

「となるような処理をしたいです。」で挙げられているデータは、カラム毎にデータ数が違うので、dfとして成立しませんが、どのようなデータが得たいのでしょうか。
実現したいこと
- 列ごとの初めと終わりに並ぶ欠損値を削除したい
該当のソースコード
python
1df = pd.DataFrame(np.arange(35).reshape(7, 5), 2 columns=['col_0', 'col_1', 'col_2', 'col_3', 'col_4'], 3 index=['row_0', 'row_1', 'row_2', 'row_3', 'row_4','row_5','row_6']) 4 5df = df.replace([0,2,3,4,5,7,9,10,13,19,27,28,29,31,32,33], np.nan)
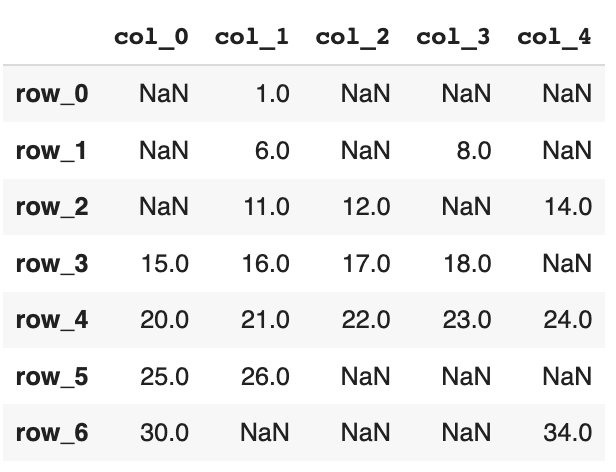
以上のようなデータの際に,
python
1 col_0: 15、20、25、30 2 col_1: 1、6、11、16、21、26 3 col_2: 12、17、22 4 col_3: 8、NaN、 18、23 5 col_4: 14,NaN,24,NaN,34
となるような処理をしたいです。
この処理はdf全体に対する処理ではなく、指定した列のみにする処理になります。
試したこと
欠損値処理について調べてみましたが、欠損値を全て削除するものしか見つけることができませんでした。
補足情報(FW/ツールのバージョンなど)
ここにより詳細な情報を記載してください。
質問いただきありがとうございます。
挙げたのはデータではなくて、カラム毎に抽出したときに得たい値になります。
何らかの関数(df['col_0'])としたときに得られた値です。
回答1件
あなたの回答
tips
プレビュー


