronize() 95 # fpr_tpr_file_path = f'fpr_tpr_epoch_{epoch}.txt' 96 # fpr_tpr_file = open(fpr_tpr_file_path, 'w') 97 98 with torch.no_grad(): 99 for i, (data, data2) in enumerate(zip(anomaly_test_loader, normal_test_loader)): 100 inputs, gts, frames = data 101 inputs = inputs.view(-1, inputs.size(-2), inputs.size(-1)).to(torch.device('cuda')) 102 # inputs = inputs.view(-1, inputs.size(-1)).to(torch.device('cuda')) 103 # print(inputs.shape) 104 105 score, attention_weights = model(inputs) #予測スコアのみ計測 106 107 # print(score.shape) 108 score = score.view(-1, score.size(-1)) #SA-MILの時は必要 109 # print(score.shape) 110 score = score.cpu().detach().numpy() 111 score_list = np.zeros(frames[0]) 112 step = np.round(np.linspace(0, frames[0]//16, 33)) 113 114 for j in range(32): 115 score_list[int(step[j])*16:(int(step[j+1]))*16] = score[j] 116 if epoch == 1: 117 for j in range(len(attention_weights)): 118 attention_map = attention_weights[j].cpu().detach().numpy() # Convert to numpy 119 attention_map = attention_map.transpose() 120 plt.figure(figsize=(8, 8)) 121 sns.heatmap(attention_map, cmap="hot", annot=False) 122 plt.title(f"Attention Map for sample {i}, time step {j}") 123 plt.savefig(f'attention_map_sample_{i}_time_{j}.png') 124 plt.close() 125 126 gt_list = np.zeros(frames[0]) 127 for k in range(len(gts)//2): 128 s = gts[k*2] 129 e = min(gts[k*2+1], frames) 130 gt_list[s-1:e] = 1 131 # print(gt_list) 132 133 inputs2, gts2, frames2 = data2 134 inputs2 = inputs2.view(-1, inputs2.size(-2), inputs2.size(-1)).to(torch.device('cuda')) 135 # inputs2 = inputs2.view(-1, inputs2.size(-1)).to(torch.device('cuda')) 136 score2, attention_weights = model(inputs2) 137 score2 = score2.view(-1, score2.size(-1)) 138 score2 = score2.cpu().detach().numpy() 139 score_list2 = np.zeros(frames2[0]) 140 step2 = np.round(np.linspace(0, frames2[0]//16, 33)) 141 142 for kk in range(32): 143 score_list2[int(step2[kk])*16:(int(step2[kk+1]))*16] = score2[kk] 144 145 gt_list2 = np.zeros(frames2[0]) 146 score_list3 = np.concatenate((score_list, score_list2), axis=0) 147 gt_list3 = np.concatenate((gt_list, gt_list2), axis=0) 148 149 fpr, tpr, thresholds = metrics.roc_curve(gt_list3, score_list3, pos_label=1) 150 auc += metrics.auc(fpr, tpr) 151 print('auc = ',auc/140) 152 153 if best_auc < auc/140: 154 print('Saving..') 155 torch.save(model.state_dict(), './checkpoint/SA-MIL-da1.pth') 156 best_auc = auc/140 157 158for epoch in range(0, 20): 159 train(epoch) 160 test_abnormal(epoch) 161 162 163print("Best AUC:", best_auc) 164# plot_loss(train_loss_history, save_path='Loss.png') 165# summary(model)
learner.py
1import torch 2import torch.nn as nn 3import numpy as np 4import torch.nn.functional as F 5import matplotlib.pyplot as plt 6import os 7import seaborn as sns 8 9class Learner(nn.Module): 10 def __init__(self, input_dim = 1024, dropout = 0.0, attention=True): 11 super().__init__() 12 self.self_attention = nn.Sequential(nn.Linear(input_dim,64),nn.Tanh(),nn.Linear(64,3)) 13 self.fc1 = nn.Linear(input_dim*3,32) 14 self.fc2 = nn.Linear(32,1) 15 self.dropout = nn.Dropout(dropout) 16 self.sig = nn.Sigmoid() 17 self.return_attention = attention 18 self.attention_map_index = 0 19 20 def forward(self,x): 21 bs,t,f = x.shape 22 scores = [] 23 attention_weights = [] 24 25 for i in range(t): 26 attention_weight = self.dropout(F.softmax(self.self_attention(x[:, i, :].unsqueeze(1)), dim=1)) 27 attention_weights.append(attention_weight.view(bs, -1)) 28 # print(attention_weight.shape) 29 m = torch.bmm(x[:, i, :].unsqueeze(1).permute(0, 2, 1), attention_weight) 30 # print(m.shape) 31 x_part = m.view(bs, -1) 32 # print(x_part.shape) 33 x_part = self.fc1(x_part) 34 x_part = self.fc2(x_part) 35 x_part = self.sig(x_part) 36 # print(x_part.shape) 37 scores.append(x_part) 38 39 scores = torch.stack(scores, dim=1) 40 attention_weights = torch.stack(attention_weights, dim=1) 41 # print(scores) 42 # print(scores.shape) 43 print(attention_weights.shape) 44 45 if self.return_attention: 46 return scores, attention_weights 47 else: 48 return scores
試したこと
AUCとLossが問題ないので、原因が全く分からない状況です。
あなたの回答
tips
プレビュー


