
前提
Pythonでサイトのスクレイピングをしようとしています。
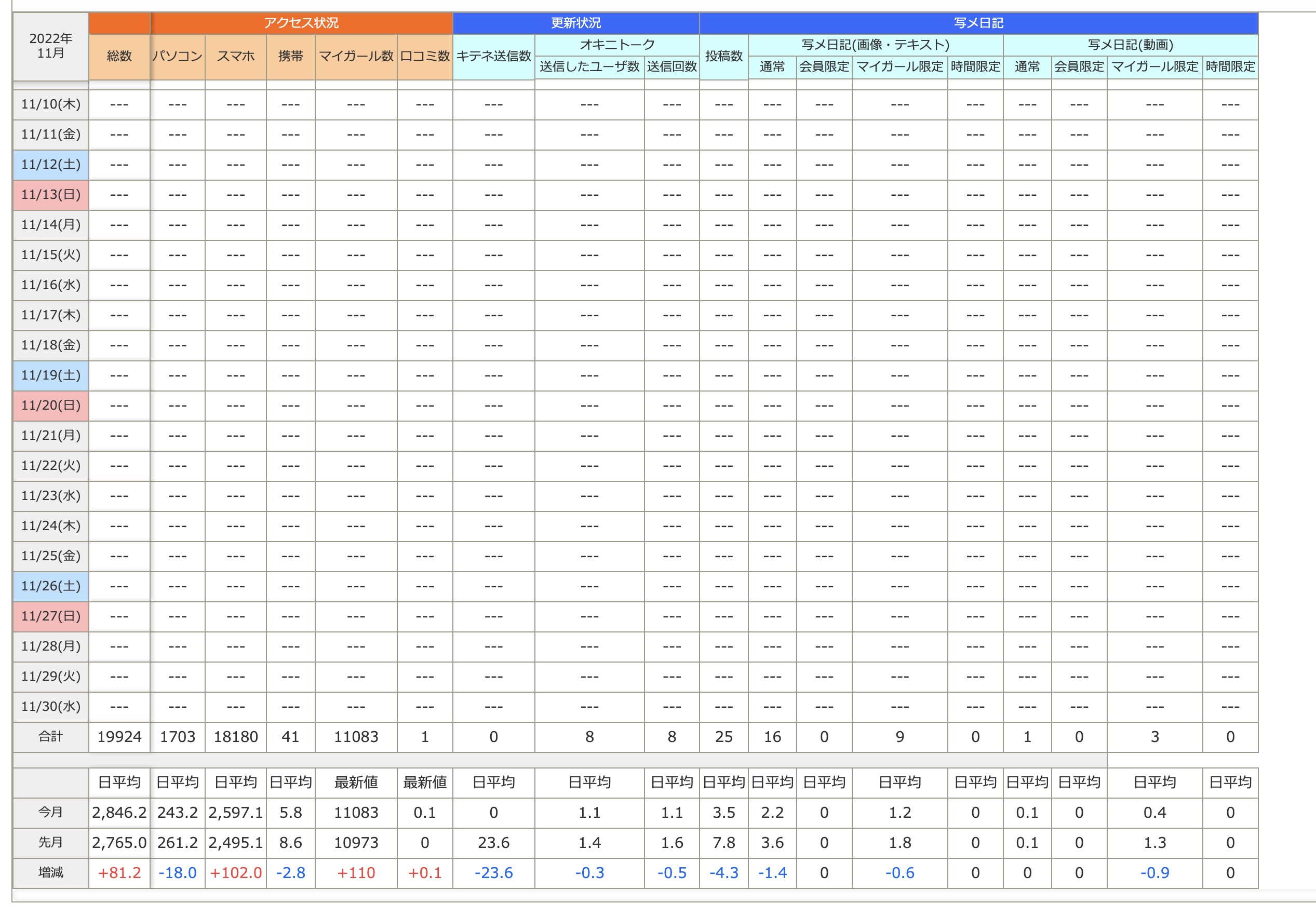
「合計」の行を1つずつ取り出したく、以下コードを書きました。
該当のソースコード
Python
1driver.get(url) 2 html2 = driver.page_source.encode('utf-8') 3 soup2 = BeautifulSoup(html2,'lxml') 4 data = soup2.find("th",text="合計").find_next("td").text 5 data2 = soup2.find("td",text=data).find_next("td").text 6 data3 = soup2.find("td",text=data2).find_next("td").text 7 data4 = soup2.find("td",text=data3).find_next("td").text 8 data5 = soup2.find("td",text=data4).find_next("td").text 9 data6 = soup2.find("td",text=data5).find_next("td").text 10 data7 = soup2.find("td",text=data6).find_next("td").text 11 data8 = soup2.find("td",text=data7).find_next("td").text 12 data9 = soup2.find("td",text=data8).find_next("td").text 13 data10 = soup2.find("td",text=data9).find_next("td").text 14 data11 = soup2.find("td",text=data10).find_next("td").text 15 data12 = soup2.find("td",text=data11).find_next("td").text 16 data13 = soup2.find("td",text=data12).find_next("td").text 17 data14 = soup2.find("td",text=data13).find_next("td").text 18 data15 = soup2.find("td",text=data14).find_next("td").text 19 data16 = soup2.find("td",text=data15).find_next("td").text 20 data17 = soup2.find("td",text=data16).find_next("td").text 21 data18 = soup2.find("td",text=data17).find_next("td").text 22 print("総アクセス数 ") 23 print(data) 24 print("パソコン ") 25 print(data2) 26 print("スマホ ") 27 print(data3) 28 print("携帯 ") 29 print(data4) 30 print("マイガール数 ") 31 print(data5) 32 print("口コミ数 ") 33 print(data6) 34 print("キテネ送信数 ") 35 print(data7) 36 print("オキニトーク 送信したユーザー数 ") 37 print(data8) 38 print("オキニトーク 送信回数 ") 39 print(data9) 40 print("写メ日記(画像・テキスト) 投稿数 ") 41 print(data10) 42 print("写メ日記(画像・テキスト) 通常 ") 43 print(data11) 44 print("写メ日記(画像・テキスト) 会員限定 ") 45 print(data12) 46 print("写メ日記(画像・テキスト) マイガール限定 ") 47 print(data13) 48 print("写メ日記(画像・テキスト) 時間限定 ") 49 print(data14) 50 print("写メ日記(動画) 通常") 51 print(data15) 52 print("写メ日記(動画) 会員限定 ") 53 print(data16) 54 print("写メ日記(動画) マイガール限定 ") 55 print(data17) 56 print("写メ日記(動画) 時間限定 ") 57 print(data18)
実行結果

5番目までは正確に取れる(ページによって取れなかったりする)のですが、
それ以降は全然違う数値が出てきます。
取り方が悪いのだと思いますが、初心者ゆえどうすればいいか分かりません。
ご教示いただけますでしょうか?
回答1件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2022/11/10 01:18