

#質問
今回は初挑戦でSIGNATEの練習問題である画像ラベリング(20種類)に現在挑戦しています。
今まで10回ほど投稿していきましたが、投稿するたびに暫定評価値が上がっていっている状態です。
(※今回評価値は0以上の値をとり、精度が高いほど小さな値になる)
1回目の投稿では、暫定評価が約3.8、10回目では約4.7になっています。
しかし、model lossを出力させてみると、明らかに1回目より、10回目の方がlossの値は小さくなっています。
ではなぜ、今回暫定評価はlossの値が高い1回目の方が好成績なのかがよくわかりません。
アドバイス等あればよろしくお願いいたします。
#1回目のコード
python
1import numpy as np 2import pandas as pd 3from matplotlib import pyplot as plt 4from skimage import io 5from keras import utils 6from keras.models import Sequential 7from keras.layers import Dense, Flatten, Activation 8from keras.layers import Conv2D, MaxPooling2D 9from keras import optimizers 10 11labels= pd.read_csv("train_master.tsv", sep="\t") 12master = pd.read_csv("label_master.tsv", sep="\t") 13sample = pd.read_csv("sample_submit.csv", header=None, sep=",") 14 15train_images = [] 16for fname in labels["file_name"]: 17 path = "./train/" + fname 18 img = io.imread(path) 19 train_images.append(img) 20train_images = np.array(train_images) 21print(type(train_images), train_images.shape) 22 23test_images = [] 24for fname in sample[0]: 25 path = "./test/" + fname 26 img = io.imread(path) 27 test_images.append(img) 28test_images = np.array(test_images ) 29print(type(test_images ), test_images.shape) 30 31train_images = train_images / 255 32test_images = test_images / 255 33 34y = labels["label_id"] 35 36y_categorical = utils.to_categorical(y) 37y_categorical 38 39X_con_image, X_ver_image = np.split(train_images, [40000]) 40y_con_label, y_ver_label = np.split(y_categorical, [40000]) 41 42model = Sequential() 43 44model.add(Conv2D(filters=6, kernel_size=(3,3), padding="same", input_shape=(32,32,3))) 45model.add(Activation("sigmoid")) 46model.add(MaxPooling2D(pool_size=(2,2))) 47 48model.add(Conv2D(filters=12, kernel_size=(3,3), padding="same")) 49model.add(Activation("sigmoid")) 50model.add(MaxPooling2D(pool_size=(2,2))) 51 52model.add(Flatten()) 53 54model.add(Dense(units=120)) 55model.add(Activation("sigmoid")) 56model.add(Dense(units=60)) 57model.add(Activation("sigmoid")) 58model.add(Dense(units=20)) 59model.add(Activation("softmax")) 60 61model.compile(loss="categorical_crossentropy", 62 optimizer=optimizers.SGD(lr=0.05, momentum=0.9, decay=0.0, nesterov=True)) 63 64batch_size=100 65epochs=20 66 67history = model.fit(X_con_image, y_con_label, 68 batch_size=batch_size, 69 epochs=epochs, 70 verbose=1, 71 validation_data=(X_ver_image, y_ver_label))
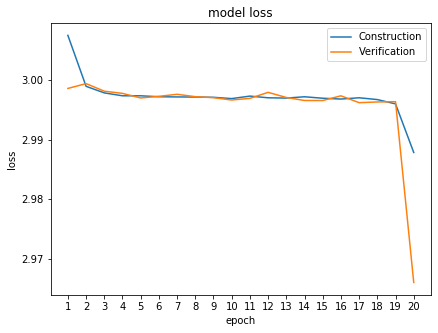
SIGNATEが出した暫定評価: 3.81172
#10回目のコード
python
1import numpy as np 2import pandas as pd 3from matplotlib import pyplot as plt 4from skimage import io 5from keras import utils 6from keras.models import Sequential 7from keras.layers import Dense, Flatten,Dropout, Activation 8from keras.layers.normalization import BatchNormalization 9from keras.layers.pooling import GlobalAveragePooling2D 10from keras.layers import Conv2D, MaxPooling2D 11from keras import optimizers 12 13labels= pd.read_csv("train_master.tsv", sep="\t") 14master = pd.read_csv("label_master.tsv", sep="\t") 15sample = pd.read_csv("sample_submit.csv", header=None, sep=",") 16 17train_images = [] 18for fname in labels["file_name"]: 19 path = "./train/" + fname 20 img = io.imread(path) 21 train_images.append(img) 22train_images = np.array(train_images) 23print(type(train_images), train_images.shape) 24 25test_images = [] 26for fname in sample[0]: 27 path = "./test/" + fname 28 img = io.imread(path) 29 test_images.append(img) 30test_images = np.array(test_images ) 31print(type(test_images ), test_images.shape) 32 33train_images = train_images / 255 34test_images = test_images / 255 35 36y = labels["label_id"] 37 38y_categorical = utils.to_categorical(y) 39y_categorical 40 41X_con_image, X_ver_image = np.split(train_images, [40000]) 42y_con_label, y_ver_label = np.split(y_categorical, [40000]) 43 44model = Sequential() 45 46model.add(Conv2D(filters=64, kernel_size=(3,3), padding="same", input_shape=(32,32,3))) 47model.add(Activation("relu")) 48model.add(BatchNormalization()) 49model.add(Dropout(0.25)) 50 51model.add(Conv2D(filters=64, kernel_size=(3,3), padding="same")) 52model.add(Activation("relu")) 53model.add(BatchNormalization()) 54model.add(Dropout(0.25)) 55 56model.add(Conv2D(filters=64, kernel_size=(3,3), padding="same")) 57model.add(Activation("relu")) 58model.add(BatchNormalization()) 59model.add(Dropout(0.25)) 60 61model.add(Conv2D(filters=64, kernel_size=(3,3), padding="same")) 62model.add(Activation("relu")) 63model.add(BatchNormalization()) 64model.add(Dropout(0.25)) 65 66model.add(Conv2D(filters=64, kernel_size=(3,3), padding="same")) 67model.add(Activation("relu")) 68model.add(BatchNormalization()) 69model.add(Dropout(0.25)) 70 71model.add(MaxPooling2D(pool_size=(2, 2))) 72model.add(GlobalAveragePooling2D()) 73 74model.add(Dense(units=20)) 75model.add(Activation("softmax")) 76 77model.compile(loss="categorical_crossentropy", 78 optimizer=optimizers.rmsprop(lr=0.0001, decay=1e-6), 79 metrics=["accuracy"]) 80 81batch_size=32 82epochs=20 83 84history = model.fit(X_con_image, y_con_label, 85 batch_size=batch_size, 86 epochs=epochs, 87 verbose=1, 88 validation_data=(X_ver_image, y_ver_label))
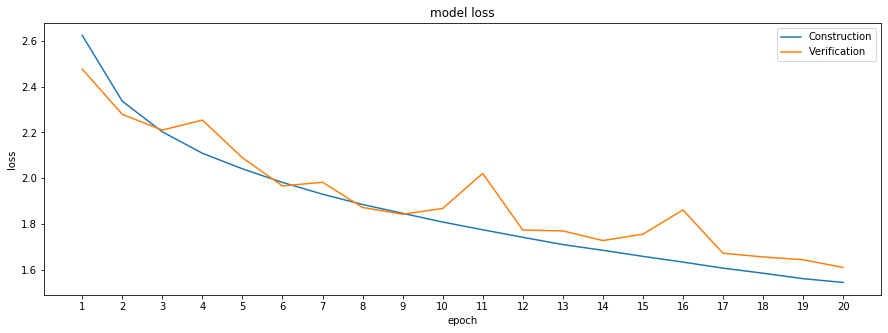
SIGNATEが出した暫定評価: 4.71691
回答1件
あなたの回答
tips
プレビュー



バッドをするには、ログインかつ
こちらの条件を満たす必要があります。
退会済みユーザー
2020/01/19 09:56