

ご回答ありがとうございます。
誠に、丁寧にご説明頂いているにも関わらず申し訳ないのですが、何故左側の図では「x軸」が「0.1」、「0.2」と少数である場合に、「y軸」が整数であり、右側の図では「x軸」が整数であると、「y軸」が少数になるのかが分からないです...
「Jupiter notebook」にて、分布図の確認を行っていたのですが、確率密度?の見方が分からなかったため、質問させてもらいました。
以下はデータの一覧(5つのレコードまで)です。

そして、分布図が以下となります。

こちらのヒストグラムの見方ですが、横軸がデータ(値)であるとの認識でおります。
その場合、「0.3 ~ 0.4」の範囲で、縦軸の数値「1」が対応しているかと思うのですが、この「1」は何を示しているのでしょうか...?
縦軸は確率密度らしいのですが、いまいち確率密度というのが分からなかった為、どなたかアドバイス頂けますと幸いです。
よろしくお願いします。
追記です
ご回答による頂いたコードをjupyter notebookに記載し、実行してみました。
気になる質問をクリップする
クリップした質問は、後からいつでもMYページで確認できます。
またクリップした質問に回答があった際、通知やメールを受け取ることができます。
バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
回答2件
0
![]() ベストアンサー
ベストアンサー
グラフの見方について
青のバーと青の折れ線は分けて考えてください。
- 青のバー: データから作成したヒストグラムです。
- 青の折れ線: データの母集団分布をカーネル密度推定 (kernel density estimation, KDE) という手法で推定した確率密度関数を描画したものです。
seaborn.distplot の kde=True (デフォルト) の場合に、ヒストグラムの他にこのグラフが描画されます。
実装上は statsmodels がインストールされている場合は statsmodels.nonparametric.kde.KDEUnivariate、そうでない場合は scipy.stats.gaussian_kde に処理を投げるようになっています。
確率密度関数について
連続型の確率変数 X があるとき、X がある値 a 以下をとる確率を P(X <= a) としたとき、

で定義される f(x) が確率密度関数です。
※ 確率変数 = とり得る値が確率によって決まる変数。例えば、X をサイコロの目としたとき、X = 1 (1の目) は、1/ 6 の確率で出る。
注意したいのは、f(c) の値は、X = c となる確率ではありません。
X = c となる確率 P(X = c) は定義に従って計算すると、0 になります。
確率密度関数の見方としては、確率密度関数 f(x) の値が大きいところは、そのあたりの x の値が現れる可能性が高いという理解でいいと思います。
体系的に理解したい場合は 統計学 の教科書を当たると、最初のほうで必ず紹介されていると思うので、それを参照してください。
追記
ストーリーとしては、以下のようになります。
いくつかのデータが得られた
↓
データが得られた背景となる確率分布があるけど、それはわからない
↓
データから確率分布を推定する
統計学の考え方としては、まずなんらかの真の確率分布があり (現実ではこれはわからない)、データはその確率分布から得られた標本 (値の例) であると考えます。
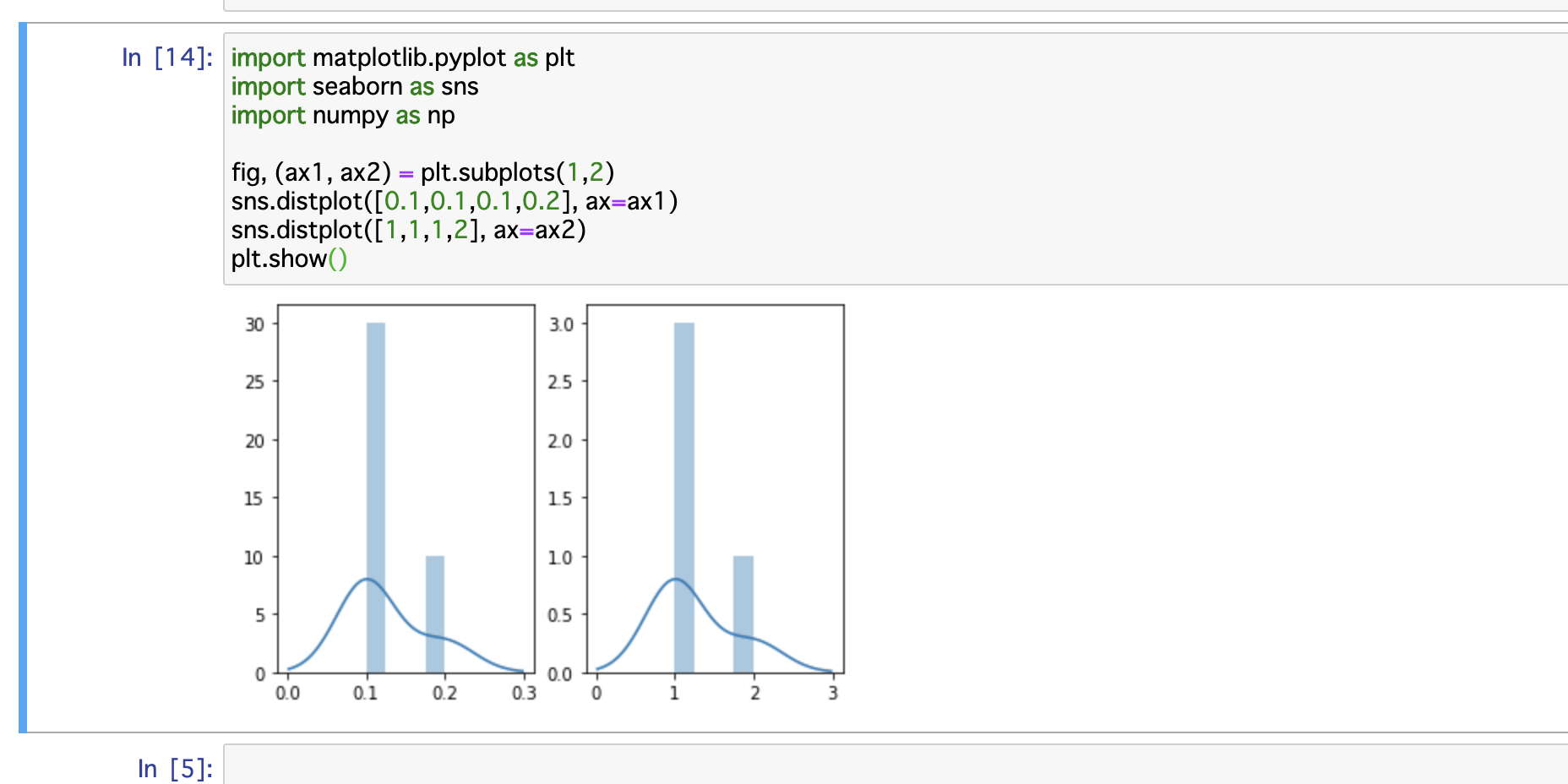
以下、例として、標準正規分布としておきます。
python
1from scipy.stats import norm, gaussian_kde 2import numpy as np 3import matplotlib.pyplot as plt 4 5# 平均0、分散1の1変量正規分布に従う確率変数 6rv = norm(loc=0, scale=1) 7 8fig, ax = plt.subplots() 9ax.plot(xs, rv.pdf(xs), label="確率密度関数") 10ax.legend(loc="upper left") 11ax.set_xlim(-5, 5) 12plt.show()
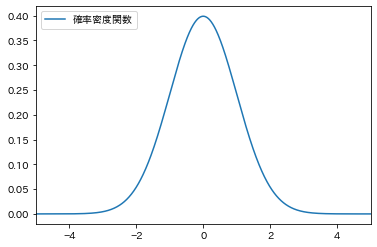
このような分布があって、そこから1000 個の値が得られたとします。
ヒストグラムを描画すると以下のようになります。
現実では、いくつかのデータが得られたとして、真の確率分布というのはわからないわけです。
例えば、100人に身長を聞いて、[168, 172, 180, ...] と100人分のデータが得られたとして、その元となった真の確率分布というのはわかりません。
わからないので、それを今持っているデータから推定するというのが、統計学の1つの目的になります。
カーネル密度推定はその手法の1つです。
カーネル密度推定を使って推定すると、以下のようになります。
元の分布 (青) がわからなくても、データからある程度それに近い分布 (オレンジ) が得られました。
python
1# この得られた標本から元となる確率密度関数を推定する。 2kernel = gaussian_kde(samples) 3 4# 確率密度関数を描画する。 5xs = np.linspace(-5, 5, 1000) 6 7fig, ax = plt.subplots() 8ax.plot(xs, rv.pdf(xs), label="確率密度関数") 9ax.plot(xs, kernel(xs), label="推定した確率密度関数") 10ax.legend(loc="upper left") 11ax.set_xlim(-5, 5) 12plt.show()

追記
2つのグラフで「y」の値が、一方は少数、一方は整数となっておりますが、これは何故かがわかりません。
グラフの目盛りがすべて整数なら整数、小数が含まれるなら小数で表示するという matplotlib の仕様によるものなので、整数か小数かはグラフの表示上の問題であり、重要ではありません。
注目するべきは、y 軸のスケールが左と右で大きく違うことでしょう。
これは、他の回答者様のコメント欄で hayataka2049 さんがご指摘されていますが、ヒストグラムの正規化 (デフォルトで有効) によるものです。
通常、ヒストグラムは y 軸は各ビンに属するデータ数 (頻度値) ですが、この正規化が有効の場合、棒の面積の合計が1となるように棒の高さが調整されます。
数式で表すと、n 個のビンの幅が w1, w2, ..., wn、頻度値が f1, f2, ..., fn としたとき、
w1 * f1 + w2 * f2 + ... + wn + fn = 1
となるように f1, f2, ..., fn の値を正規化します。
左のほうが右より棒の高さが高いのは、左の方はビンの幅が小さいので、棒の面積の合計が1にするためには棒の高さをその分高くする必要があるからです。
棒の高さをそのビンに属するデータ数として解釈したい場合は distplot() で norm_hist=False を指定してください。
この正規化の仕様は、内部でヒストグラム作成に使用している numpy.histogram から来ています。
また、can110さんのご回答で、「描かれた曲線とx軸とを囲む領域の面積がデータ値の出現個数の総数になるように補正、正規化された値だということのようです。」とあるのですが、
仮に左側の画像の総面積を求めてみますと、x軸が「0.0 ~ 0.3」の為、「0.3」y軸を大体ではありますが「6」と考えた場合、「0.3 × 6 ÷ 2」 = 「0.9」となります。
こちらのデータ値の出現個数の総数が「0.9」であるという意味がいまいち分からない為、ご助言頂けましたら幸いです...
曲線のほうは、先の回答の通り、推定した確率密度関数です。
「描かれた曲線とx軸とを囲む領域の面積」とは、確率密度関数を (-∞, +∞) の区間で積分すると求められ、これは1になります。

この計算の解釈は、確率変数 X は実数の値をとるので、(-∞, +∞) の間の値をとる確率は100%であるということを言っています。
補足
正規化されたヒストグラム、カーネル密度推定で推定した確率密度関数ですが、どちらも(不明な)真の確率密度関数を近似するのが目的です。
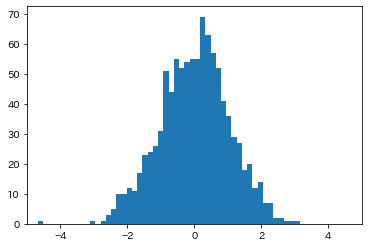
曲線とx軸の間の面積を求めるのに、x 軸を細かい区間で分割して、長方形を敷き詰めて、面積を計算するというのが、リーマン積分の考え方です。
なので、大量のデータを用意して、ビンの幅を小さくした正規化されたヒストグラムを作成すれば、それで真の確率密度関数を近似できます。
リーマン積分の考え方
python
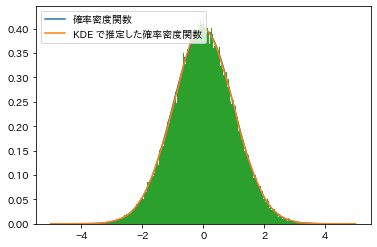
1from scipy.stats import norm, gaussian_kde 2import numpy as np 3import matplotlib.pyplot as plt 4 5# 平均0、分散1の1変量正規分布に従う確率変数 6rv = norm(loc=0, scale=1) 7 8# 大量の標本を生成する。 9samples = rv.rvs(300000) 10 11# この得られた標本から元となる確率密度関数を推定する。 12kernel = gaussian_kde(samples) 13 14fig, ax = plt.subplots() 15 16# 確率密度関数を描画する。 17xs = np.linspace(-5, 5, 1000) 18ax.plot(xs, rv.pdf(xs), label="確率密度関数") 19ax.plot(xs, kernel(xs), label="KDE で推定した確率密度関数") 20 21# ヒストグラムを描画する。 22bins = np.linspace(-5, 5, 1000) 23ax.hist(samples, bins, density=True) 24ax.legend(loc="upper left") 25plt.show()
「カーネル密度推定の確率密度関数 (オレンジ)」は「真の確率密度関数」と一致して重なっている。
「正規化されたヒストグラム(緑)」も「真の確率密度関数」とほぼ一致している。
追記 distplot の仕様確認
引数の優先度としては、norm_hist < kde < hist_kws のようですので、
正規化したくない場合は、kde=False または hist_kws={"density": False} を指定するのがよさそうです。
| kde | density | ヒストグラム |
|---|---|---|
| False | False | 正規化されない |
| False | True | 正規化される |
| True | False | 正規化されない |
| True | True | 正規化される |
python
1import matplotlib.pyplot as plt 2import numpy as np 3import seaborn as sns 4 5sns.set() 6np.random.seed(0) 7 8x = np.random.randn(1000) 9 10fig, axes = plt.subplots(2, 2, figsize=(8, 8)) 11axes = axes.ravel() 12 13axes[0].set_title("kde=False, density=False") 14sns.distplot(x, kde=False, hist_kws={"density": False}, ax=axes[0]) 15axes[1].set_title("kde=False, density=True") 16sns.distplot(x, kde=False, hist_kws={"density": True}, ax=axes[1]) 17axes[2].set_title("kde=True, density=False") 18sns.distplot(x, kde=True, hist_kws={"density": False}, ax=axes[2]) 19axes[3].set_title("kde=True, density=True") 20sns.distplot(x, kde=True, hist_kws={"density": True}, ax=axes[3]) 21plt.show()

| kde | norm_hist | ヒストグラム |
|---|---|---|
| False | False | 正規化されない |
| False | True | 正規化される |
| True | False | 正規化される |
| True | True | 正規化される |
import matplotlib.pyplot as plt import numpy as np import seaborn as sns sns.set() np.random.seed(0) x = np.random.randn(1000) fig, axes = plt.subplots(2, 2, figsize=(8, 8)) axes = axes.ravel() axes[0].set_title("kde=False, norm_hist=False") sns.distplot(x, kde=False, norm_hist=False, ax=axes[0]) axes[1].set_title("kde=False, norm_hist=True") sns.distplot(x, kde=False, norm_hist=True, ax=axes[1]) axes[2].set_title("kde=True, norm_hist=False") sns.distplot(x, kde=True, norm_hist=False, ax=axes[2]) axes[3].set_title("kde=True, norm_hist=True") sns.distplot(x, kde=True, norm_hist=True, ax=axes[3]) plt.show()

投稿2020/02/09 10:54
編集2020/02/11 07:19総合スコア21956
0
What is y axis in seaborn distplot?にてほぼそのままの質問と回答がありましたので、まずは一読ください。
正直「確率密度」とは何かなどがいまいちほぼほぼ理解できていないのですが、Prasann Barotさんの回答をgoogle翻訳した結果を引用します。
ANS->密度プロットのy軸は、カーネル密度推定の確率密度関数です。ただし、これは確率ではなく確率密度であると指定するように注意する必要があります。違いは、確率密度とは、x軸上の単位あたりの確率です。実際の確率に変換するには、x軸上の特定の間隔の曲線の下の領域を見つける必要があります。やや紛らわしいことに、これは確率ではなく確率密度であるため、y軸は1より大きい値を取ることができます。
つまりy軸は確率密度を示す値ですが、描かれた曲線とx軸とを囲む領域の面積がデータ値の出現個数の総数になるように補正、正規化された値だということのようです。
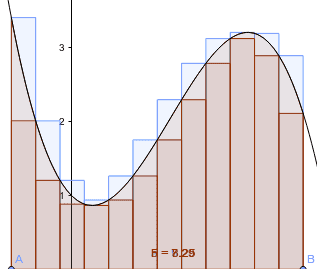
これは以下のようなコードにて簡単な図を描くことで確かめられます。
以下の図において右側はx値が左側の10倍であるためy軸の値は1/10になっています。
またざっと目視で曲線とx軸で囲まれた領域の面積を求めてみます。
どちらも約1.25となり、実際の出現個数の総数4と、少し離れた値になっていますが、これは推定の仕方、distplotでデフォルトで使用している確率密度関数の性質に起因するものです。
python
1import matplotlib.pyplot as plt 2import seaborn as sns 3import numpy as np 4 5print(sns.__version__) # 0.9.0 6 7fig, (ax1, ax2) = plt.subplots(1,2) 8sns.distplot([0.1,0.1,0.1,0.2], ax=ax1) 9sns.distplot([1,1,1,2], ax=ax2) 10plt.show()

曲線の意味
この図の曲線(確率密度関数)を用いると、与えられたデータ群以外のデータ値の出現確率(個数)を推定することができます。
たとえば左側の図においてx=0.075というデータ値の出現確率(個数)は以下によって求めることができます。
今x値から上に直線を伸ばして曲線とそれに交わった点のy軸の値を見ます。この場合は約10になります。
これにx=0.075を掛けて0.75個という値がx=0.075の出現確率(個数)となります。
ただ、直感的にはもう少し大きな値になるのが自然そうで、あまり当てにならない感じもします。
ということでPrasann Barotさんの回答の続き
密度プロットの唯一の要件は、曲線下の総面積が1つに統合されることです。私は一般に、密度プロットのy軸を、異なるカテゴリ間の相対的な比較の値としてのみ考える傾向があります。
という回答になっているのかと思います。
投稿2020/02/08 12:41
編集2020/02/09 05:07総合スコア38266
バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
![]()
「y軸」は一体何を表しているのかといったことが、ピンとこない状態でございます...
>またざっと目視で縦軸と横軸の値を掛算して、曲線下の面積が1であることが分かります
こちらですが、仮に左側の図であった場合、具体的な数値としては、x軸、y軸どの部分を掛け合わせましたら、答えが導きだせますでしょうか...?
先に確認なのですが「積分」という考え、この場合は曲線とx軸とを囲む範囲の面積の求め方は理解できますでしょうか?
いえ、積分、面積の求め方共に分からないといった状態です...
そうですね…右側の図で説明します。
求めたい領域をx軸の0~1,1~2,2~3の三つの部分に分けます。
左側と右側はざっくり幅1高さ0.5の三角形なので面積は0.25+0.25=0.5
真ん中は幅1高さ0.5の長方形なので面積は0.5.合わせて1になります。
左側の図の領域も同じように求めると1になると分かるかと思います。
横(x)軸の値は、ご理解されているようにデータ(値)を表しています。
縦(y)軸の値は、いま求めた領域の面積が1となるように補正(正規化)された(確率の)値ということになります。
ご丁寧にご解説頂きましてありがとうございます。
おかげで、面積の求め方を理解することが出来ました。
すみません...後一点お聞きしたいことがあるのですが、「縦(y)軸の値は、いま求めた領域の面積が1となるように補正(正規化)された(確率の)値ということになります。」こちらの「補正された確率の値」というのがいまいち分からないのですが、これが分かったことで、データの何が分かるのでしょうか...?
いまいち、どうもピンとこず...度々のご質問で申し訳ないです...
> これが分かったことで、データの何が分かるのでしょうか...?
回答に追記しました。この曲線(関数)によって、元のデータ群以外の値の出現確率を推定することができます。
あれれ?出現確率というより出現回数かな?
回答に書いている面積=確率=1という部分、こちらが勘違いしているかも。
ちょっと考えなおして回答の修正を試みてみます。
ということで、サンプルデータを見直して全面的に回答を修正しました。
面積=データの出現確率というより出現総数(データの個数の総数)のようです。よって曲線から推定される値も確率(%)ではなく個数のようです。
面積の求め方については変わりはありません。
追記ありがとうございます。
自分も、can110さんがご回答に記載くださいましたコードを、jupyter notebookにて、実行させてみました。その結果は質問本文にて、追記させて頂きました。
そして、自分の環境で実行し出た結果とcan110さんのご回答を照らし合わせてみました。
>今x値から上に直線を伸ばして曲線とそれに交わった点のy軸の値を見ます
まずこちらなのですが、左側の図では「x」の値が「0.1」の時、曲線と交わる位置はおよそ「y軸」が「8」辺りであるかと思います。
そのため「8」を「x」の値、0.1に掛け合わせ、「0.8」といった結果が得られるかと思います。
そうなった場合、「0.1」がデータ全体に含まれている確率はおよそ「0.8」である、といった理解で合っておりますでしょうか...?
このことから、自分の推測ではあるのですが、can110さんの編集前のご回答で「1 = 100%」であるとあったのですが、これは全データのおよそ「80%」程「0.1」が含まれているといった意味になってくるのではないかと思っております...
もし、間違いな部分などございましたら、お手数をかけ申し訳ないのですが、ご指摘頂けましたら幸いです...
あ...しかし、コメントで「1 = 100%」というのは否定されていますよね...
となりますと、全体が「1」である内の「0.8」個程含まれているということですかね...?
まず、修正した回答に図が抜けていました。すみません。
次に図を追加したのですが、結果が異なりますね…
ということで、seabornのバージョンを確認ください。こちらは「0.9.0」です。
私の回答はこの回答の図を基にしており、面積は確率(=1)ではなく個数(=4)と解釈しています。
よって左側の図でx=0.1であればy=20なので0.1*20=2個となります。実際(正解)は3個ですが。
2020/02/09 06:18 編集
> これにx=0.075を掛けて0.75個という値がx=0.075の出現確率(個数)となります。
いや、例えば x = 0.075~0.076 (Δx=0.001)の範囲が出現する確率が
確率密度関数がこの範囲であまり変化しないと近似して大体10なので
10*0.001 = 0.01 = 1%
という意味では
ヒストグラムについてはkde=Falseにして確率密度分布を非表示にするとすると2つのデータでどちらも縦軸が同じ(0.1/1が3、0.2/2が1)になるので、確率密度分布の見た目に合うようにスケーリングしているのではないかと思います。
自分の環境では、seabornは「0.10.0」でした。ご指摘の通り、バージョンの違いによるものかもしれません...
can110さんにご提示頂きました左側の図では、曲線下の総面積は、x軸が「0.05 ~ 0.15」までで0.1なので、0.1×20 ÷2 = 「1」であり、「0.15 ~ 0.25」までで「0.1」y軸はおよそ「6」なので、0.1×6÷2 = 「0.3」このことから、総面積は「0.4」になるのではないでしょうか...?
>、面積は確率(=1)ではなく個数(=4)と解釈しています。
こちらなのですが、何故「4」になるかが分からなくて...
もし、お願いできましたら、計算方法など教えて頂けましたら幸いです...
> ~左側の図では、曲線下の総面積は、x軸が「0.05 ~ 0.15」までで0.1
>なので、0.1×20 ÷2 = 「1」であり、「0.15 ~ 0.25」までで「0.1」y軸はおよそ「6」なので、>0.1×6÷2 = 「0.3」このことから、総面積は「0.4」になるのではないでしょうか...?
x=0.1, y=20 を頂点とし幅(0.15-0.05)=0.1である三角形Aの面積=0.1*20/2=1
x=0.2, y= 5 を頂点とし幅(0.25-0.15)=0.1である三角形Bの面積=0.1*5/2=0.25
面積を足して1.25を得ました。また三角形Bの高さを6とみなすと1.3を得ます。
以上、少し少なめに見積もった面積が確率「1」よりも明らかに大きそうなので個数「4」と推測しました。
ただ、そもそも前提となる曲線がaae_11さんの結果とは異なるため、混乱しております…
ご返信ありがとうございます。
理解が悪く申し訳ありません...
>以上、少し少なめに見積もった面積が確率「1」よりも明らかに大きそうなので個数「4」と推測しました。
こちらなのですが、何故面積が、「1」以上である場合に、データの個数(数)は「4」になるのでしょうか...?
そもそも面積が「1」であるということは、何を表しているのかといった部分が分からない状況です...
ozwkさん、コメント&ご指摘ありがとうございます。
ご指摘のとおり、ある一点0.075としてではなく、0.075~0.076 (Δx=0.001)という範囲の面積という計算が正しいですね。
ただ、そもそもの確率分布関数(曲線)がsnsのバージョン違いのためかがaae_11と異なっており
kde=True時のy軸の値の根拠、具体的にどのような計算で求めているのか推測でも分からず混乱しておりますが…
こちらの図、および個数という解釈が誤りであるように思えてきました。
(ちゃんと理論およびseabornの実装を理解すれば解決するはずですが、アタマが追いつきません)
2020/02/10 01:56 編集
愉快なことに、distplotのbins引数を変えるとy軸のスケールは比例するかのように増加します。y軸の値を読むと、ヒストグラムの方はbinsに比例して値が大きくなります(グラフ上は同じ位置にあるように見える)。PDFの方はbinsに比例して値が大きくなったりはしません(グラフ上は潰れていくように見えます)。
import seaborn as sns
import matplotlib.pyplot as plt
bins_lst = [5, 10, 20, 40, 80]
fig, axes = plt.subplots(ncols=5)
for b, ax in zip(bins_lst, axes):
sns.distplot([0.1, 0.1, 0.1, 0.2], bins=b, ax=ax)
plt.show()
この挙動がどこから来ているのかと言うと、実はmatplotlibのhistのdensityパラメータをTrueにしていることに由来します。
seaborn側のコードはこの辺です。
https://github.com/mwaskom/seaborn/blob/master/seaborn/distributions.py#L219
matplotlibはこちらを見てください。
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.hist.html
> density : bool, optional
> If True, the first element of the return tuple will be the counts normalized to form a probability density, i.e., the area (or integral) under the histogram will sum to 1. This is achieved by dividing the count by the number of observations times the bin width and not dividing by the total number of observations.
こんなのも実行してみるとわかりやすいかもしれません。
import numpy as np
import matplotlib.pyplot as plt
scales = list(range(5))
fig, axes = plt.subplots(ncols=5)
for s, ax in zip(scales, axes):
ax.hist(np.array([0.1, 0.1, 0.2, 0.2])*10**s, density=True)
plt.show()
直感的には値の区間が広くなればそれだけ「近い値は稀になる」ので、こういう仕様も理にかなっているのかもしれません。個人的にはかなり違和感がありますが。
hist_kws={"density":False}とするとヒストグラムの方は観測度数がそのまま出てきます。PDFの方もできればなんとかしたいんですが、すぐに見つからなかったので提示できません。左右にy軸のあるグラフにして右は度数、左はPDFの値に対応づけられたらいいんですが、seabornがやってくれないので、そういうのがほしかったら自分で書くべきかもしれません。
コメント&ソースリンクもありがとうございます。
デフォルト動作(kdeがTrue)だとnorm_histもTrueになるんですね。
たしかにPDFとヒストグラムを重ねて表示するにはこちらのほうが自然なのでしょう。
ただx軸(データ値)のスケールにしたがいy軸のスケールが変わってくるという動きは
distplotの動きを知らすに&とりあえず結果から推論する私には、かなり混乱させるものでした(笑
そもそもPDFとヒストグラムを重ねて表示させることに、ちょっと無理がある(PDFだけでいいじゃん)ような気がします。
> 左右にy軸のあるグラフにして右は度数、左はPDFの値に対応づけられたらいいんですが
同感です。
あなたの回答
tips
太字
斜体
打ち消し線
見出し
引用テキストの挿入
コードの挿入
リンクの挿入
リストの挿入
番号リストの挿入
表の挿入
水平線の挿入
プレビュー
質問の解決につながる回答をしましょう。 サンプルコードなど、より具体的な説明があると質問者の理解の助けになります。 また、読む側のことを考えた、分かりやすい文章を心がけましょう。



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
2020/02/09 11:29 編集
2020/02/09 12:22 編集
2020/02/09 13:36 編集
2020/02/09 14:10
2020/02/10 00:26
2020/02/10 15:59 編集
2020/02/10 22:52
2020/02/11 02:30 編集
2020/02/11 02:38
2020/02/11 07:26 編集
2020/02/11 08:31