えと、まずリンクを貼っておきます。
私の説明の10000000倍役に立つと思います。
#全結合層
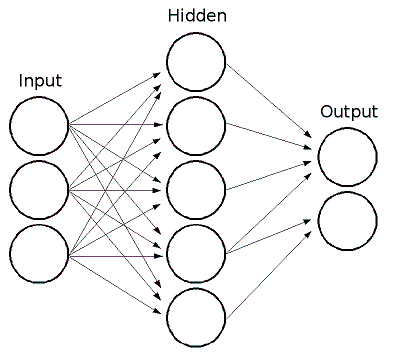
ディープラーニングの基幹、ニューラルネットワーク(NN)の基本形です。
特徴ベクトルを入力とし、出力は目的によって様々です。
分類問題に用いるときは、出力層の一つ一つのノードの値は、そのクラスに属する尤度と解釈することが多いです。
出力を適当に決めてよいのか...? と思うかもしれませんが、どんなシステムでも学習できるのがNNの最大の強みです。
もちろん、決め方によって性能に差は出ますが。
さて、肝心の演算については、実はかなり簡単な計算をしています。
まず、大前提として、ノードもリンクも、一つ一つ実数値を持っています。

このとき、i4は次のように計算されます。
i4 = n1*w1 + n2*w2 + n3*w3 これが、隠れ層のノードの一つへの入力になります。
それでは出力は何かと言いますと、n4 = f(i1+b1)となります。
ここで、fは活性化関数と呼んでいるもので、ネットワークで非線形の演算を表現できるようにするものです。
ReLUもその一種で、他にもシグモイド関数などが用いられることがあります。
それでは、結局ニューラルネットワークの学習とはなんなのか...?
NNも入力に対して出力が一定に決まるという意味では一種のファンクションです。
その振る舞いはパラメータ、ここでは重みwとバイアスbで決まります。
重みとバイアスを正しくチューニングすることが、まさにNNの学習であるといえます。
#隠れ層
図では英語でHidden Layerと書かれていますね。
ディープラーニングは、層の多い、つまり隠れ層の多いNNを用いた学習を指します。
さて、なぜ最近ディープラーニングがホットなのか...?
「隠れ層が多いことで、人間の抽象的な思考や概念を表現できるためだ」と言われています。
実は学問的な裏付けはあまりありません。人工知能は科学ですから、帰納的に学問が発展しています。
#特徴ベクトル
さて、ニューラルネットワークの説明で特徴ベクトルという言葉を用いました。
特徴ベクトルは、文字通り特徴を並べた配列で、その形態はさまざまです。
画像を用いた問題の場合、どのような特徴を抽出してくるか、が大きなテーマになっています。
昔は、エッジやコーナーを演算して抽出するようなシステムを用い、特徴ベクトルを作っていました。
#畳込みニューラルネットワーク(CNN)
昔は?では今はどうしているのか?そう感じるのは正しいです。
今は、畳込み層を用いたニューラルネットワークを用いるのが基本です。
畳込み層を用いることによって、エッジやコーナー、濃淡などを抽出します。
畳込み層も重みを持っています。演算自体は、普通の画像フィルタリングと同じです。
畳込みNNが従来のNNと違うのは、特徴の抽出も学習することです。
いろいろ資料を見ていると、畳込み層がエッジなどを強調したものが見つかると思います。
これは、畳込み層がよりよい特徴を抽出するように学習されたからです。
機械が自発的に特徴を見つけるというのは、まさに抽象的な思考を取得していると言えませんか?
#プーリング
お調べになっている通り、画像を圧縮する層です。
この層は、演算を高速化する他に、細かい位置の変換に強くなる(頑健である)と言えます。
例えば人間が写真を見たとき、写っているものの位置に着目するでしょうか?
写真のどの位置に写っていようが、人間は人間であり、犬は犬です。
その点では、必要な位置情報は絶対位置ではなく、相対位置であると言えます。
プーリング層を噛ませることによって、細かな位置の違いが無視され、性能が上がると言われているのです。
ここらの話はこちらが参考になります。
#ようやく質問に答えると
長くなってしまってすみません。
それぞれの層のイメージ
役割としては、次のような感じでしょうか。
- 畳込み層... 特徴を抽出する。
- プーリング層... こまかな位置を意図的に無視することで、頑健性を高める。
- 全結合層... NNの心臓部。得られた特徴ベクトルを基に分類問題を解く。
畳込みの演算と出力について
畳込み層の演算自体は、一般のフィルタリング処理と同一です。フィルタの出力が次の層に伝わります。
ReLU関数の役割について
直接的な役割は、先ほども言ったように、ネットワークの表現力を高めることです。
畳込み層によって、確かにエッジなどの画像が得られますが... あくまで学習の結果です。
プーリング層の役割について
画像を圧縮するという認識は正しいです。しかし、「何かが写っている部分」だけを選んでいるわけではありません。
イメージで言うと、モザイク処理ですかね。画像全体を圧縮します。





バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2017/06/22 15:23 編集
2017/06/22 15:37
2017/06/25 06:39
2017/06/25 07:03
2017/06/25 11:08 編集
2017/06/25 08:19
2017/06/25 11:07 編集
2017/06/25 08:36 編集
2017/06/25 11:08 編集
2017/06/25 09:08 編集
2017/06/25 09:11